반응형
상상을 현실로 만드는, 이미지 생성 모델을 위한 엔지니어링
- 1. 김태훈 SYMBIOTE AI 상상을 현실로 만드는, 이미지 생성 모델을 위한 엔지니어링
- 2. 김태훈 (carpedm20) Devsisters 2016
- 3. 김태훈 (carpedm20) Devsisters 2016 GPT-3 2018 Reinforcement Learning Network sparsity
- 4. 김태훈 (carpedm20) Devsisters 2016 2021 2018 Generative AI for Creativity
- 5. 이미지 생성 모델
- 6. 무엇을 할 수 있는가?
- 7. https://www.facebook.com/groups/aiartuniverse/posts/740271721071398/
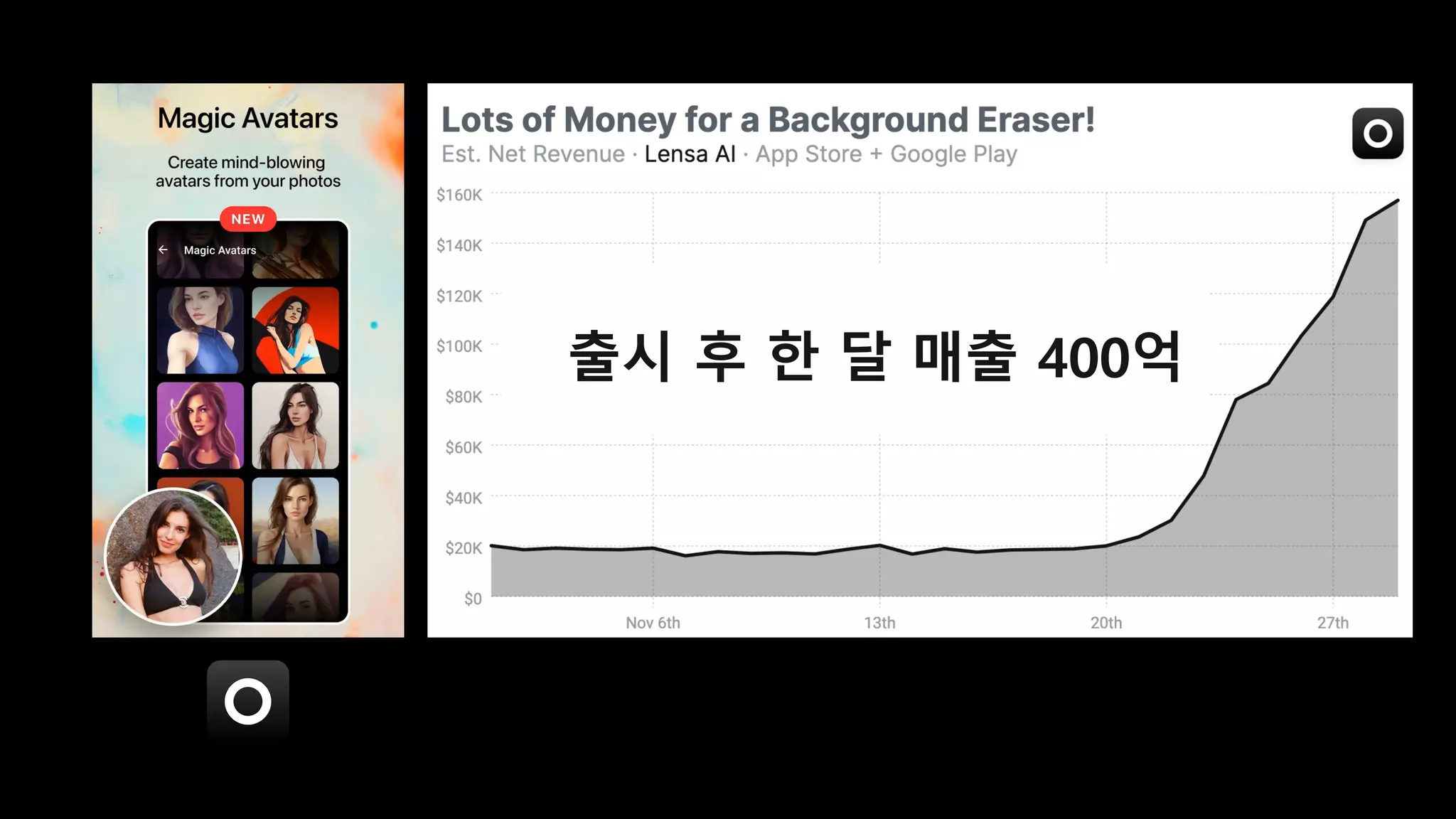
- 8. 인물 사진을 디지털 아바타로 바꿔주는 앱
- 9. 출시 후 한 달 매출 400억
- 10. 인류의 창의성 폭발을 일으키고 있는 생성 모델의 이름
- 11. Diffusion model
- 12. 1. Diffusion model은 무엇이 다른가?
- 13. Diffusion model의 정의
- 14. Multimodal Image Generation model with diffusion process Diffusion Model is
- 15. Multimodal Image Generation model with diffusion process Diffusion Model is
- 16. Multimodal Image Generation model with diffusion process Diffusion Model is
- 17. Multimodal Image Generation model with diffusion process Diffusion Model is
- 18. Image Generation model
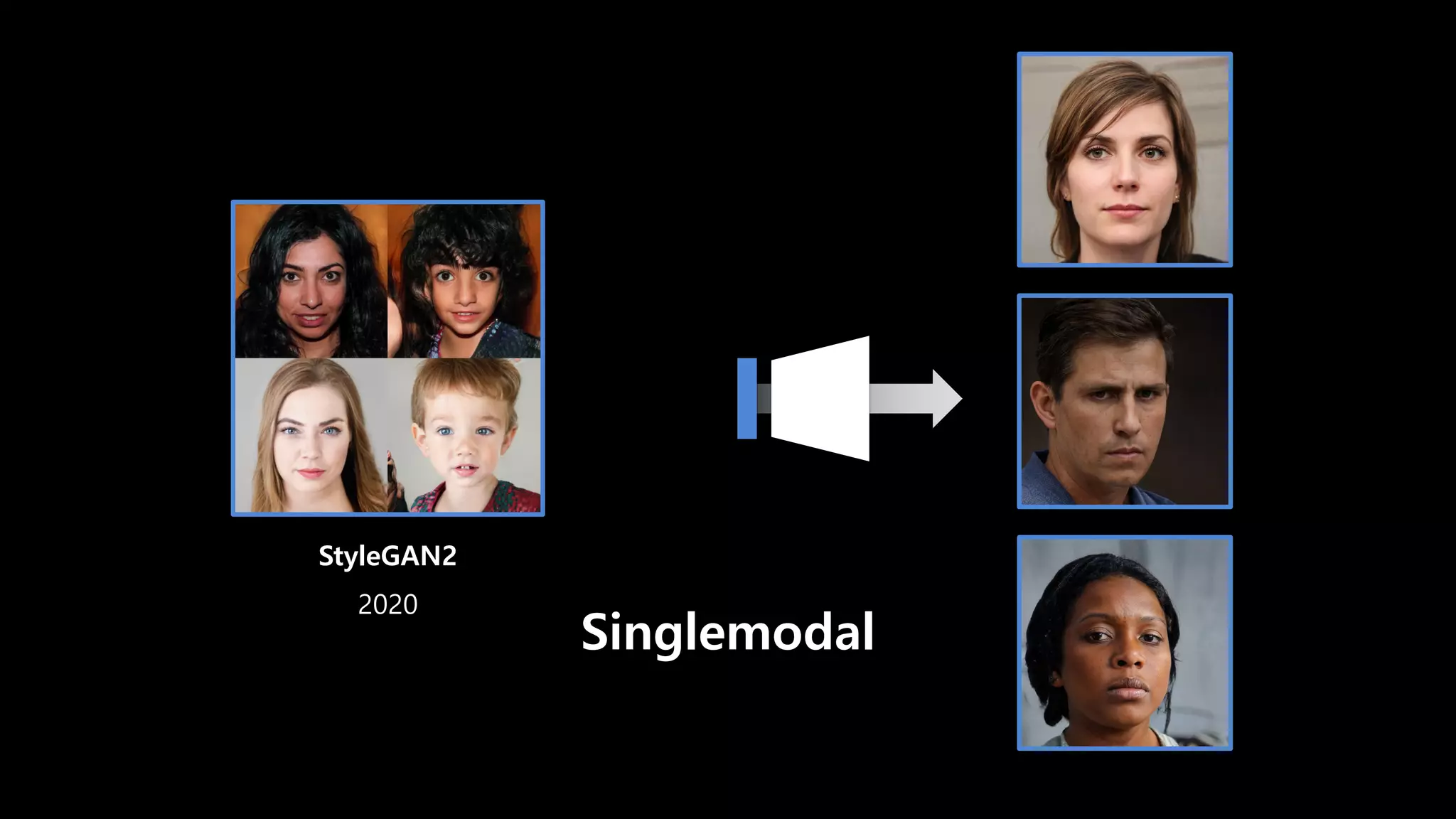
- 19. StyleGAN2 2020 DALL·E 2 2022 BigGAN 2018 Image Generation model의 역사
- 20. Multimodal Image Generation model with diffusion process Diffusion Model is
- 21. Multimodal Image Generation model with diffusion process Diffusion Model is
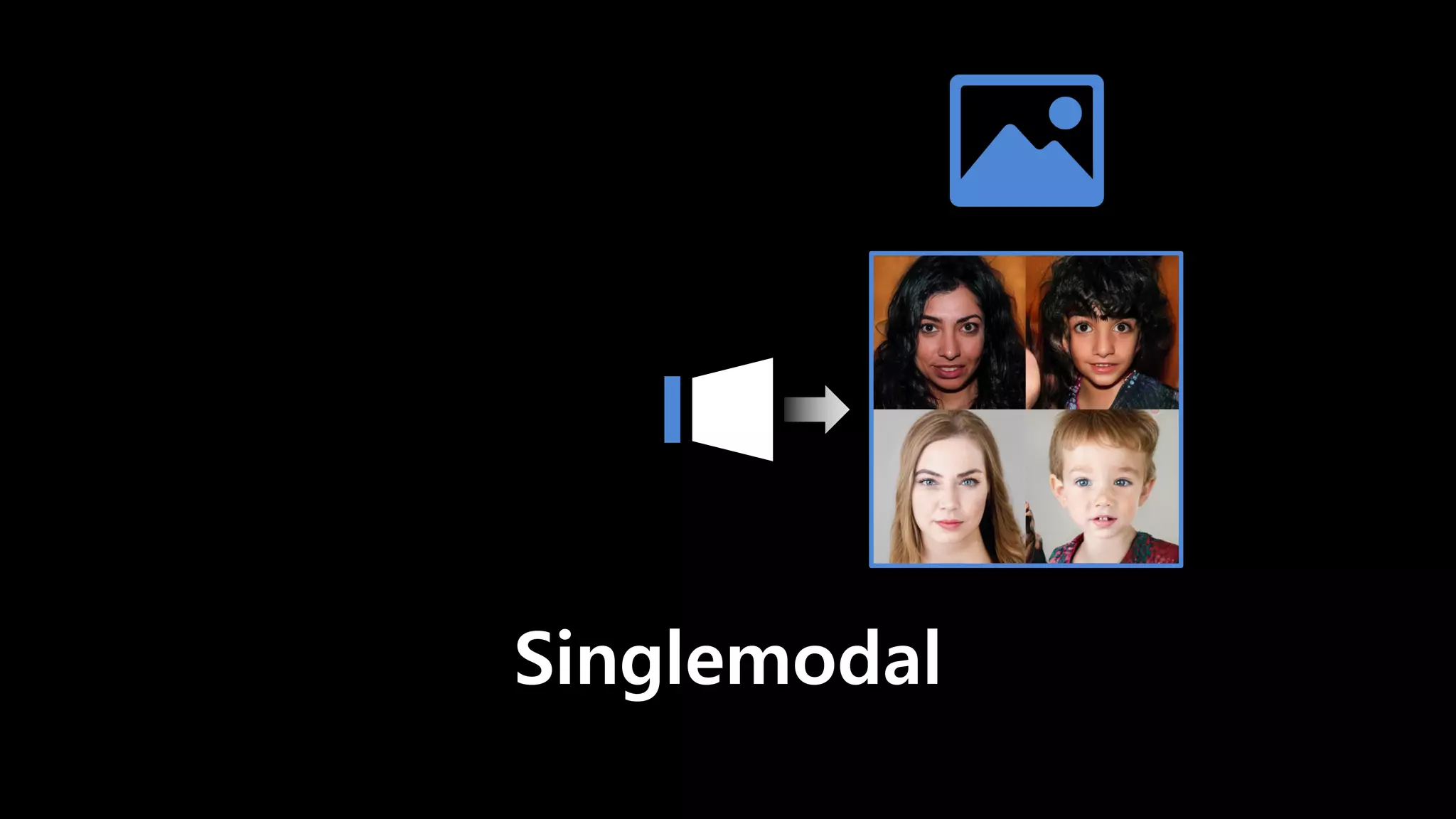
- 22. Singlemodal Multimodal
- 23. Singlemodal
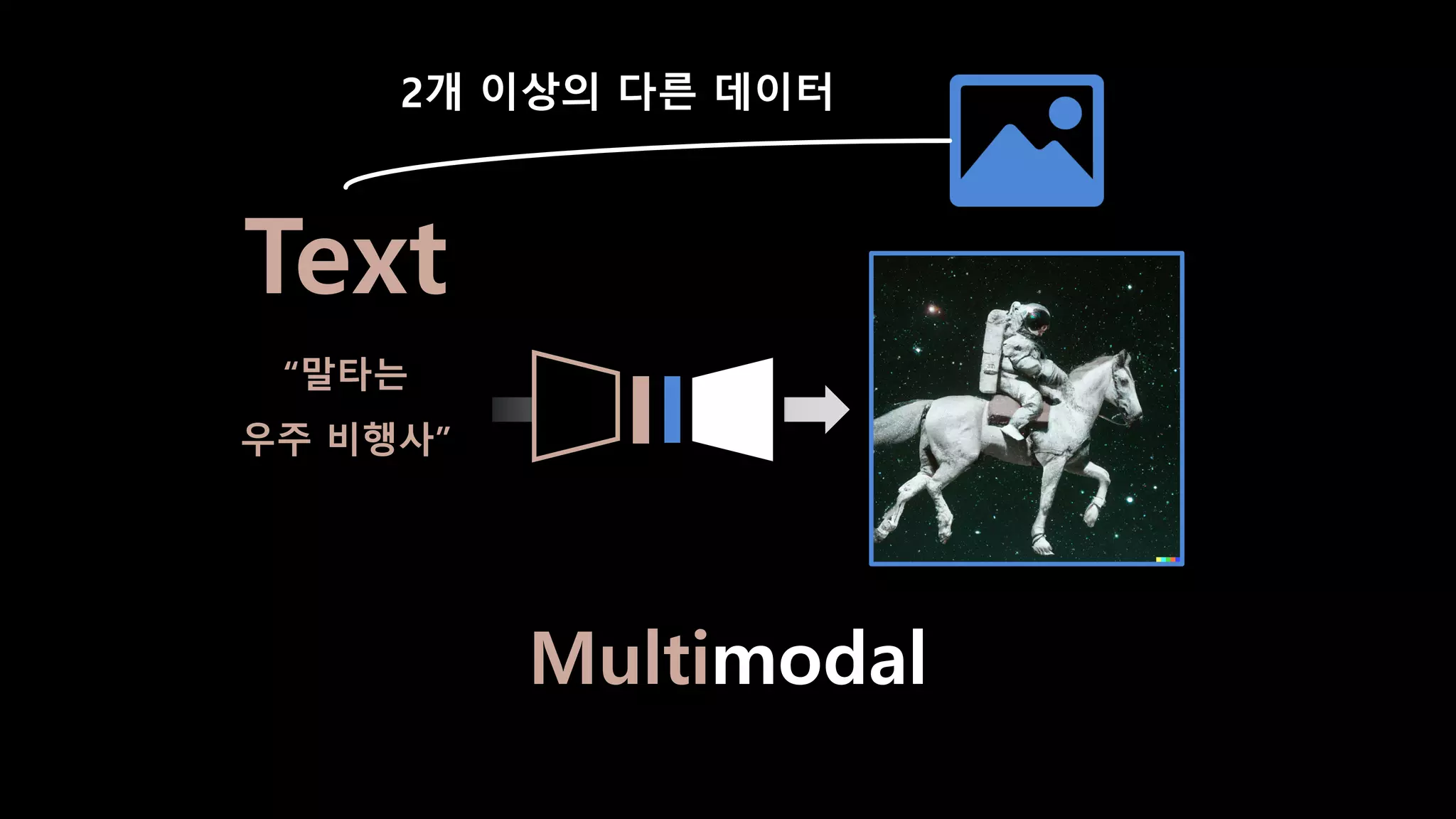
- 24. “말타는 우주 비행사” Multimodal Text 2개 이상의 다른 데이터
- 25. StyleGAN2 2020 Singlemodal
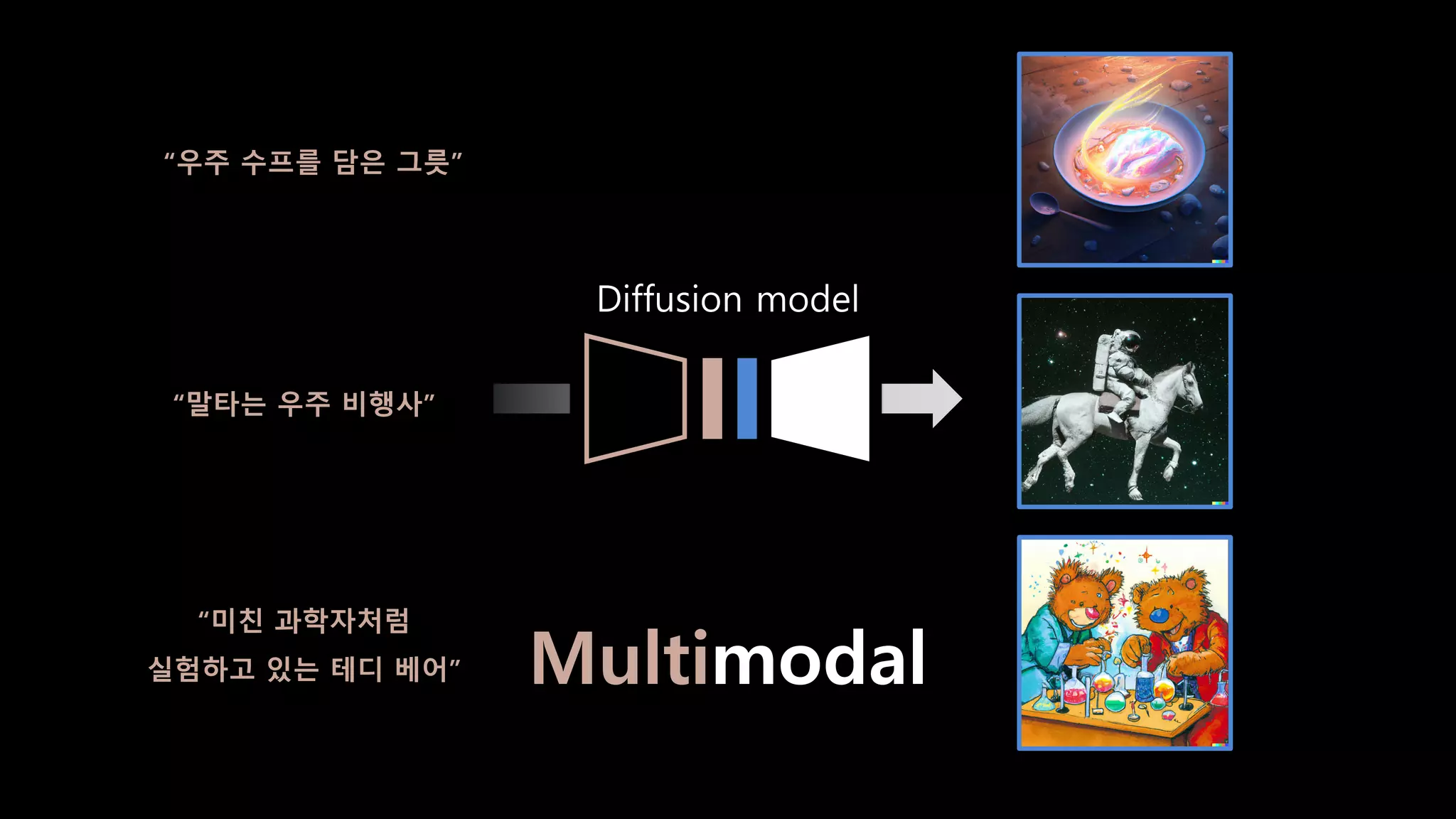
- 26. “말타는 우주 비행사” “우주 수프를 담은 그릇” “미친 과학자처럼 실험하고 있는 테디 베어” Multimodal Diffusion model
- 27. Multimodal Image Generation model with diffusion process Diffusion Model is
- 28. Multimodal Image Generation model with diffusion process Diffusion Model is
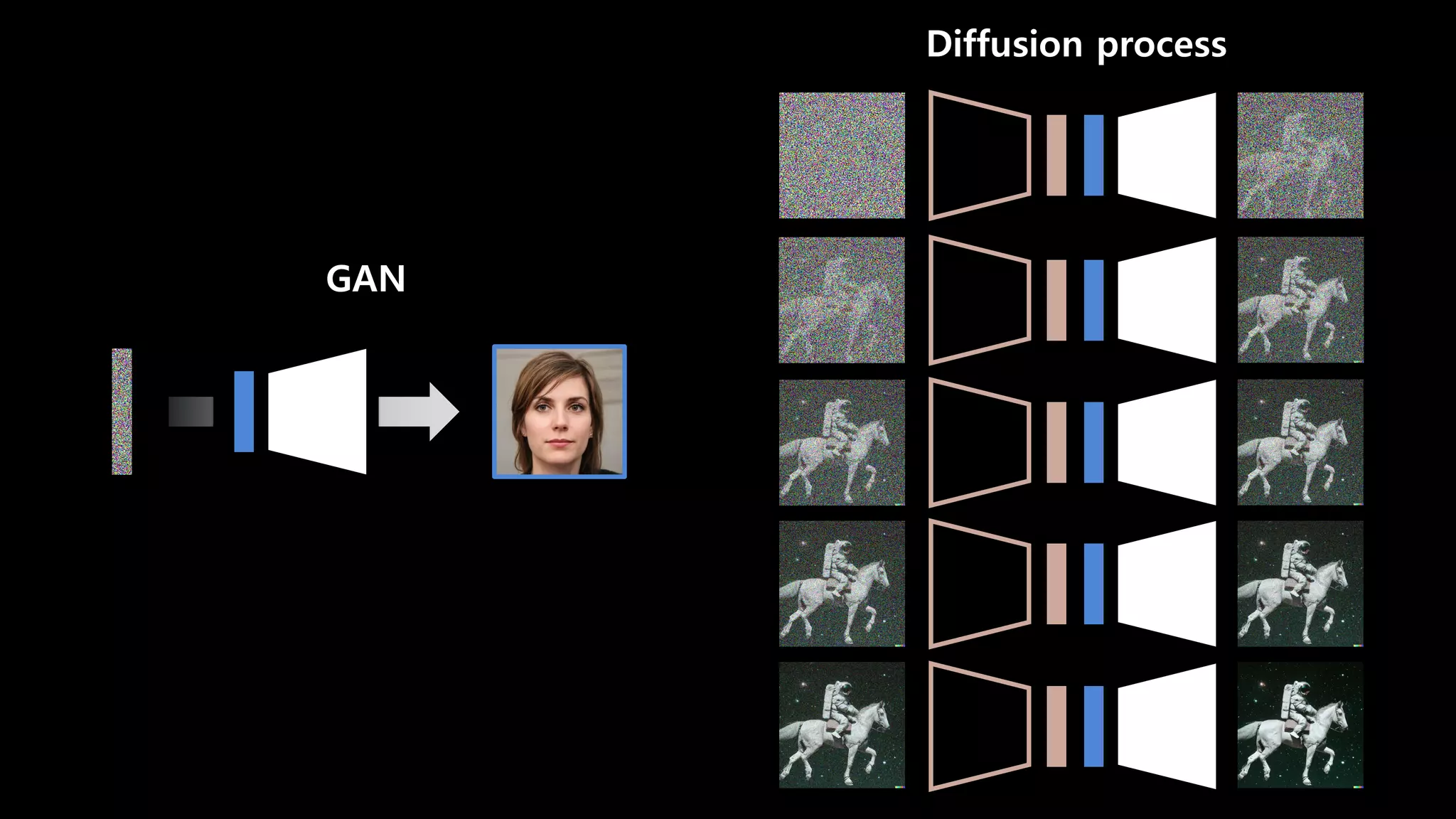
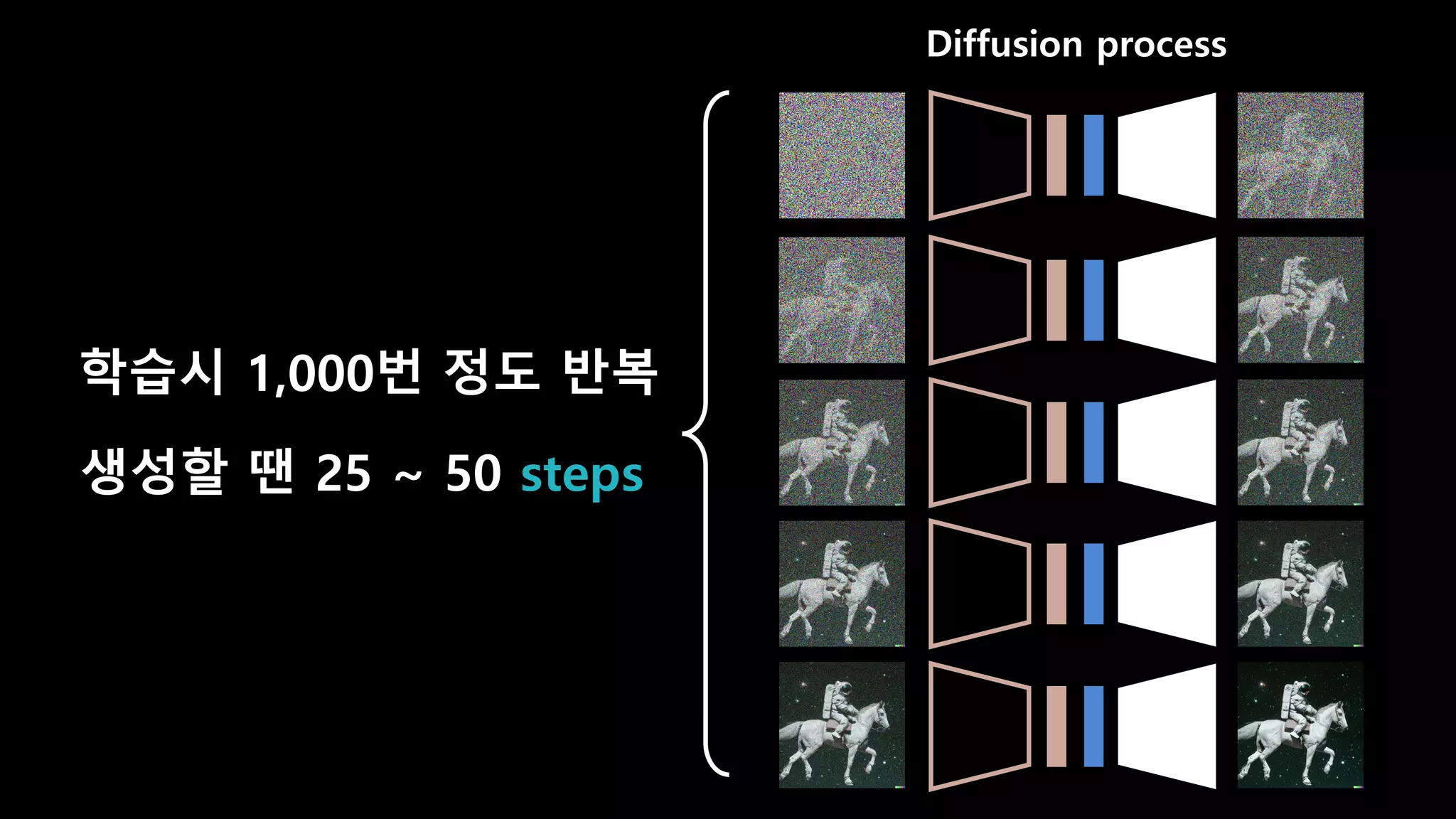
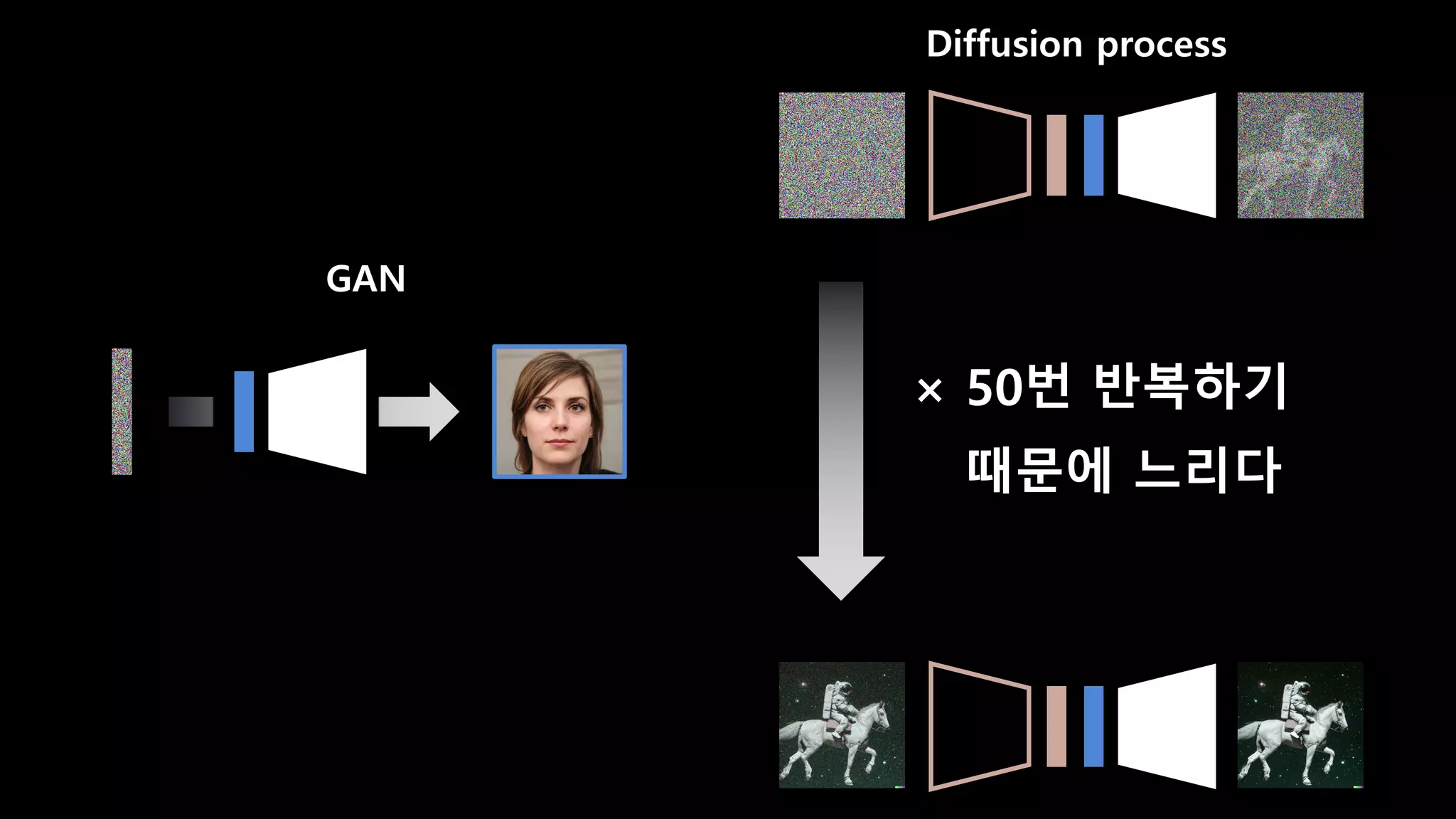
- 29. GAN Diffusion process
- 30. Diffusion process 생성할 땐 25 ~ 50 steps 학습시 1,000번 정도 반복
- 31. GAN Diffusion process × 50번 반복하기 때문에 느리다
- 32. 단점 Diffusion Model
- 33. 1. 생성이 느리다 = GPU 비용이 많이 든다
- 34. 1. 생성이 느리다 = GPU 비용이 많이 든다
- 35. 2. 학습에 리소스가 많이 든다 = GPU 비용이 많이 든다
- 36. 2. 학습에 리소스가 많이 든다 = GPU 비용이 많이 든다
- 37. 2. 학습에 리소스가 많이 든다 = GPU 비용이 많이 든다
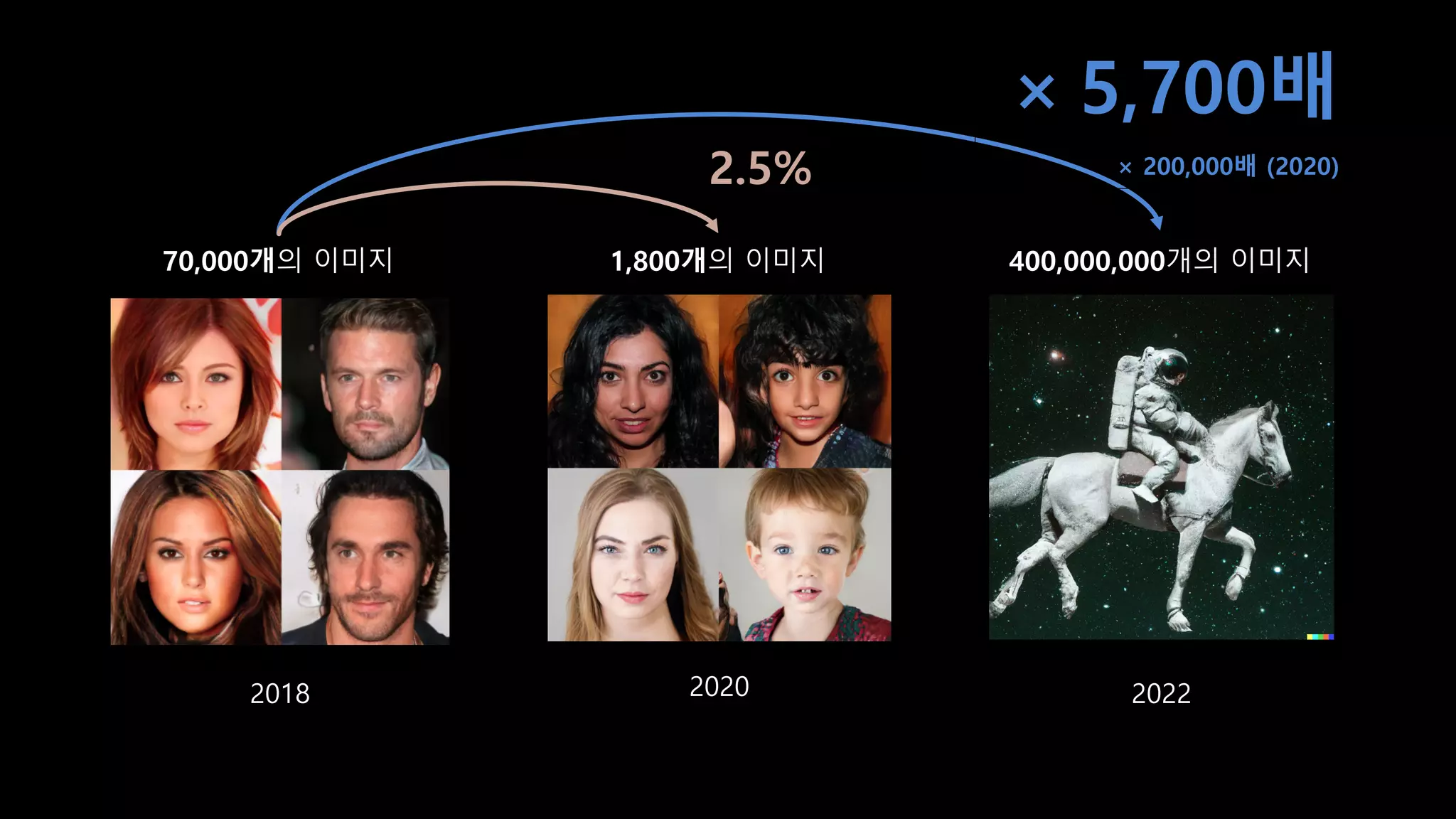
- 38. 2020 2022 2018 × 5,700배 × 200,000배 (2020) 70,000개의 이미지 2.5% 1,800개의 이미지 400,000,000개의 이미지
- 39. 세상에 공짜 점심은 없다 No free lunch
- 40. 그래서
- 41. Multimodal Image Generation model with diffusion process Diffusion Model is
- 42. Multimodal Image Generation model with diffusion process Diffusion Model is
- 43. Multimodal Image Generation model with diffusion process Diffusion Model is
- 44. 좋지만 비싼 Diffusion
- 45. 어떻게 효율적으로 운용할 수 있을까?
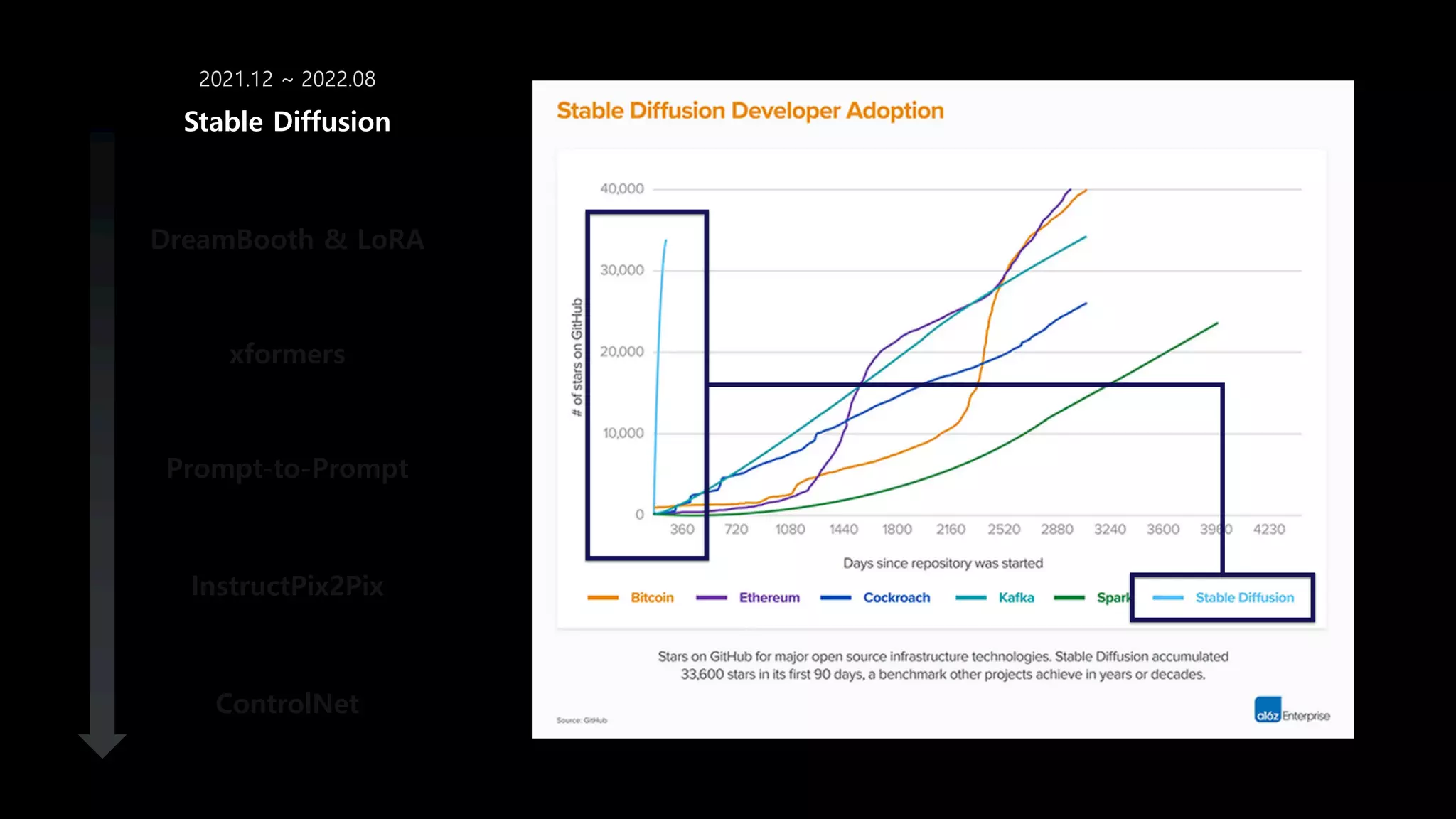
- 46. 먼저 Diffusion model은 그동안 어떻게 발전해 왔는가? = 그 비용이 줄어왔는가?
- 47. 지난 6개월 간의 발전 DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion
- 48. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 몇몇 연구자들 사이에서 Diffusion model이 엄청 좋아졌고 몇 억 정도면 만들 수 있겠다는 생각을 하게 되었다
- 49. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 몇몇 연구자들 사이에서 Diffusion model이 엄청 좋아졌고 몇 억 정도면 만들 수 있겠다는 생각을 하게 되었다
- 50. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 LAION
- 51. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 150,000 A100 GPU Hours = $600,000
- 52. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08
- 53. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08
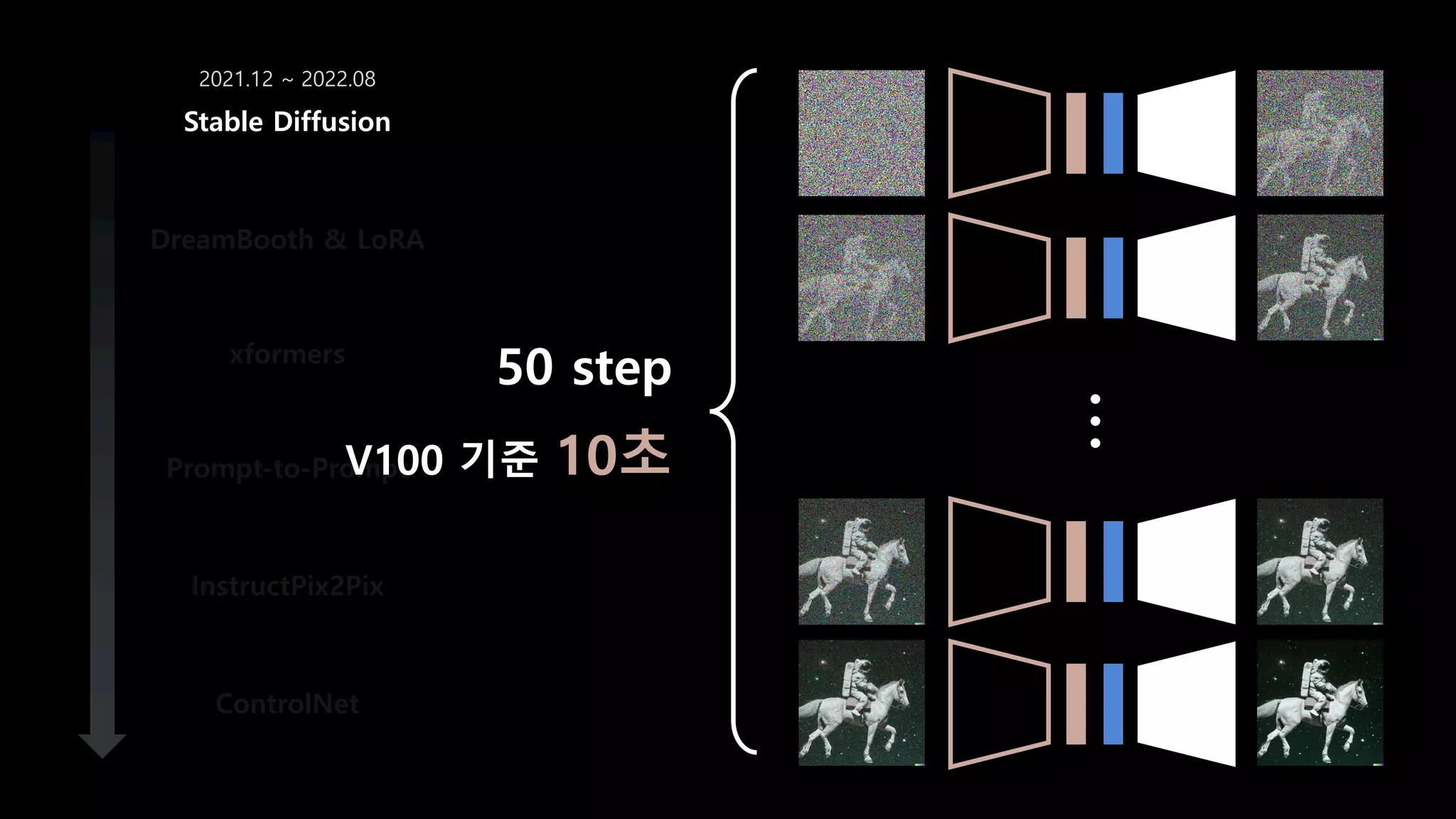
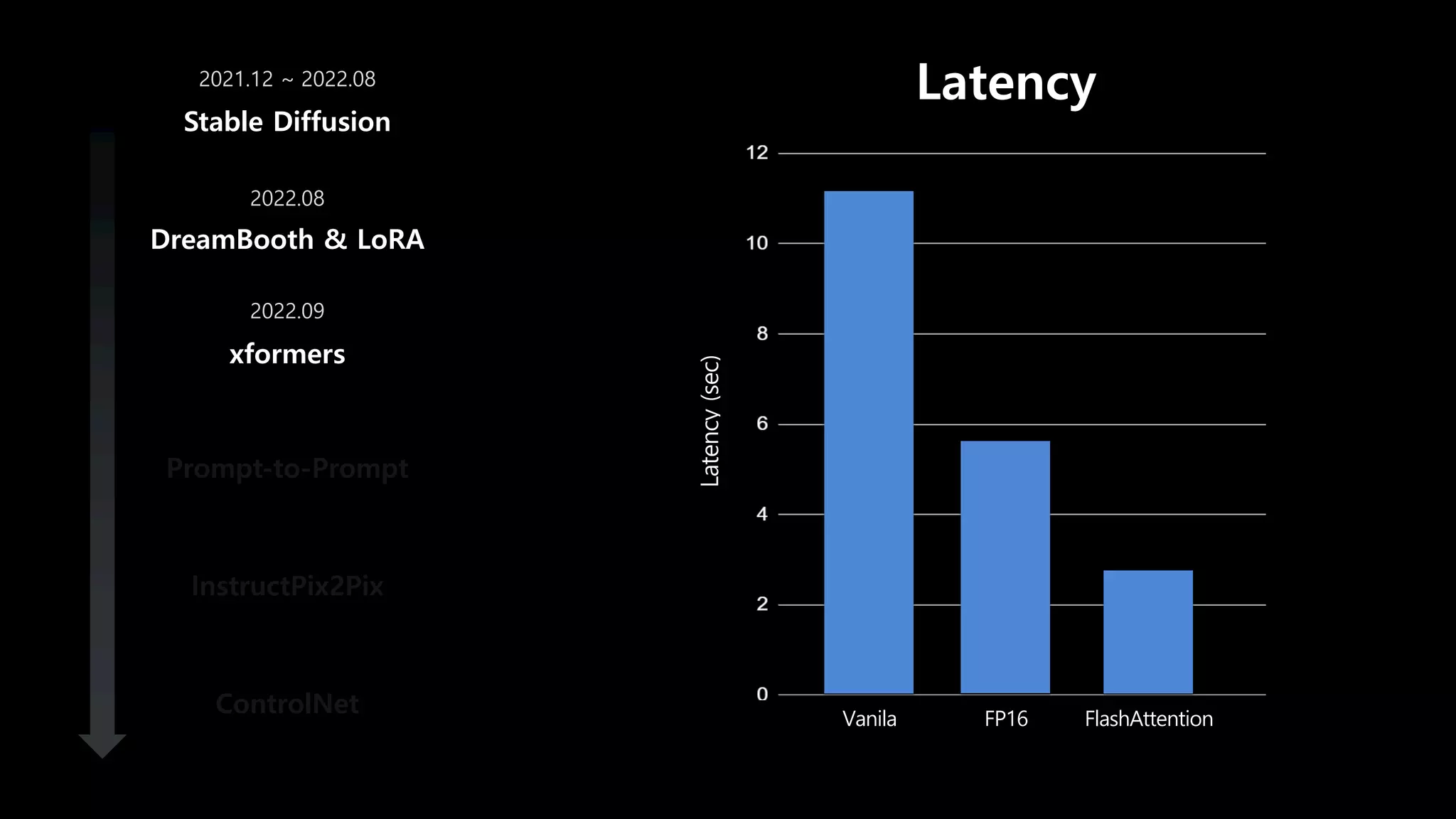
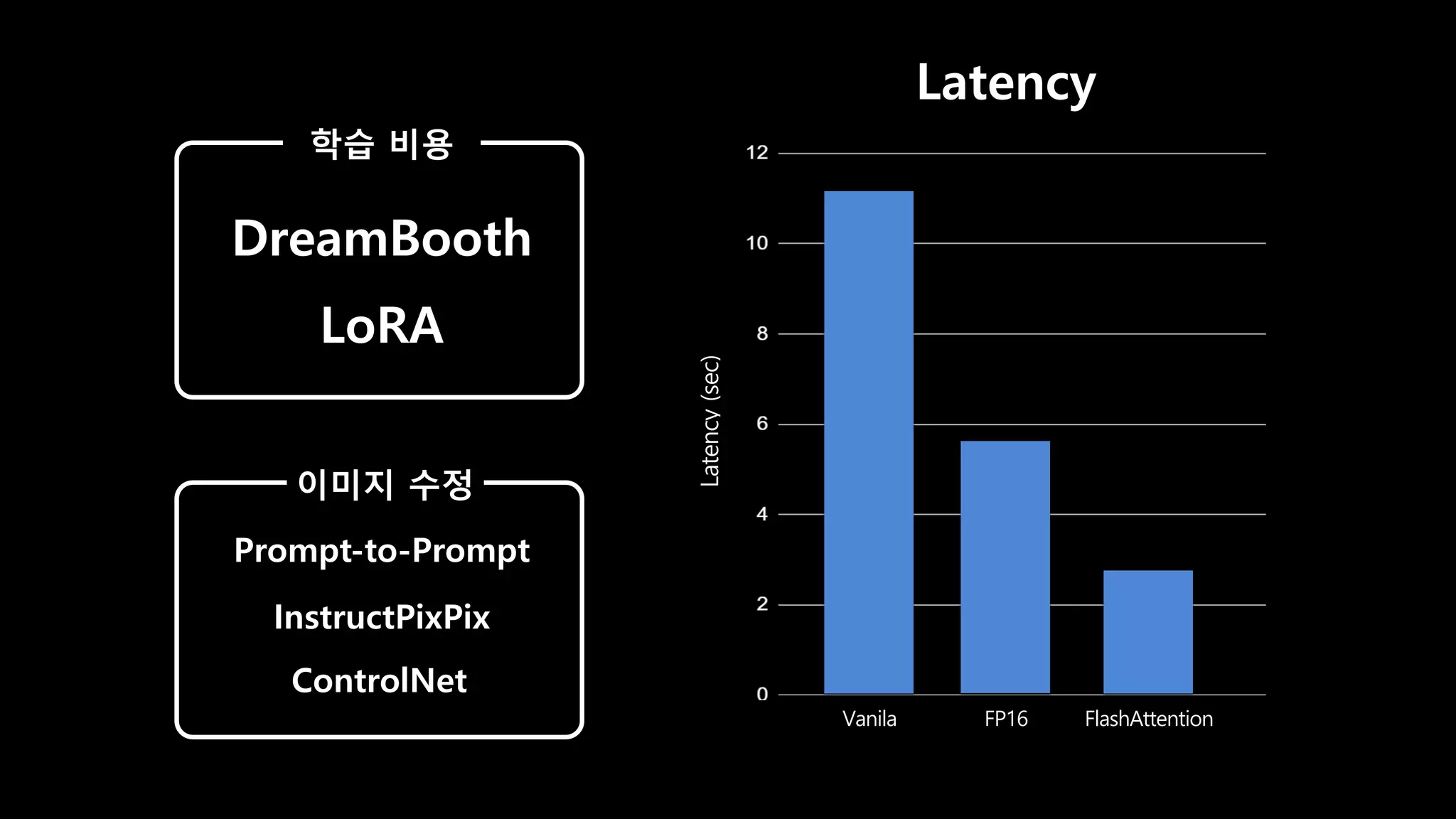
- 54. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 50 step V100 기준 10초
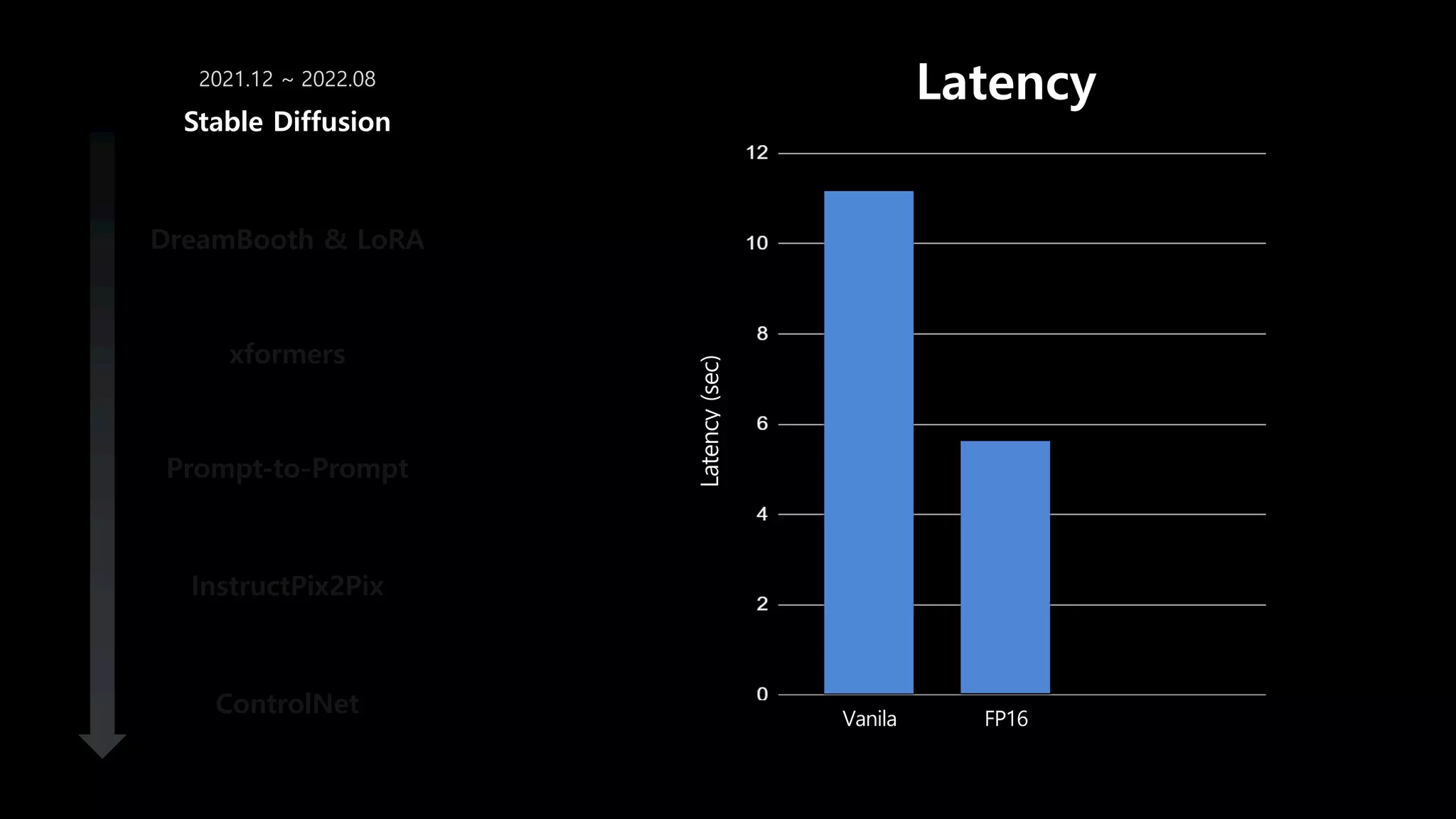
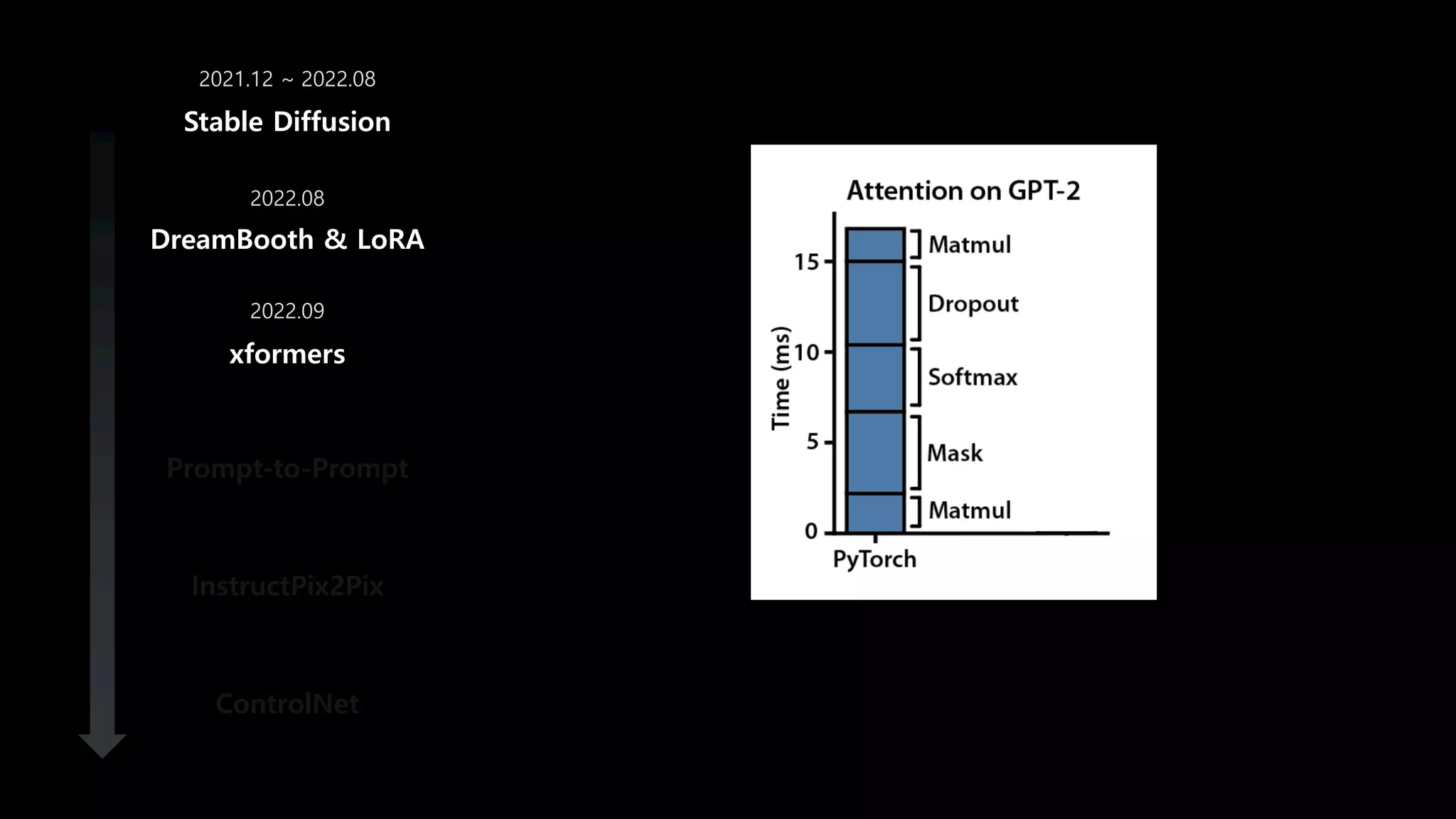
- 55. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 Latency (sec) Latency Vanila FP16
- 56. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08
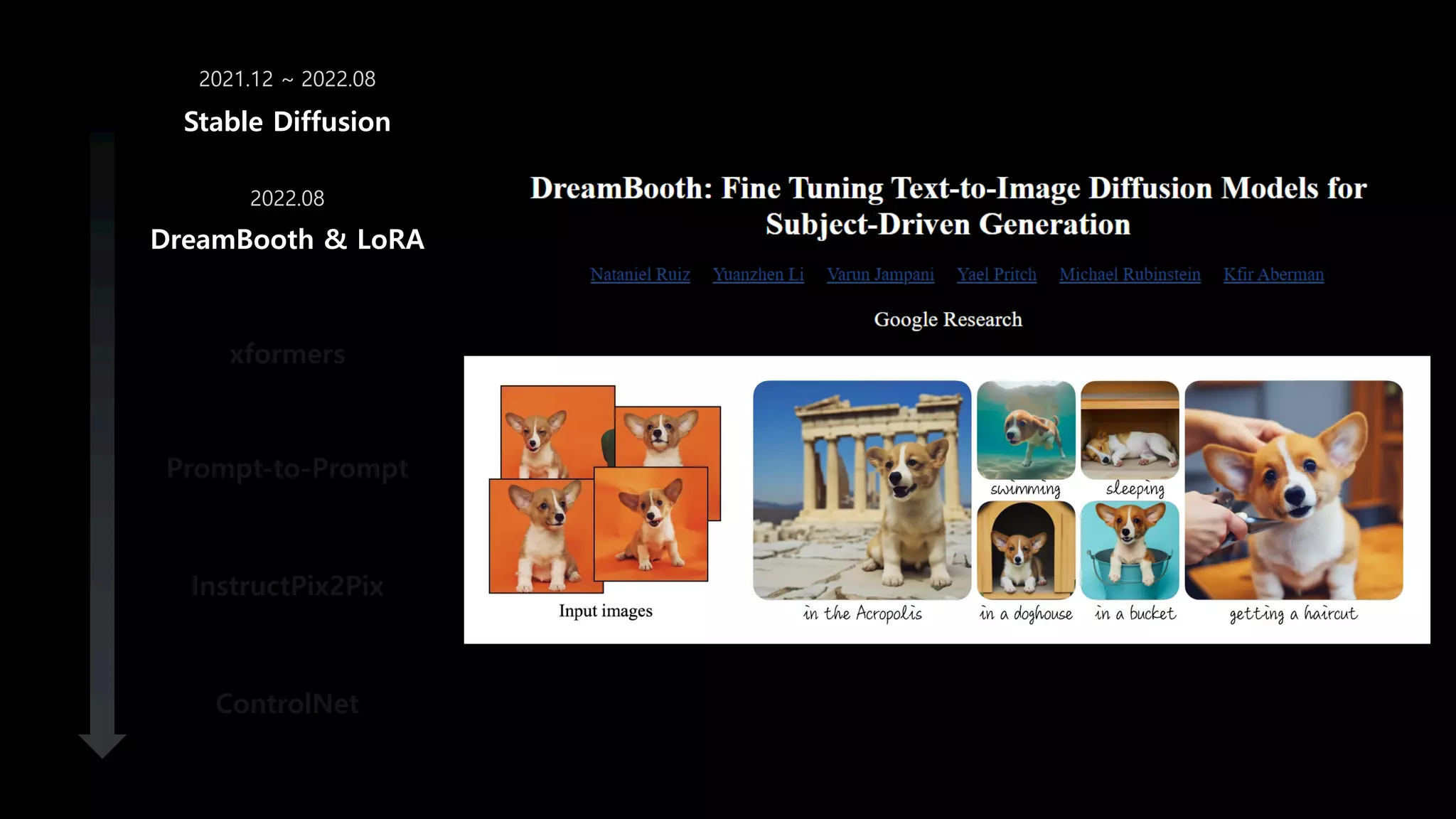
- 57. 4억 개의 이미지 없이도 새로운 모델을 학습할 수 있을까? DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08
- 58. 5 ~ 20개의 학습 이미지 “로마에 간 강아지X” “머리 깎는 강아지X” DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 “강아지X”
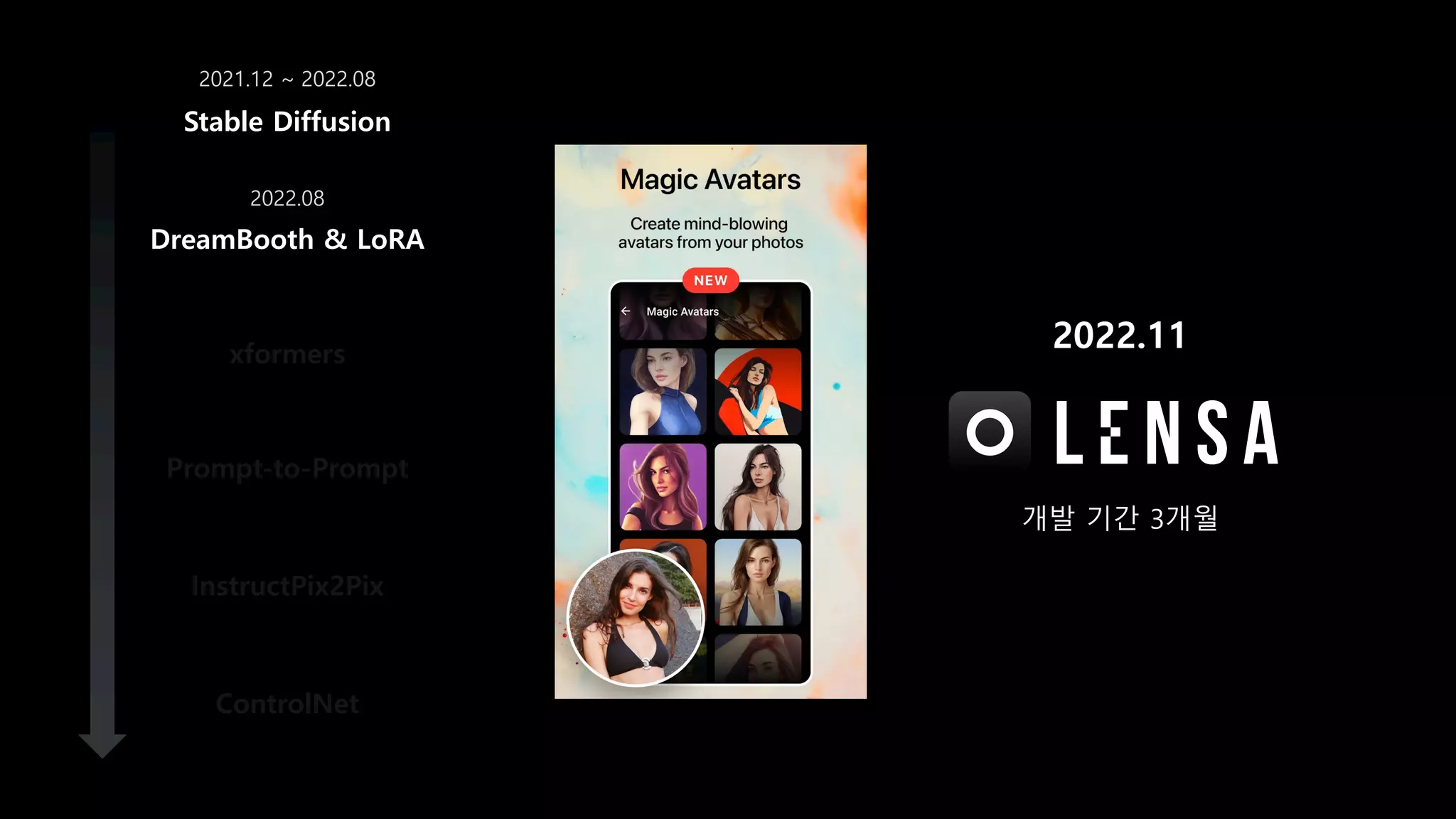
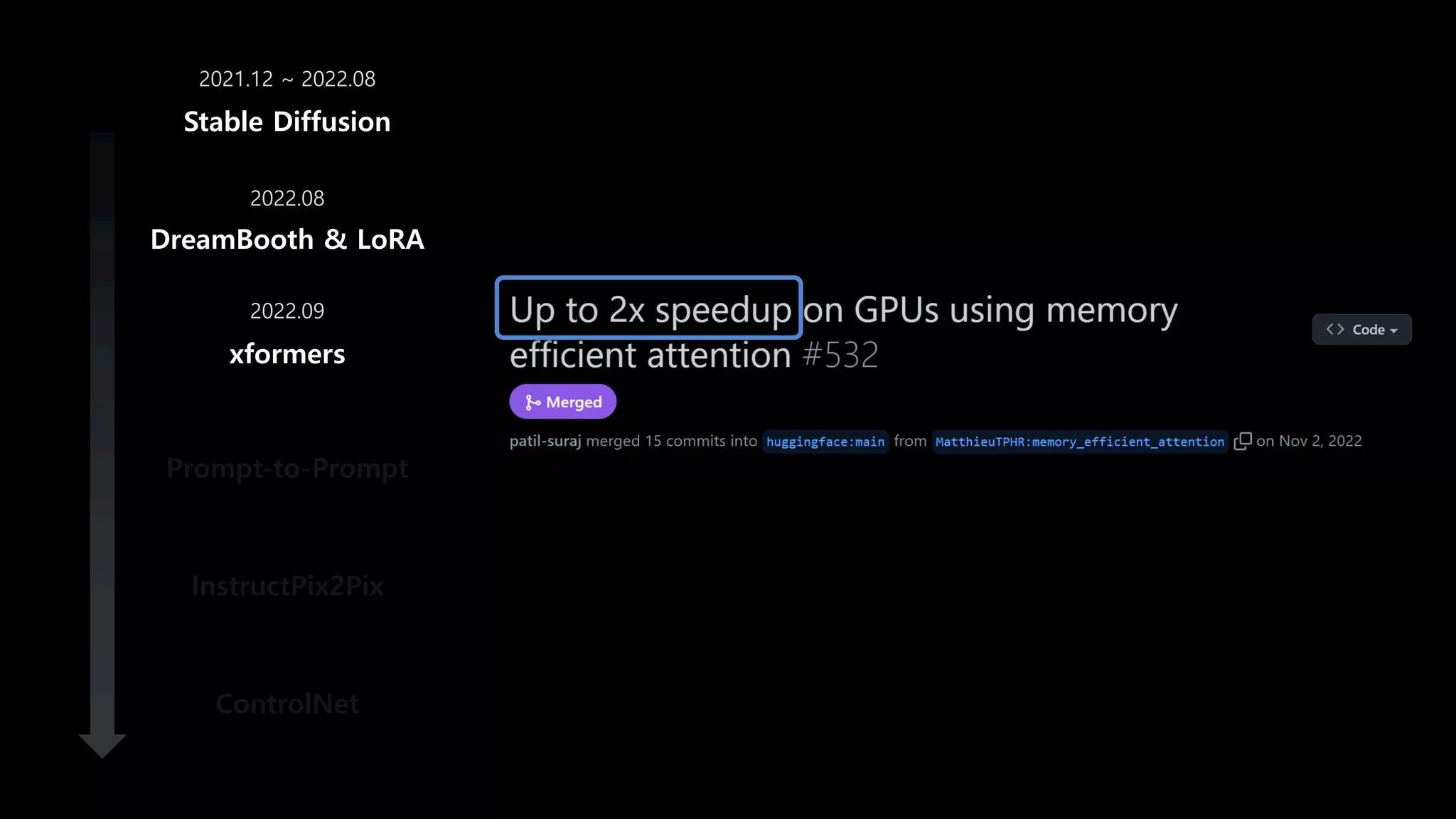
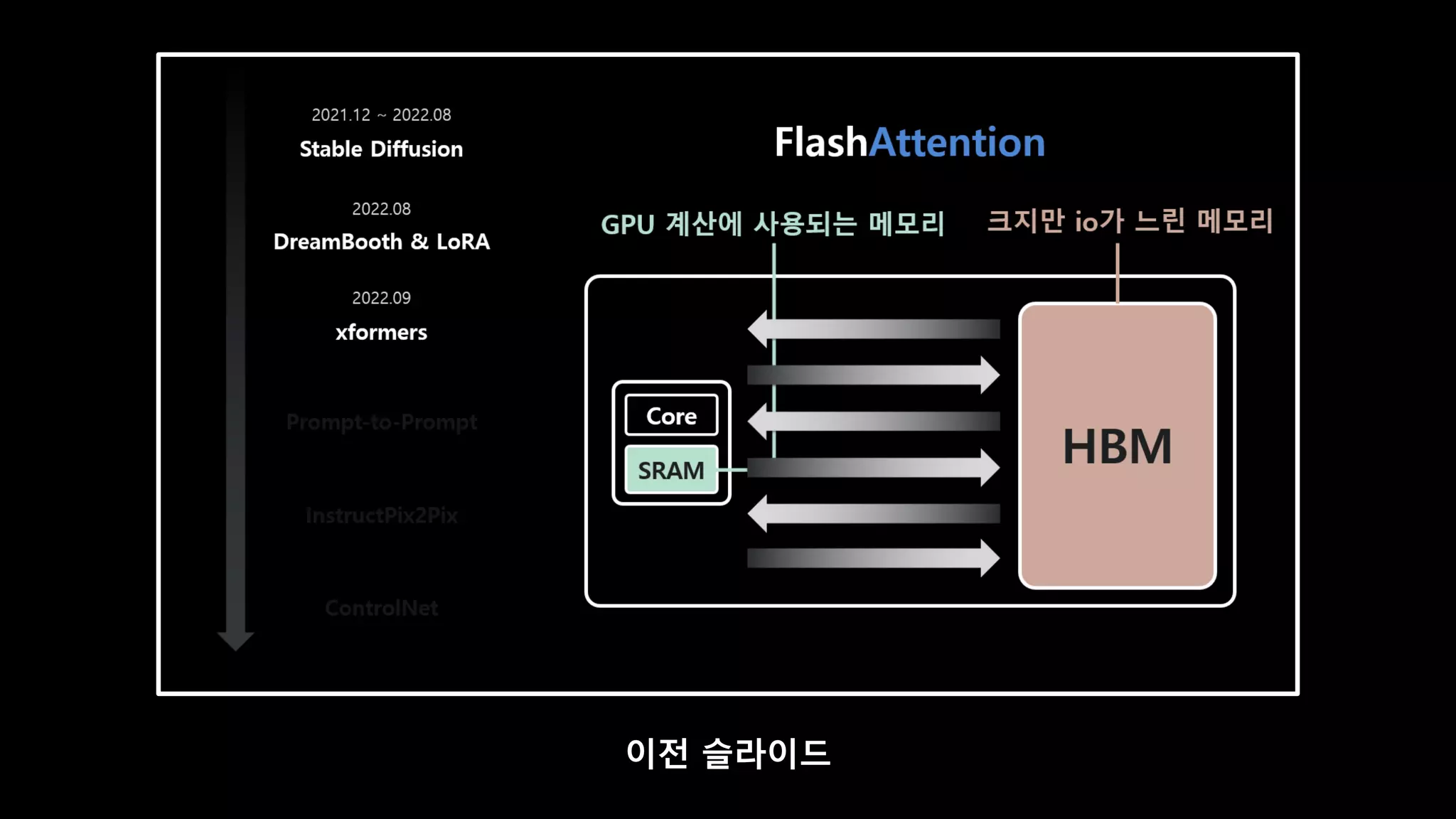
- 59. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.11 개발 기간 3개월
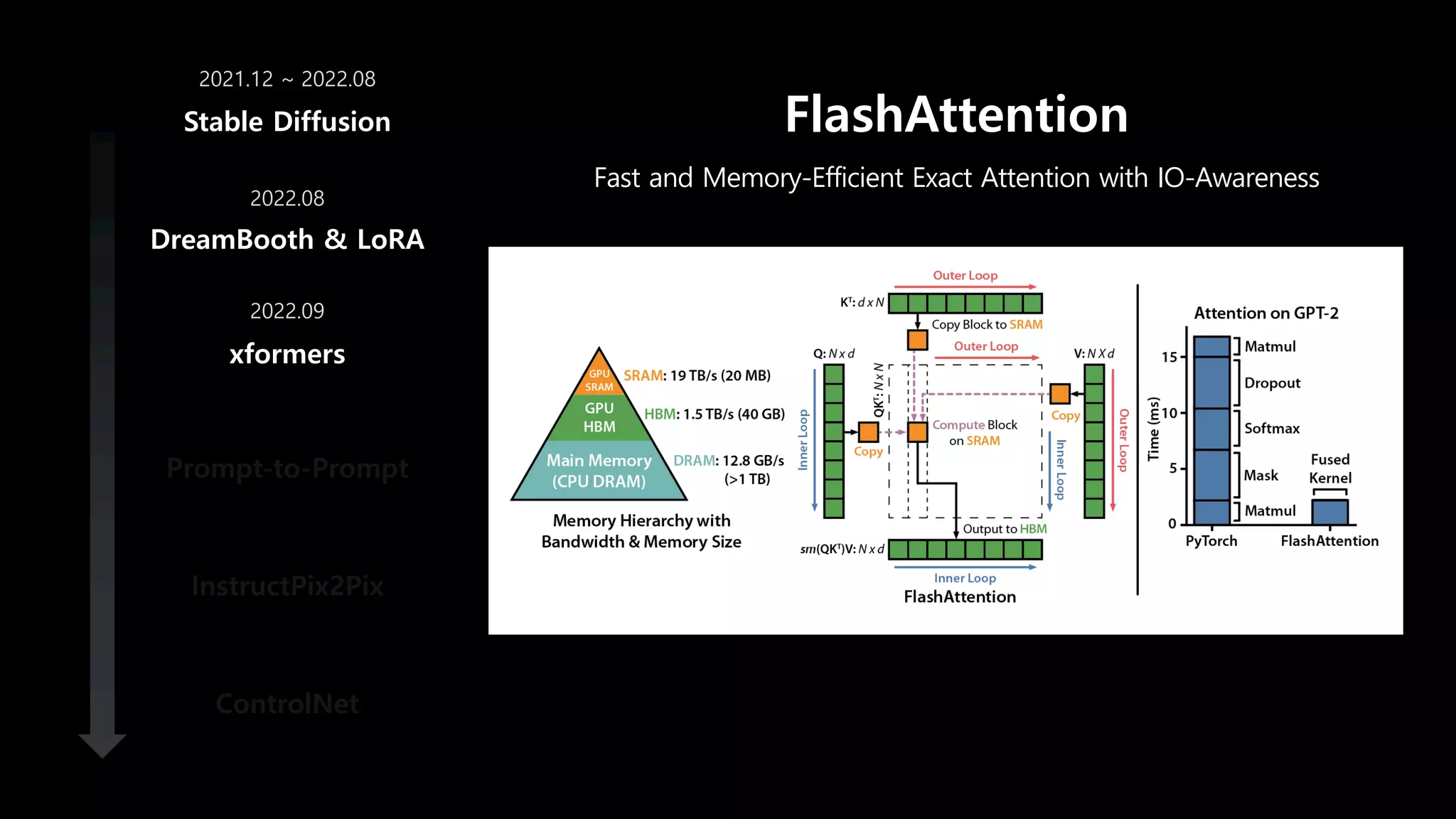
- 60. FlashAttention Fast and Memory-Efficient Exact Attention with IO-Awareness DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09
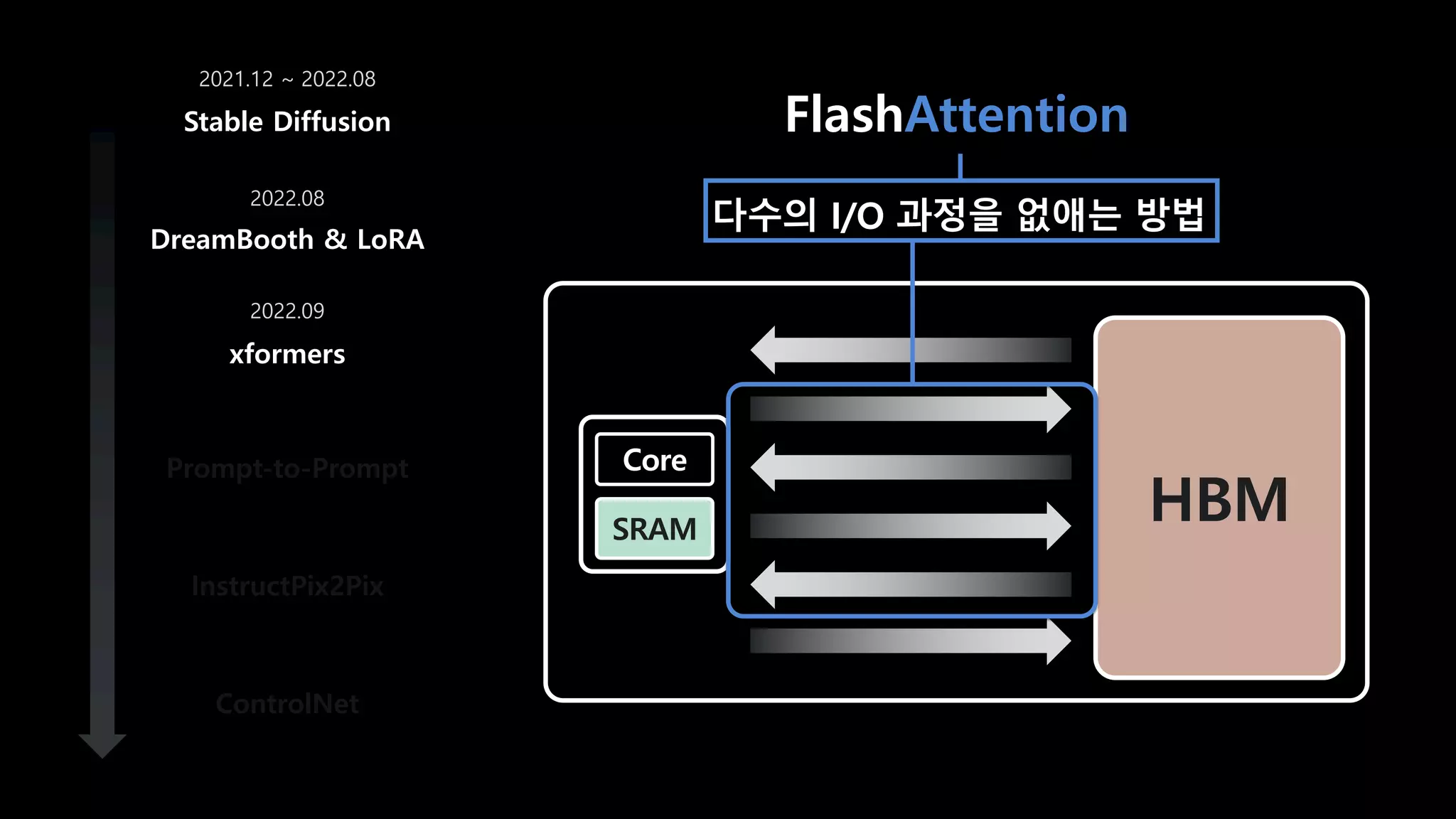
- 61. FlashAttention DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 GPU Core 크지만 io가 느린 메모리 HBM 20GB GPU 계산에 사용되는 메모리 SRAM 20MB
- 62. HBM Core SRAM FlashAttention DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 다수의 I/O 과정을 없애는 방법
- 63. HBM Core SRAM FlashAttention DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09
- 64. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09
- 65. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09
- 66. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 Latency (sec) Latency Vanila FlashAttention FP16
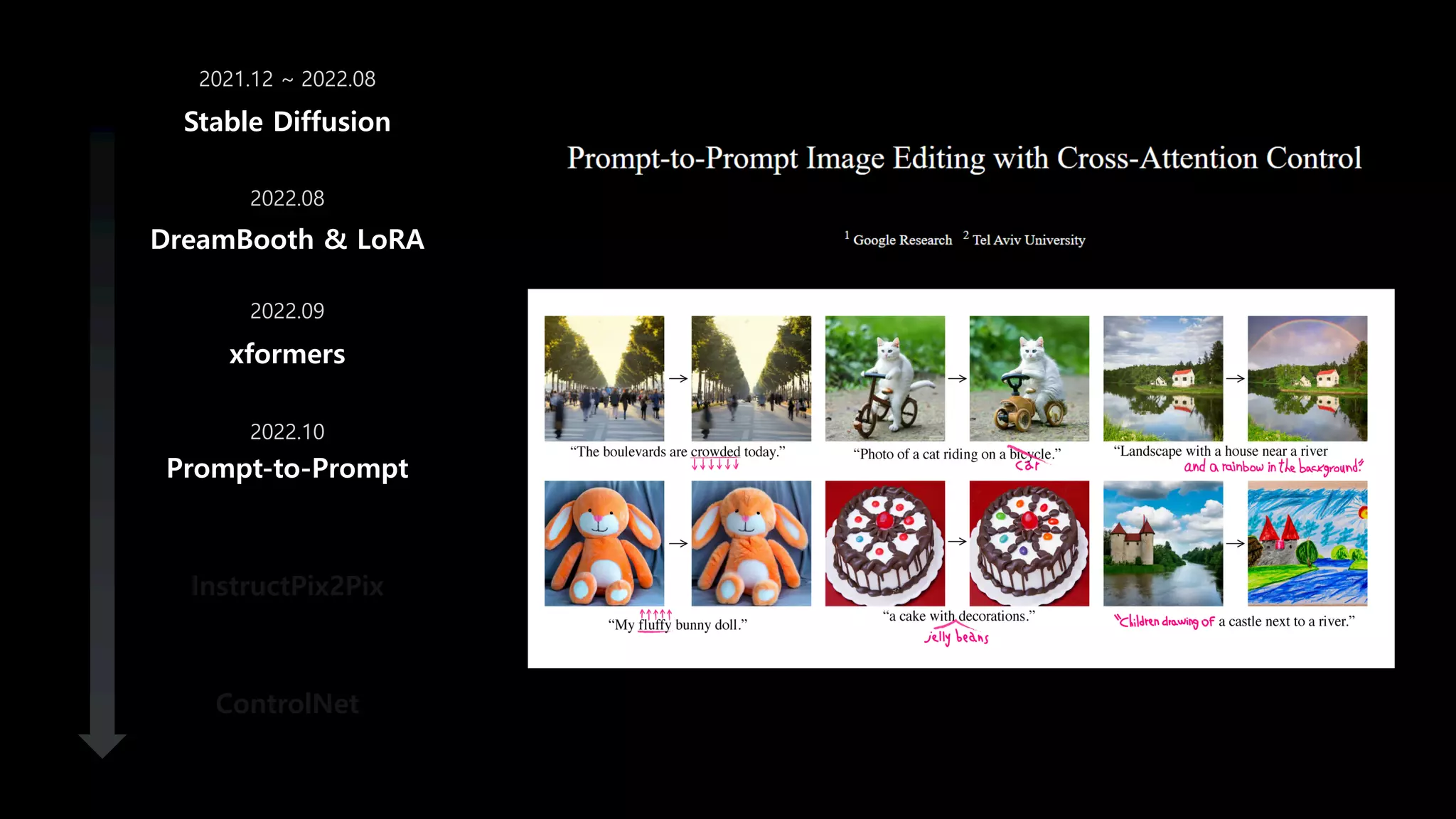
- 67. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10
- 68. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10 Prompt-to-Prompt Image Editing with Cross-Attention Control “… 금발의 아이” “… 눈을 감는 아이” “소파에 누워있는 노란 옷을 입은 아이” “소파에 누워있는 아이”
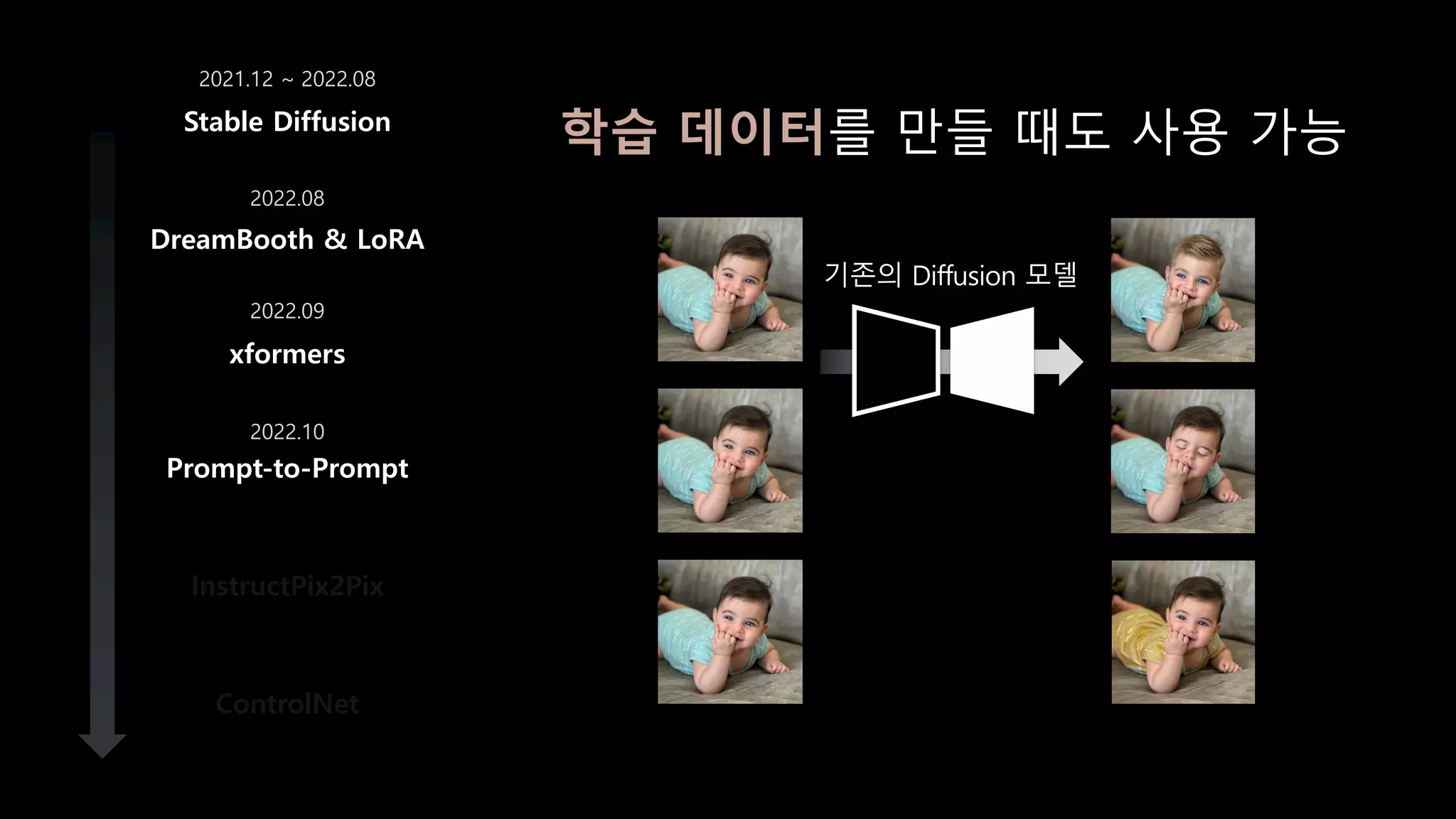
- 69. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10 학습 데이터를 만들 때도 사용 가능 기존의 Diffusion 모델
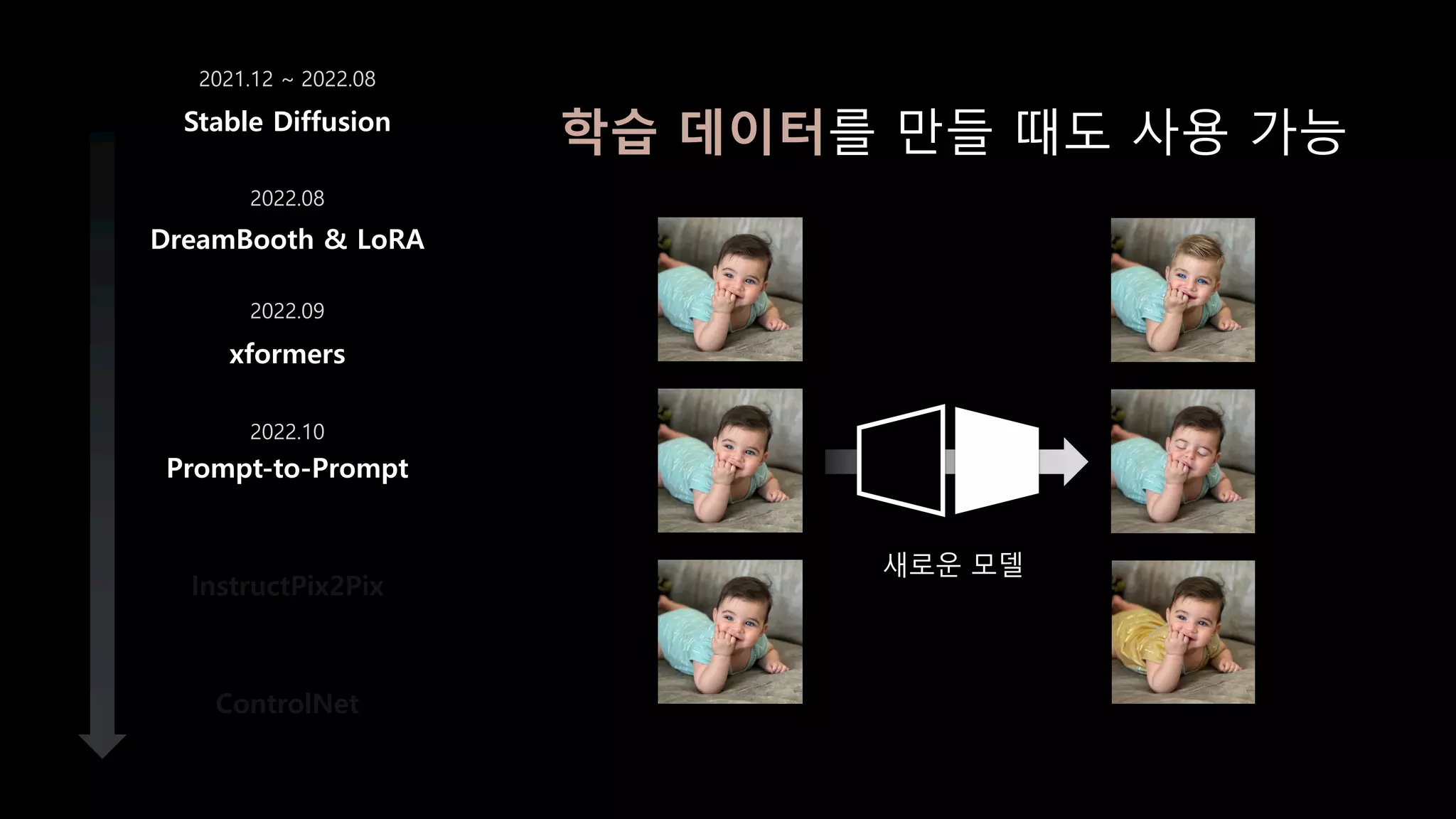
- 70. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10 학습 데이터를 만들 때도 사용 가능 새로운 모델
- 71. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10 2022.12 InstructPix2Pix Learning to Follow Image Editing Instructions
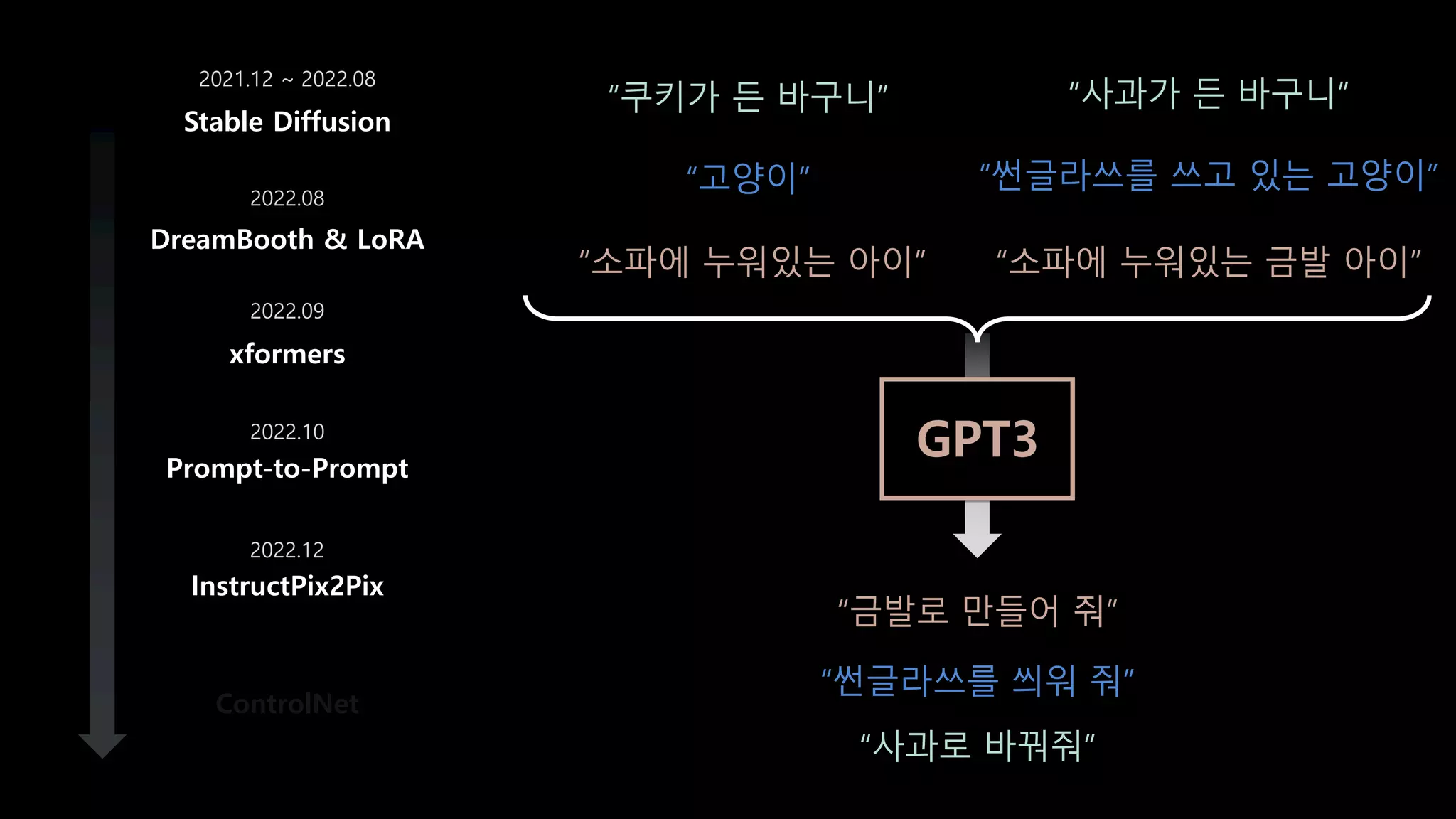
- 72. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10 2022.12 “소파에 누워있는 아이” “소파에 누워있는 금발 아이” GPT와 대화하 듯 “금발로 만들어 줘” 라는 명령어로 수정하려면?
- 73. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10 2022.12 “금발로 만들어 줘” GPT3 “소파에 누워있는 아이” “소파에 누워있는 금발 아이” “고양이” “썬글라쓰를 쓰고 있는 고양이” “썬글라쓰를 씌워 줘” “쿠키가 든 바구니” “사과가 든 바구니” “사과로 바꿔줘”
- 74. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10 2022.12 Prompt-to-Prompt로 데이터 “금발로 만들어 줘” “서부 영화로 만들어 줘” GPT-3로 만든 데이터
- 75. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10 2022.12 “금발로 만들어 줘” “서부 영화로 만들어 줘” 기존의 Diffusion 모델을 재학습
- 76. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10 2022.12 “서부 영화로 만들어 줘“ 대화형 수정 AI를 만들 수 있다 InstructPix2Pix
- 77. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10 2022.12 2022.02 ControlNet Adding Conditional Control to Text-to-Image Diffusion Models
- 78. DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10 2022.12 2022.02 기존의 방식과 다른점? 텍스트가 아닌 이미지로 생성과 수정을 할 수 있는 방식
- 79. Latency (sec) Latency Vanila FlashAttention FP16 학습 비용 DreamBooth LoRA 이미지 수정 Prompt-to-Prompt InstructPixPix ControlNet
- 80. 고작 6개월 만에 일어난 일 DreamBooth & LoRA xformers Prompt-to-Prompt InstructPix2Pix ControlNet Stable Diffusion 2021.12 ~ 2022.08 2022.08 2022.09 2022.10 2022.12 2022.02
- 81. 우리는 어떻게 비용을 줄였는가?
- 82. 비용은
- 83. 서비스 형태에 따라 다르다
- 84. 저희가 만들었던 서비스
- 85. https://www.youtube.com/watch?v=vK68waYSIGk
- 86. 생성 = 핵심 컨텐츠
- 87. 생성 = 핵심 컨텐츠
- 88. Latency와 Scalability가 중요
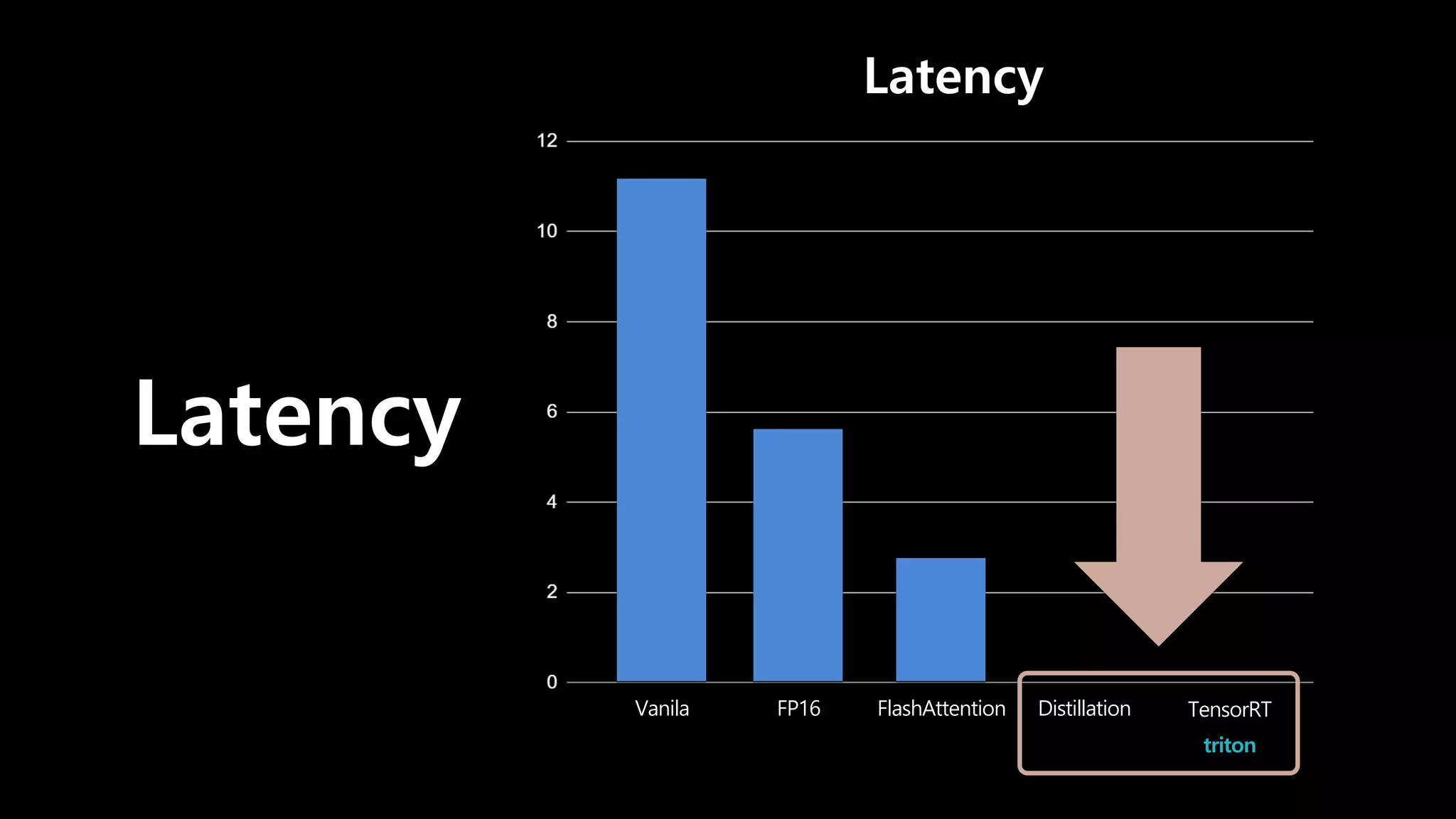
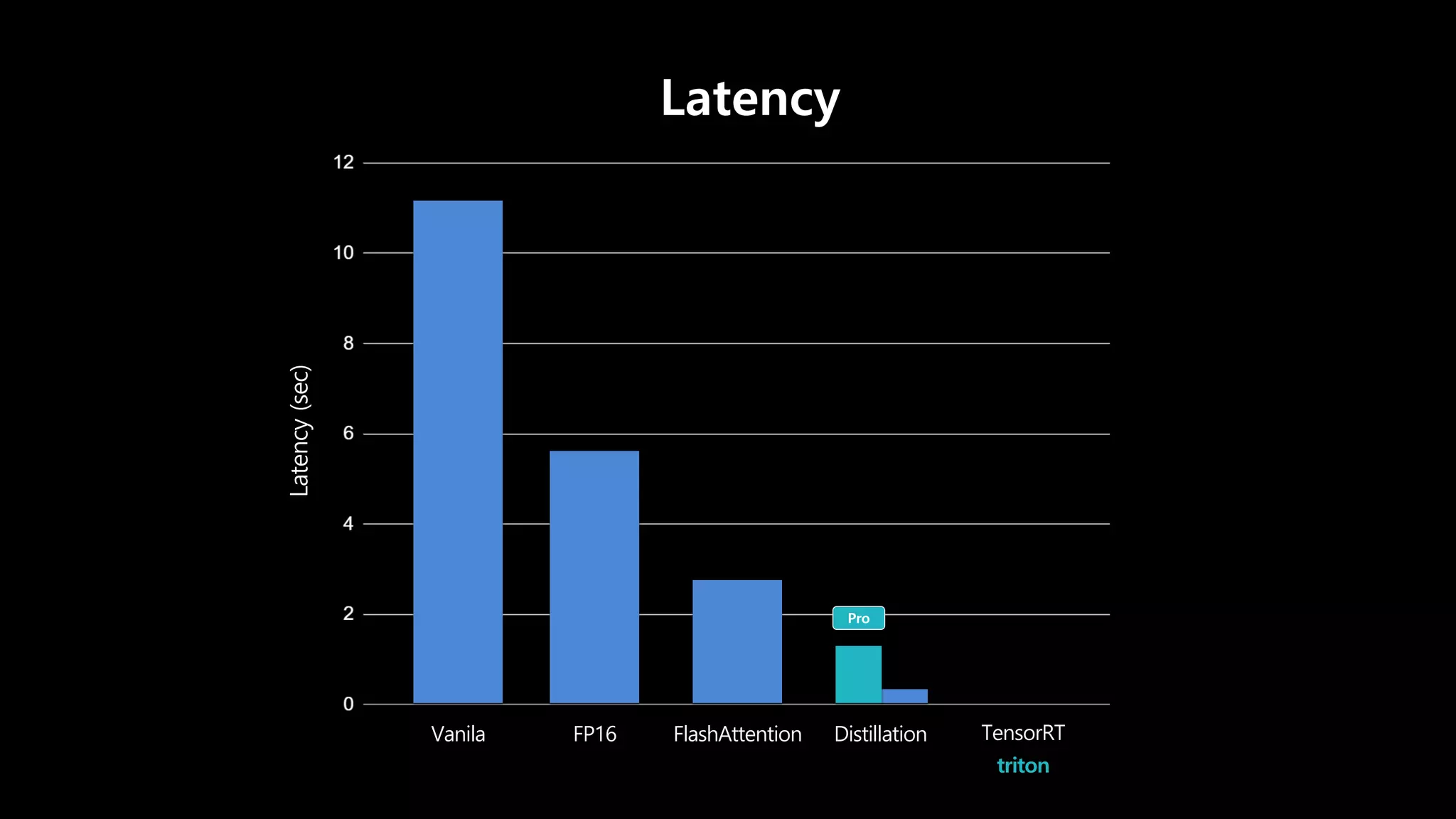
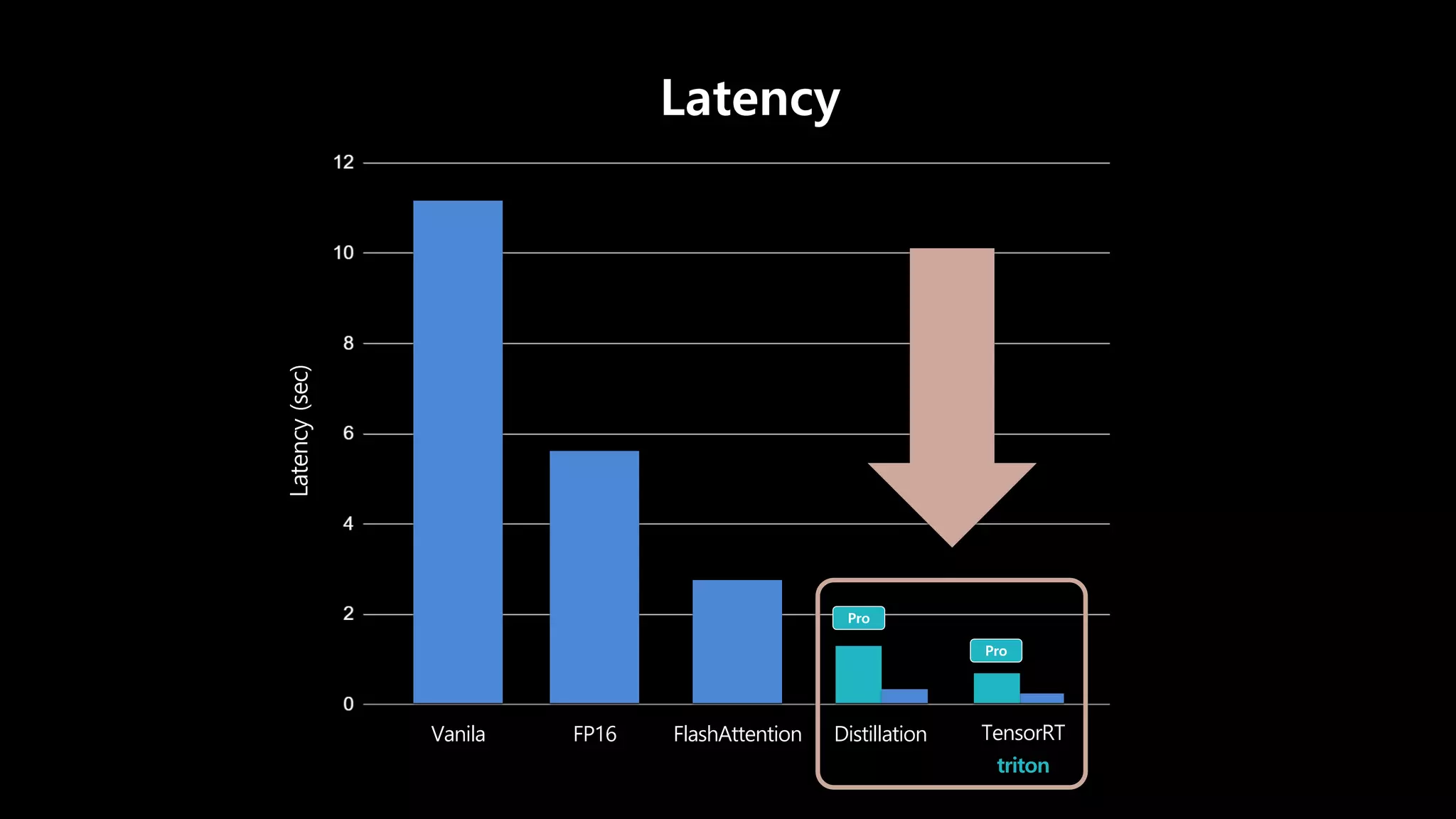
- 89. Latency와 Scalability가 중요
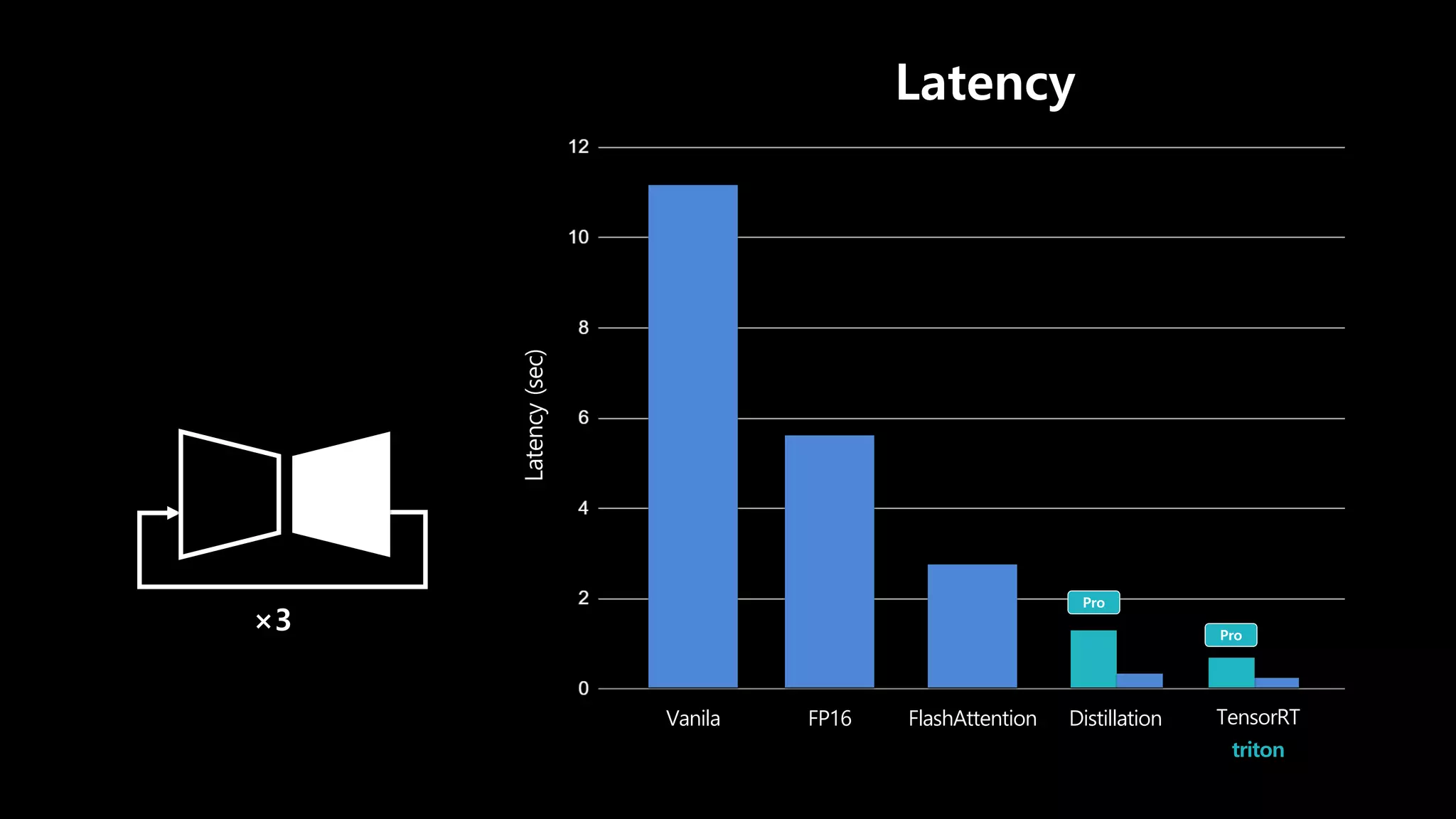
- 90. Latency와 Scalability가 중요 Latency Vanila FlashAttention FP16 Distillation TensorRT triton
- 91. 1. Distillation 2. TensorRT & triton
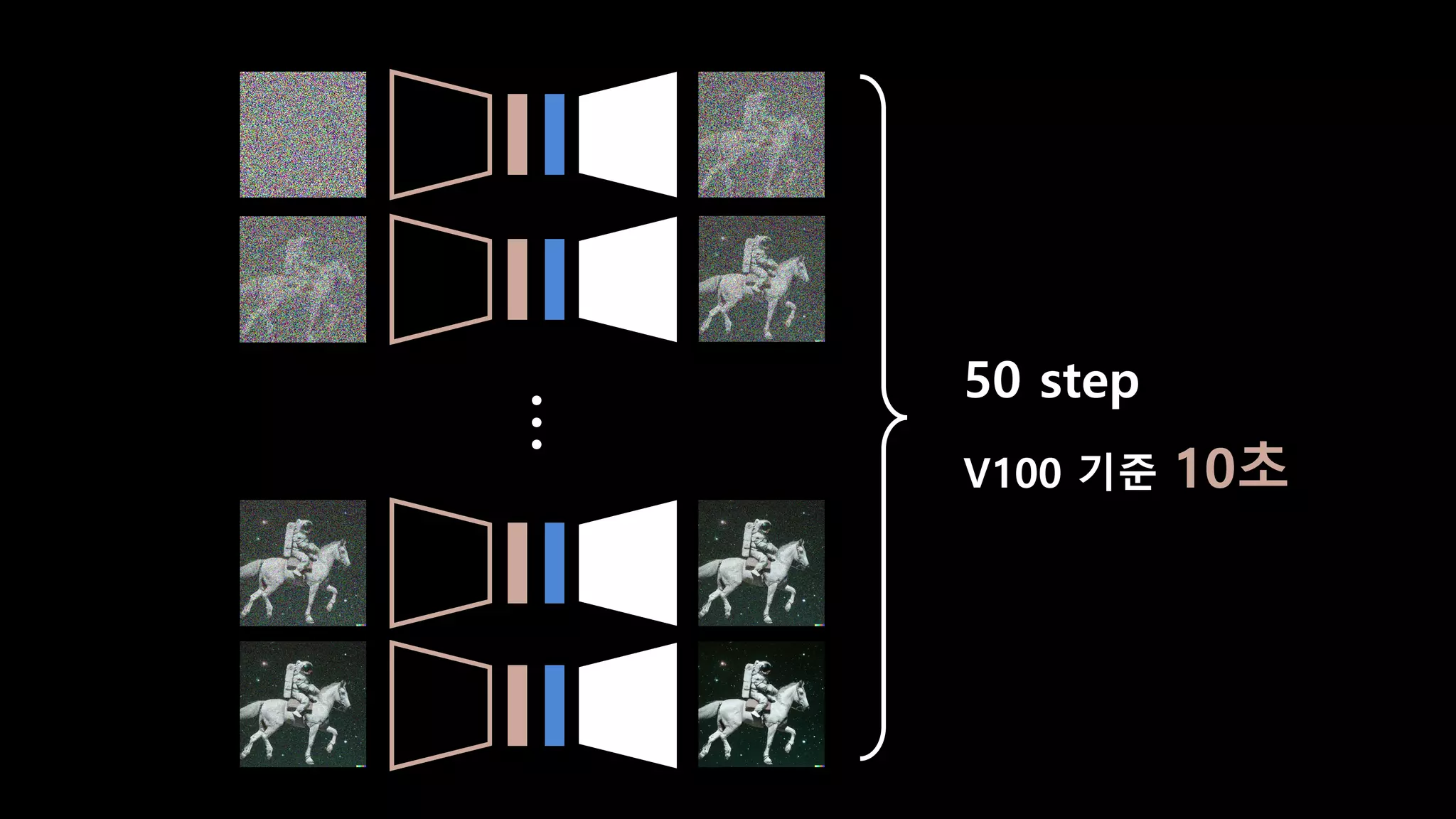
- 92. 1. Distillation by 이동익 2. Compiler 3. Misc. https://github.com/bryandlee/DeepStudio https://github.com/bryandlee/malnyun_faces
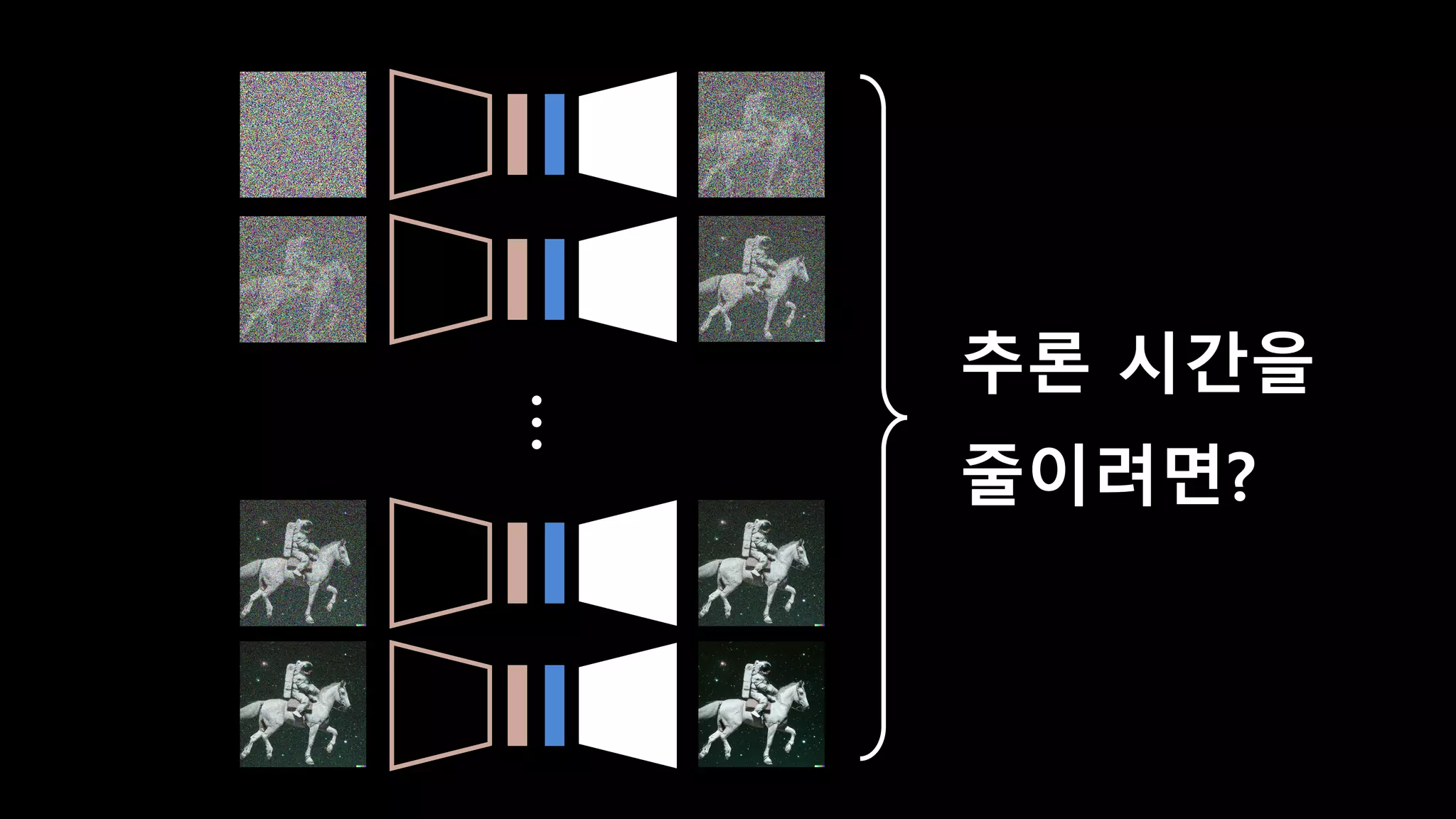
- 93. 50 step V100 기준 10초
- 94. 추론 시간을 줄이려면?
- 95. Knowledge Distillation
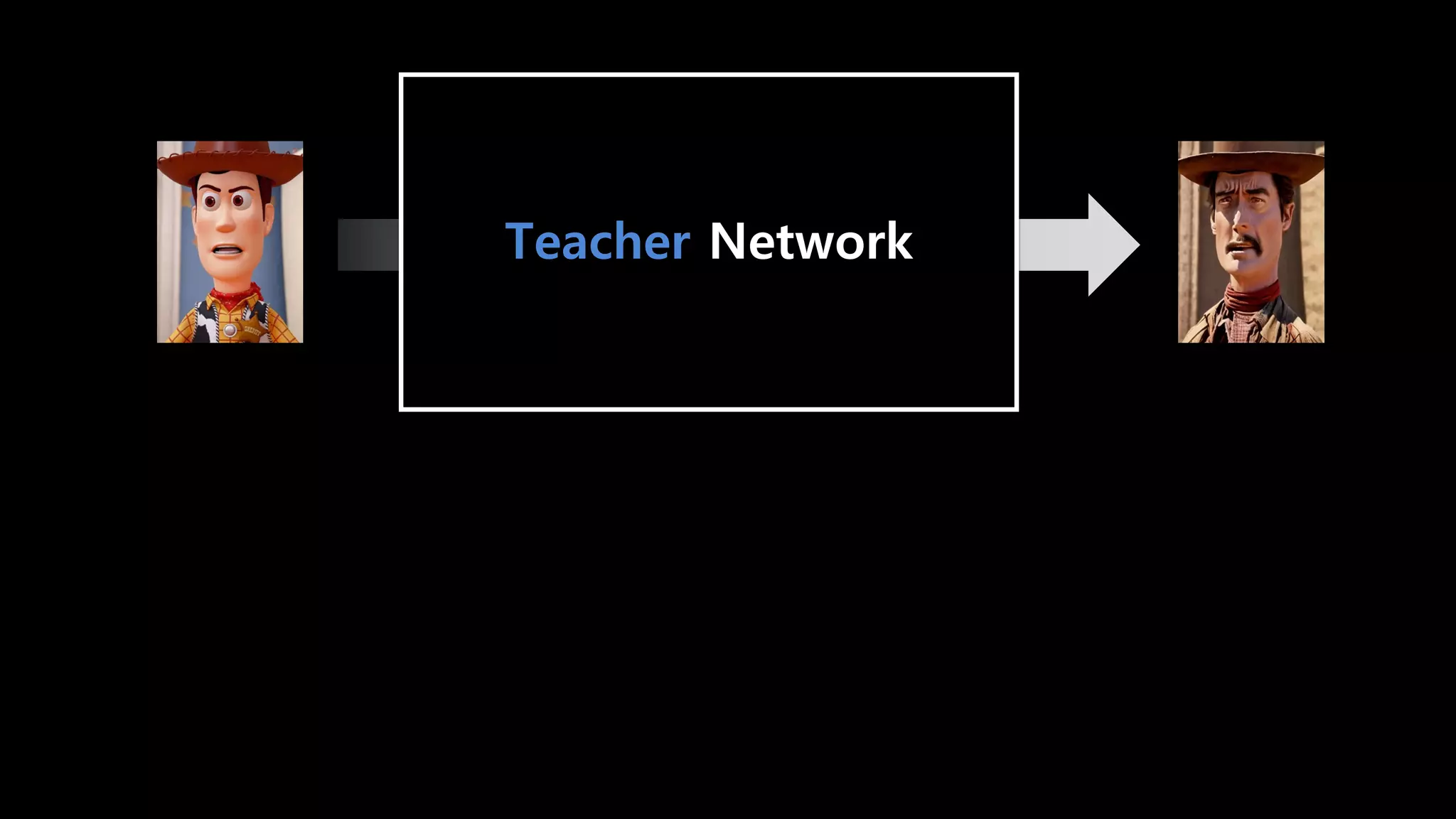
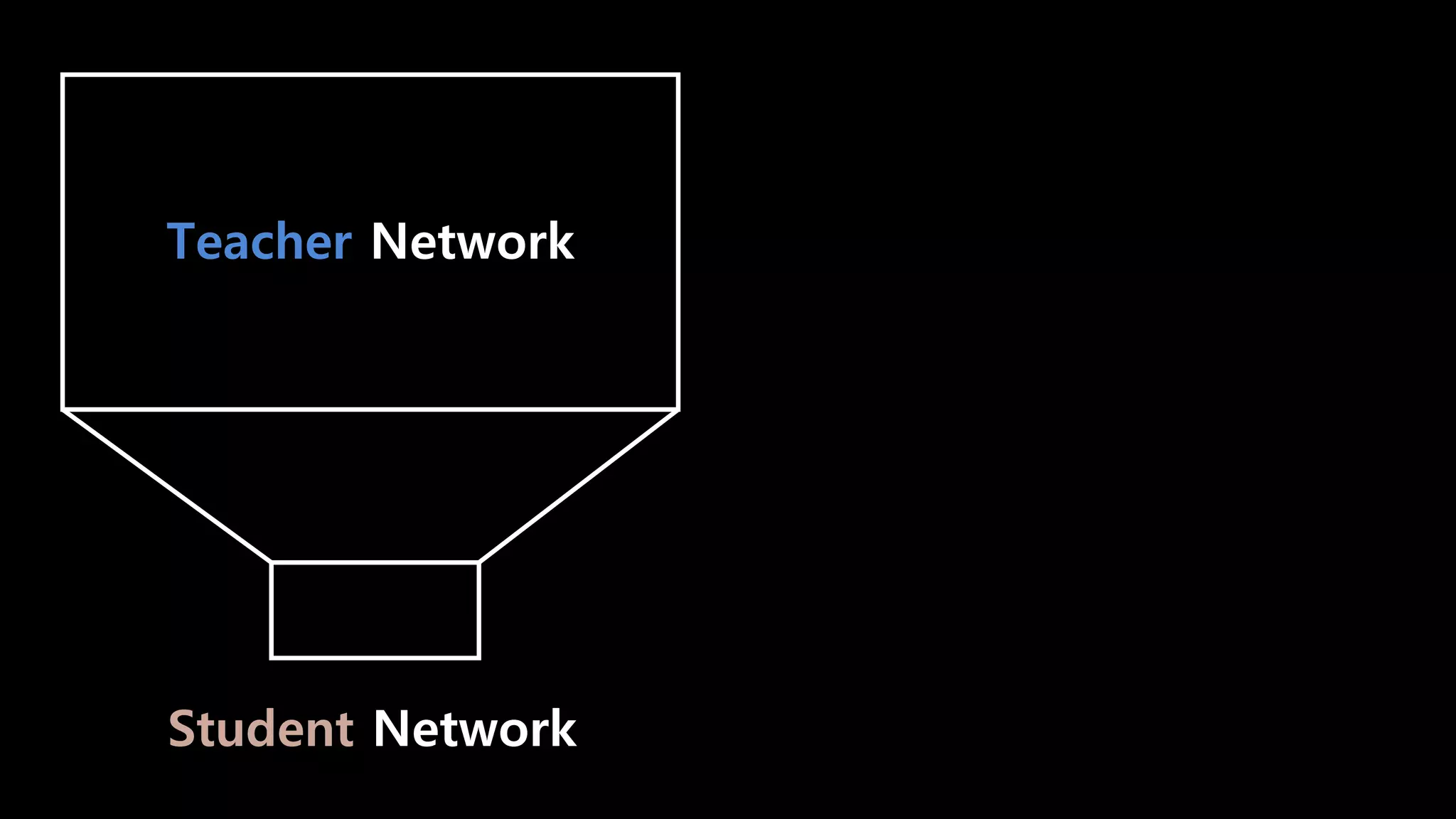
- 96. Knowledge Distillation
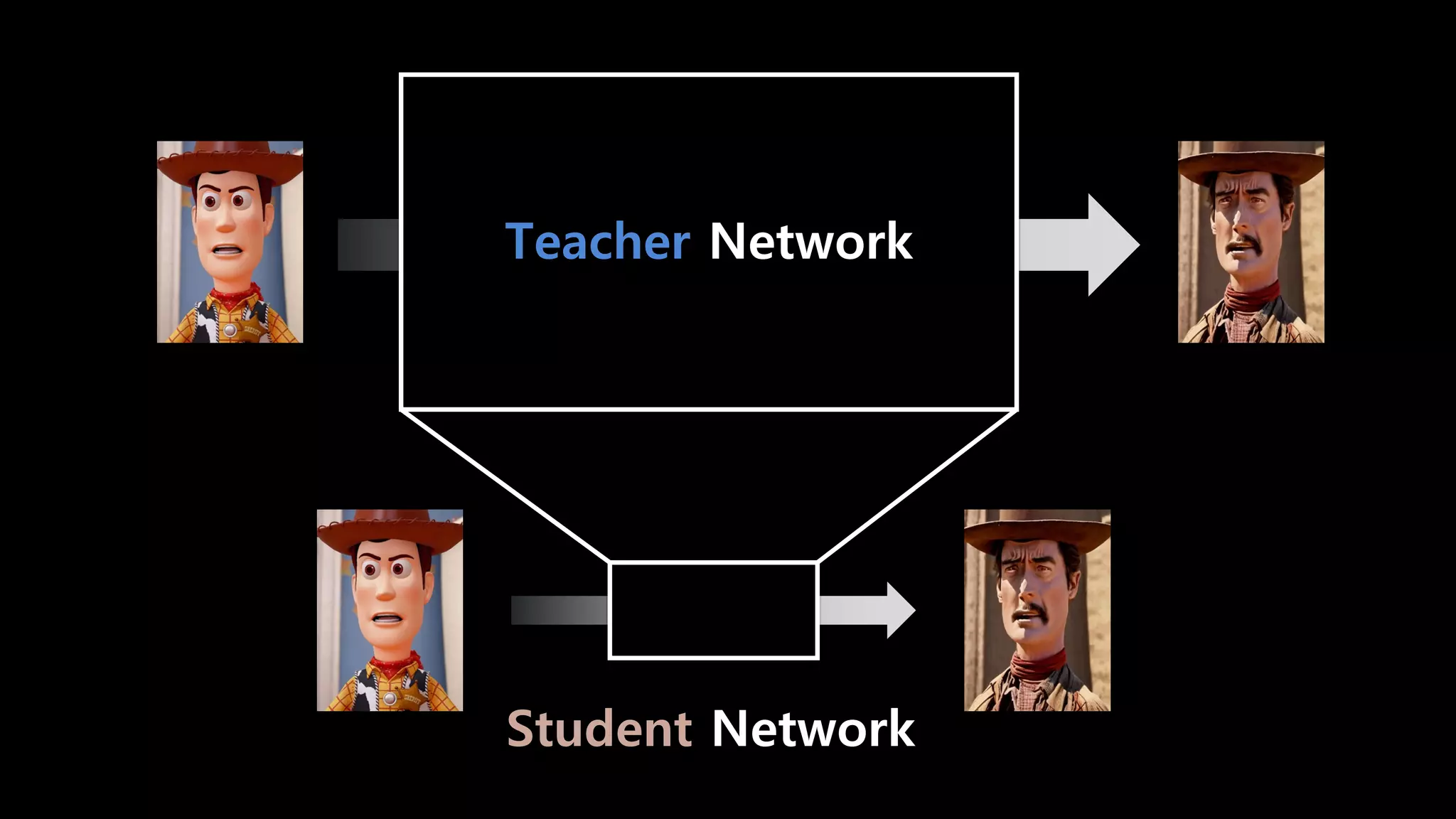
- 97. Teacher Network
- 98. Teacher Network Student Network
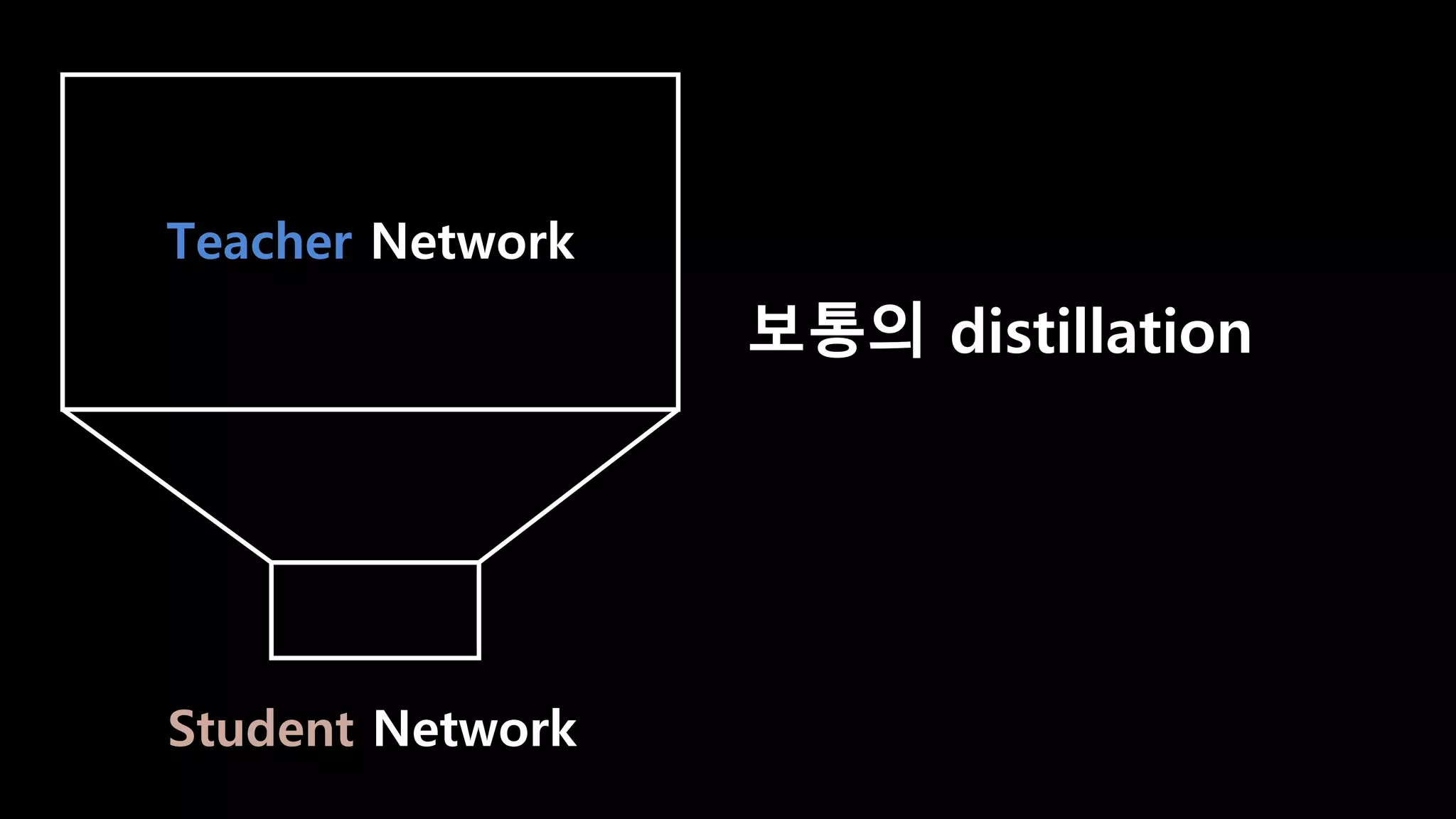
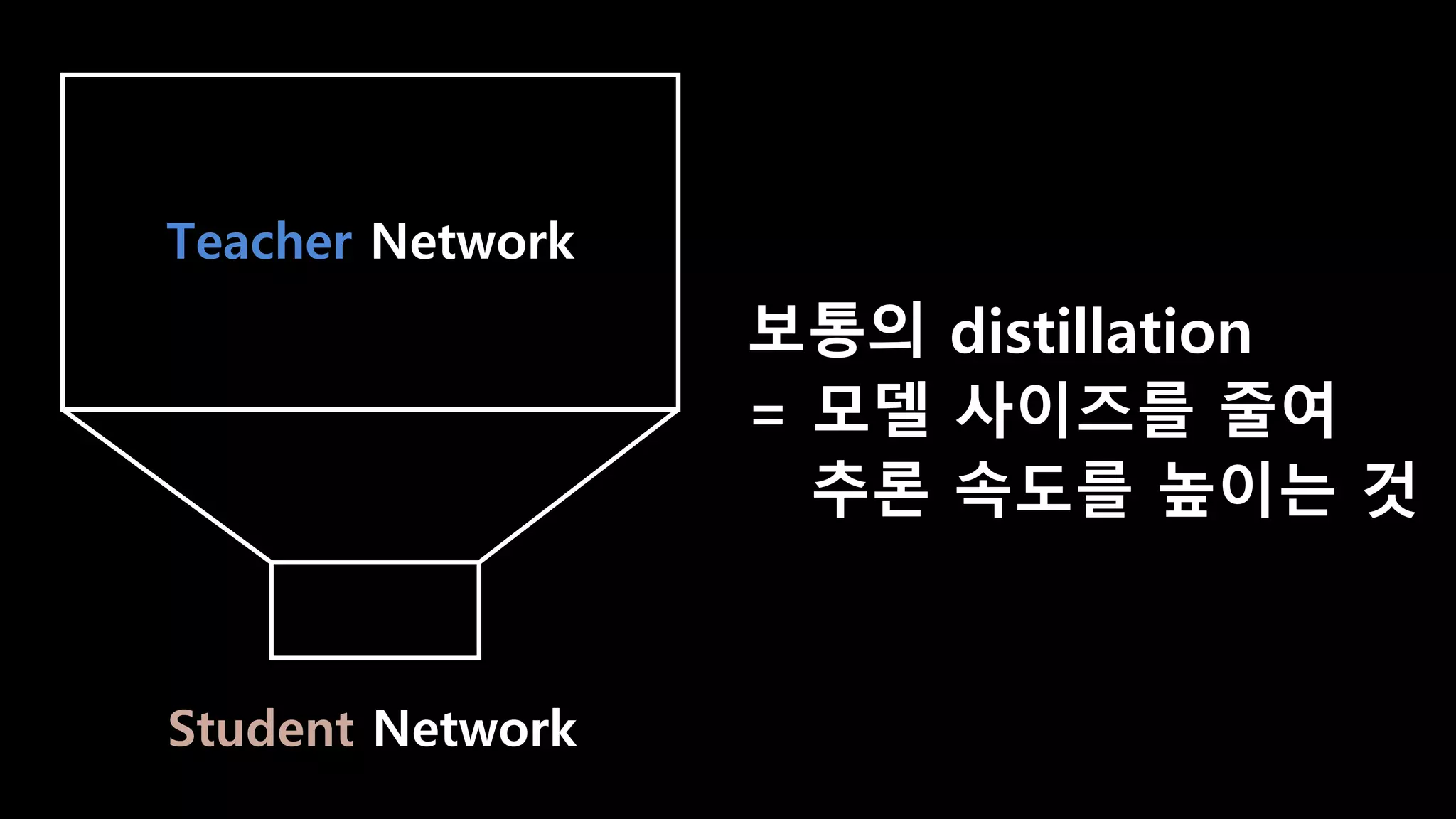
- 99. Teacher Network Student Network
- 100. Teacher Network Student Network 보통의 distillation = 모델 사이즈를 줄여 추론 속도를 높이는 것
- 101. Teacher Network Student Network 보통의 distillation = 모델 사이즈를 줄여 추론 속도를 높이는 것
- 102. 보통의 Knowledge Distillation = 모델 다이어트
- 103. Diffusion 모델도 모델 크기를 줄일 수 있지만
- 104. Distillation을 할 때 마다 절반씩 줄이기
- 105. Distillation을 할 때 마다 절반씩 줄이기
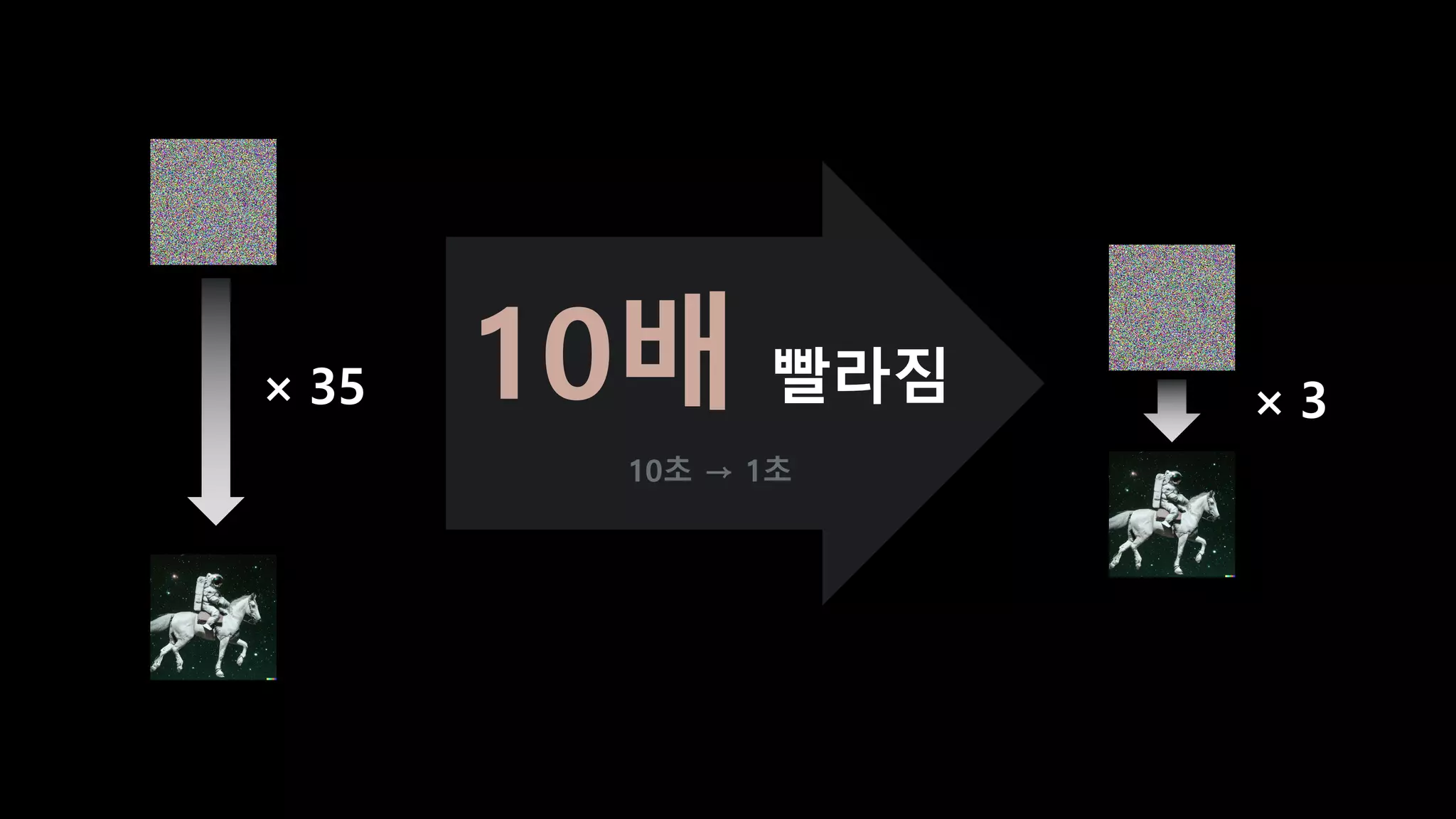
- 106. Distillation of diffusion step = 스텝 다이어트
- 107. × 70 × 35 × 15 × 3
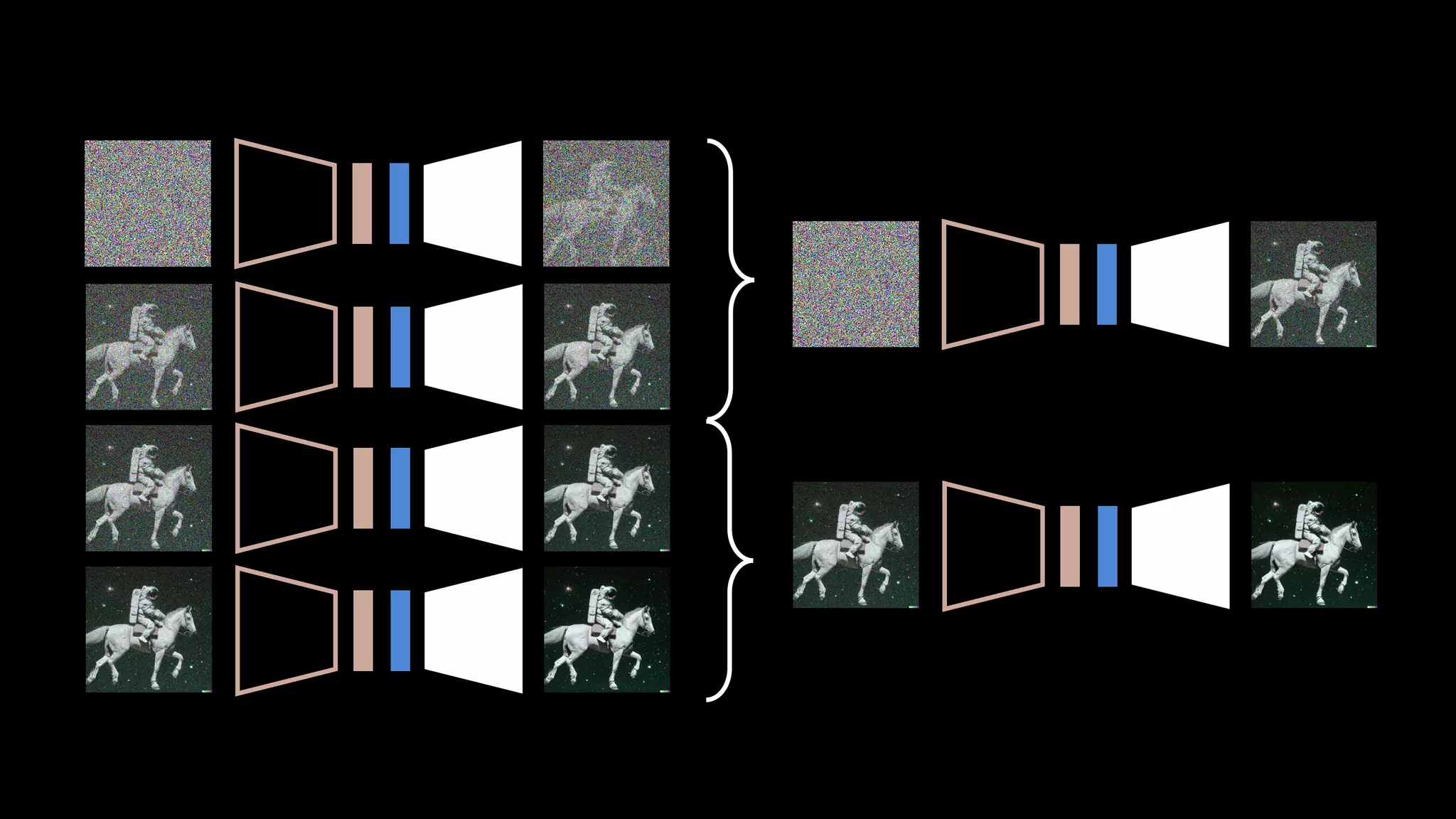
- 108. × 3 × 35 10배 빨라짐 10초 → 1초
- 109. 실험 결과
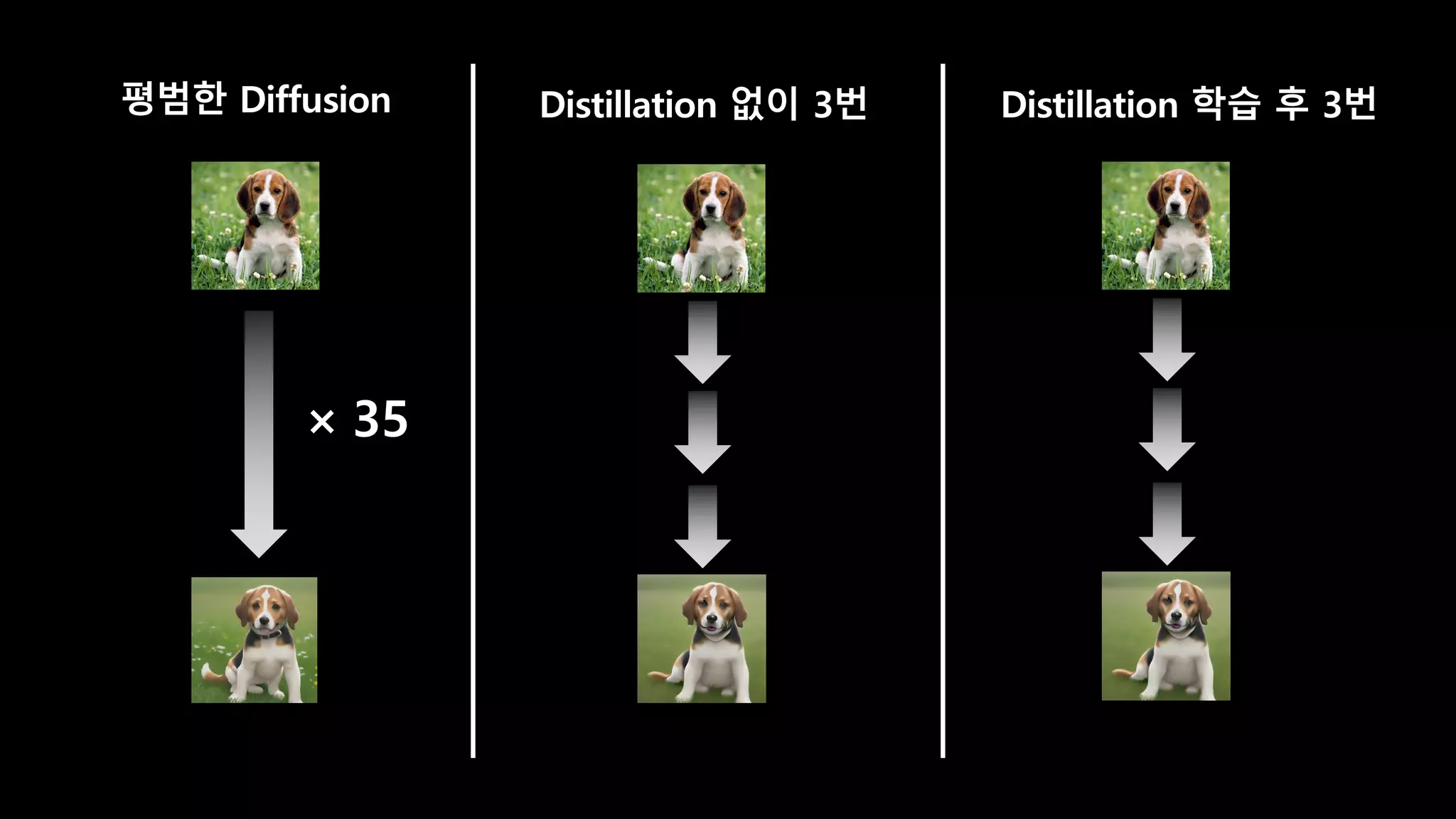
- 110. 1. Image2Image 모델을 학습 2. 기존 모델이 학습한 데이터 셋에서 학습 3. 1번의 학습은 평균 1.5일 정도 걸림 4. 전체 학습 기간은 6일
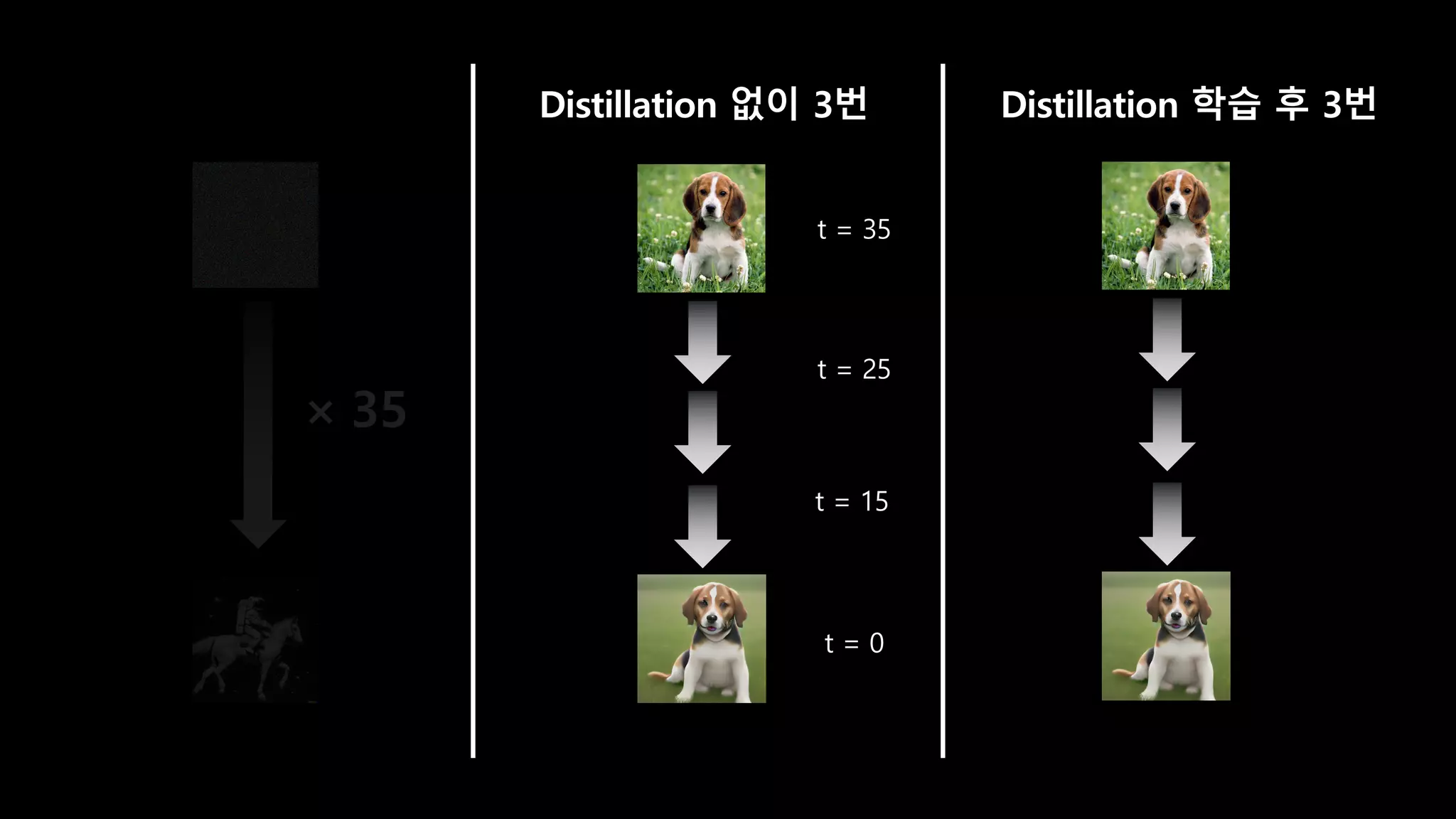
- 111. Distillation 없이 3번 × 35 평범한 Diffusion Distillation 학습 후 3번
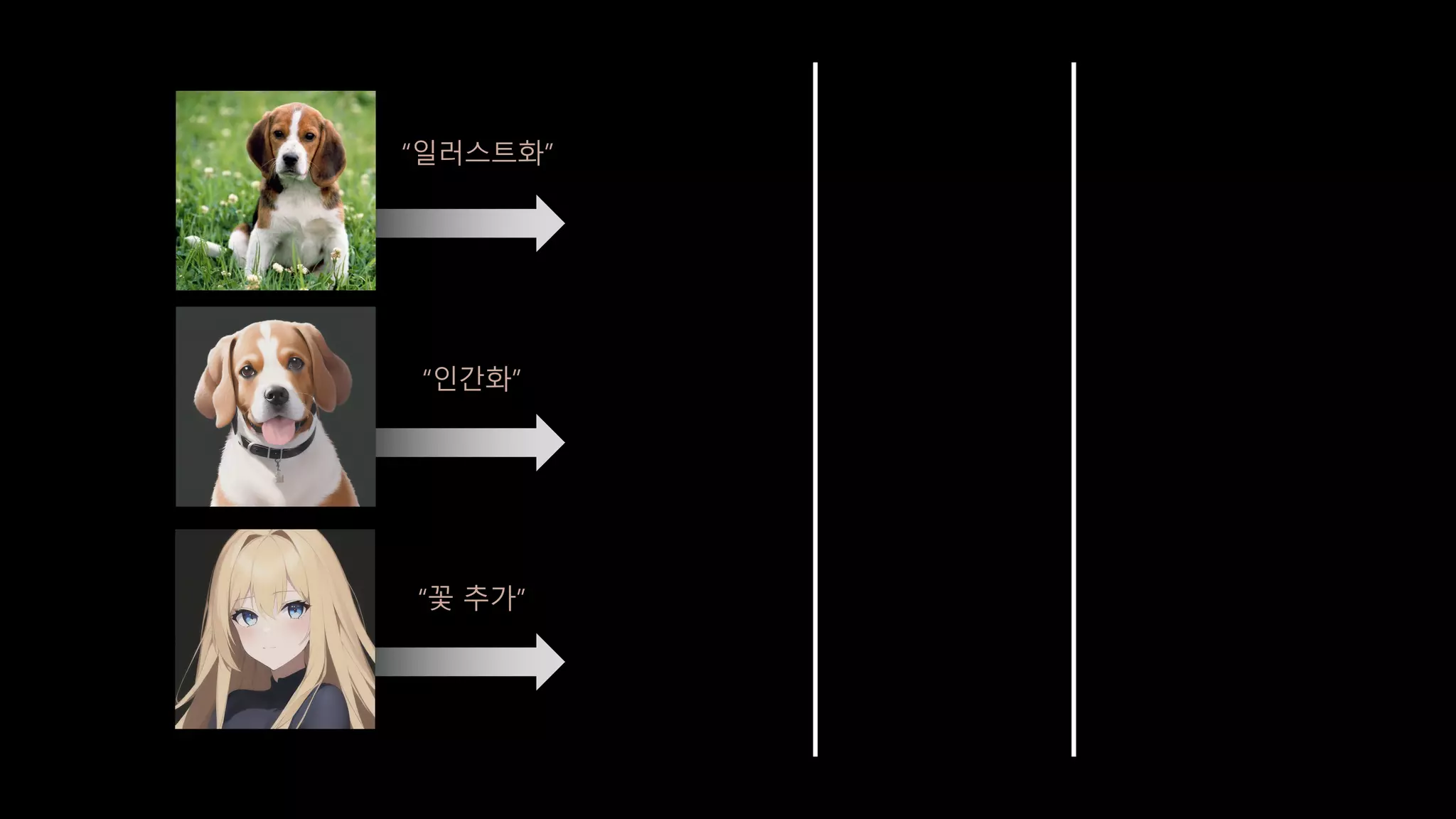
- 112. × 35 Distillation 학습 후 3번 Distillation 없이 3번 t = 35 t = 0 t = 15 t = 25
- 113. “일러스트화” “인간화” “꽃 추가”
- 114. “일러스트화” “인간화” “꽃 추가”
- 115. 평범한 Diffusion Distillation 없이 3번 Distillation 학습 후 3번
- 116. × 3 × 35 Free Pro 완성도를 중요시 하는 유저
- 117. Latency (sec) Latency Vanila FlashAttention FP16 Distillation TensorRT triton
- 118. 1. Distillation 2. TensorRT & triton
- 119. 1. Distillation by 이동익 2. TensorRT & triton
- 120. 이전 슬라이드
- 121. GPU 하드웨어 구조
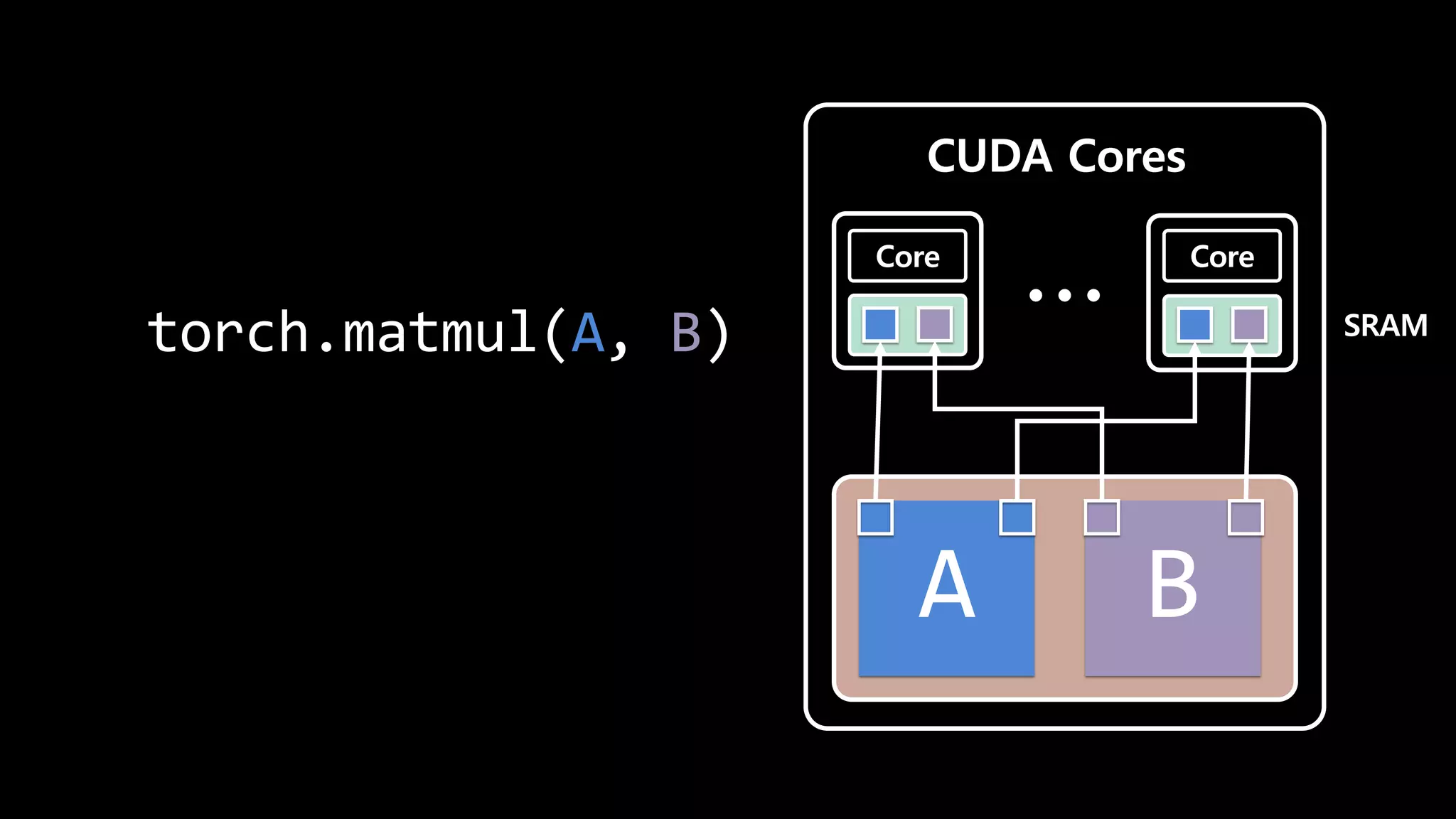
- 122. HBM Core Core SRAM SRAM 느린 I/O CUDA Cores Core Core
- 123. CUDA Cores A B Core Core SRAM torch.matmul(A, B)
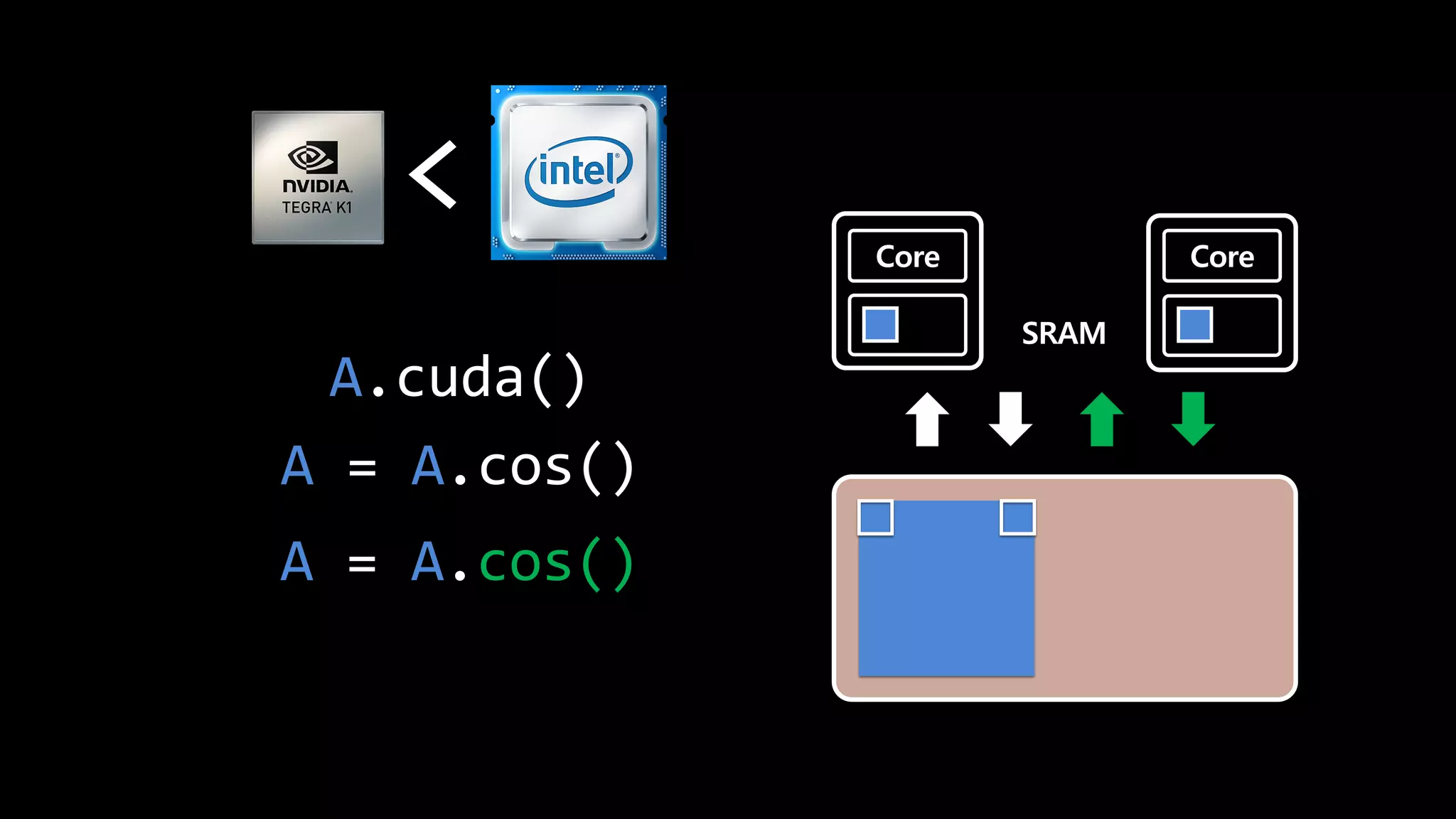
- 124. Core Core torch.matmul(A, ) > SRAM
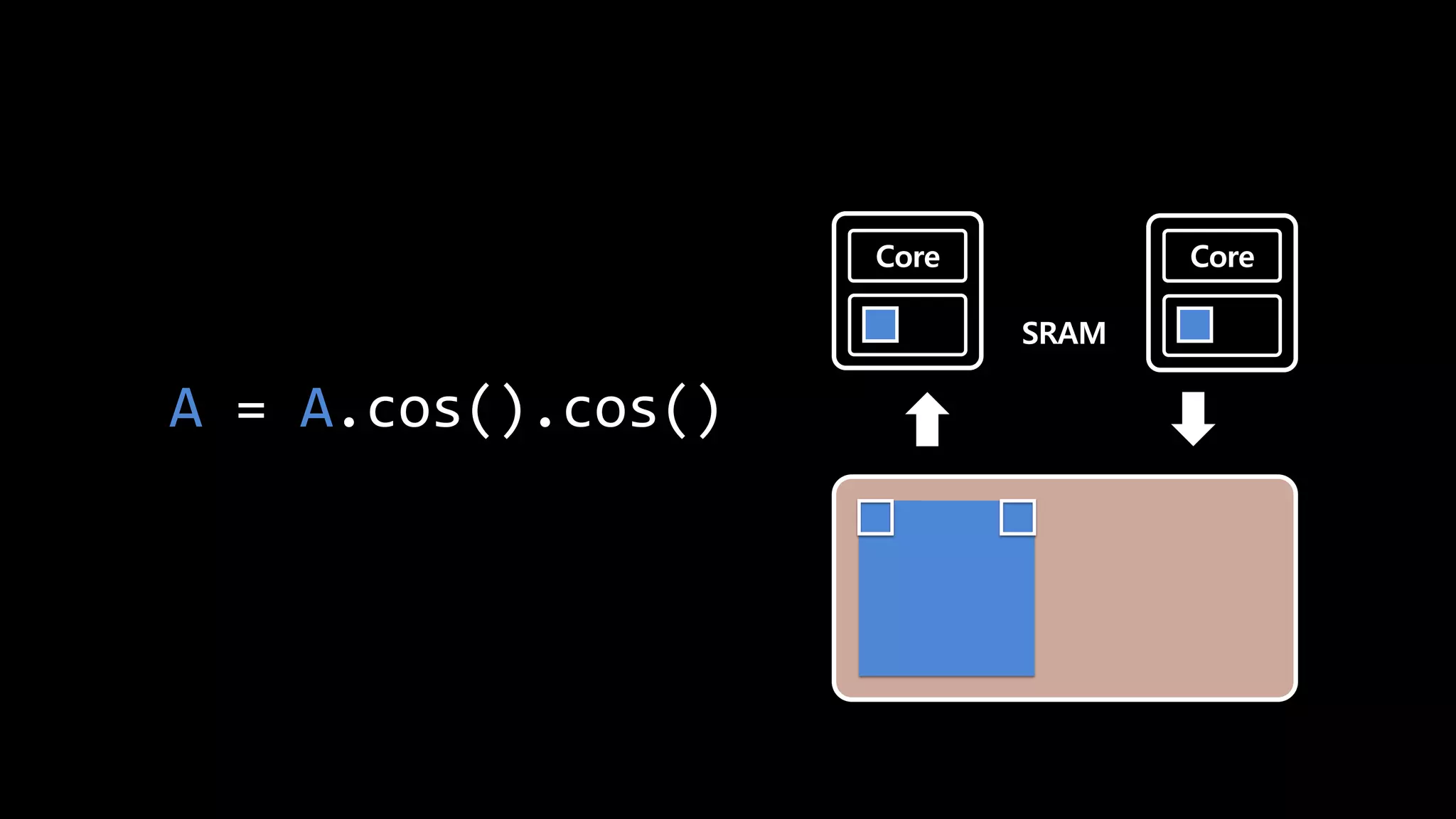
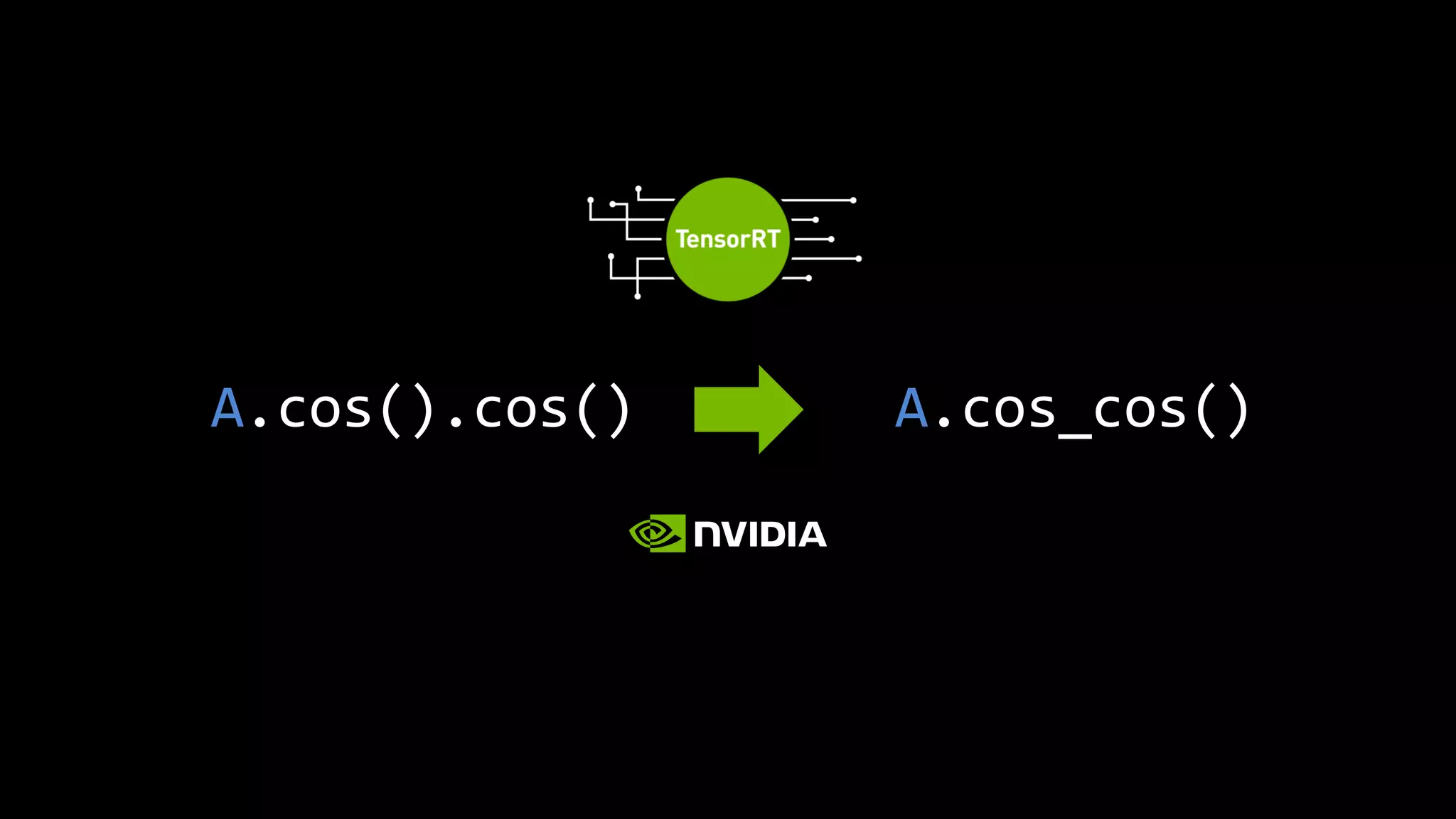
- 125. Core Core SRAM A = A.cos() < A = A.cos() A.cuda()
- 126. Core Core A = A.cos().cos() SRAM
- 127. A.cos().cos() A.cos_cos()
- 128. TensorRT를 쓰는 방법
- 129. model = Model()
- 130. model = Model() onnx = Onnx.export(model)
- 131. model = Model() onnx = Onnx.export(model) new_model = trt.compile(onnx)
- 132. model = Model() onnx = Onnx.export(model) new_model = trt.compile(onnx) y = new_model(x)
- 133. 이것만 쓰면 되는 건가? new_model = trt.compile(onnx)
- 134. Nope. Static graph 만으론 모든걸 알 순 없음
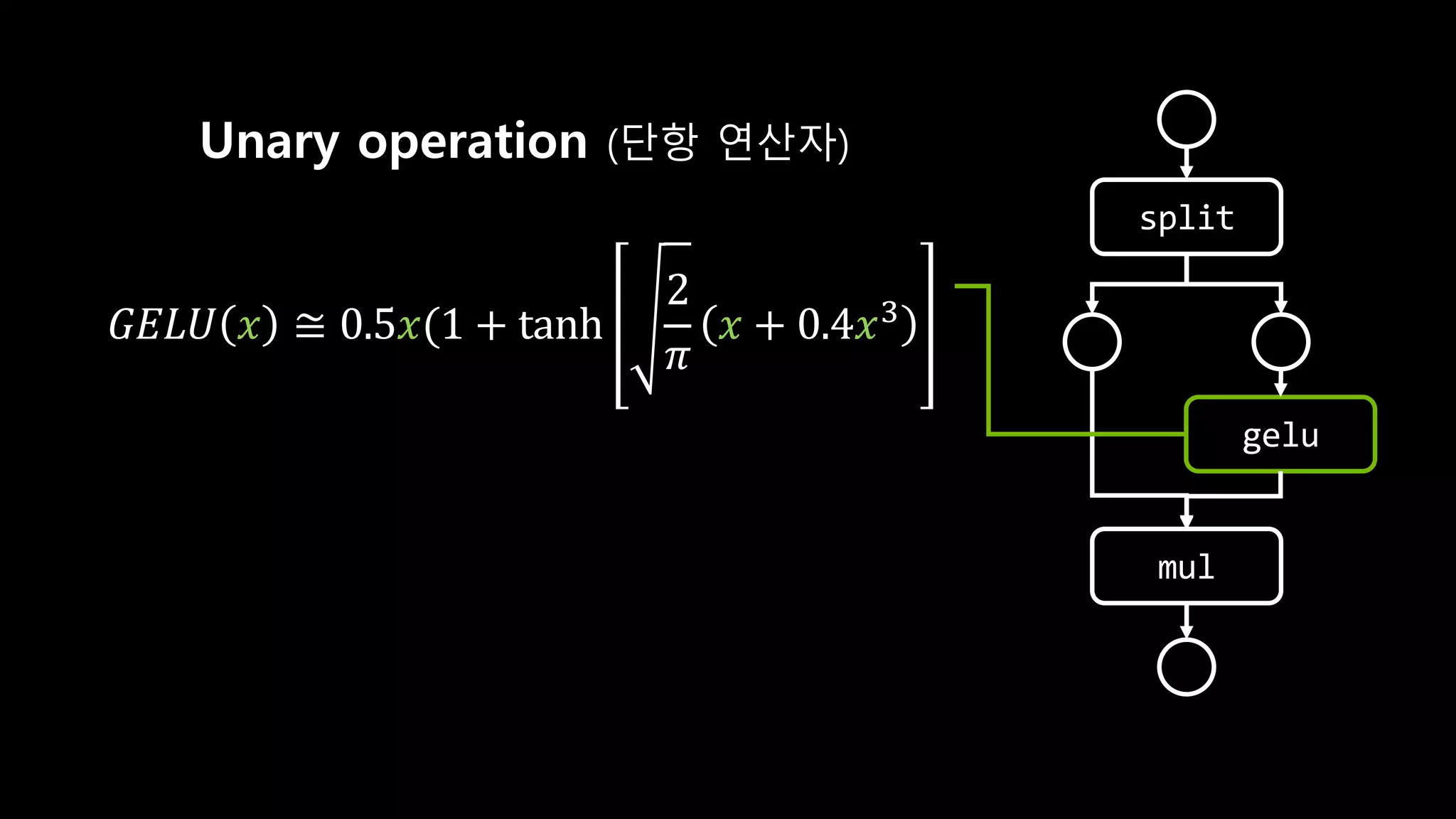
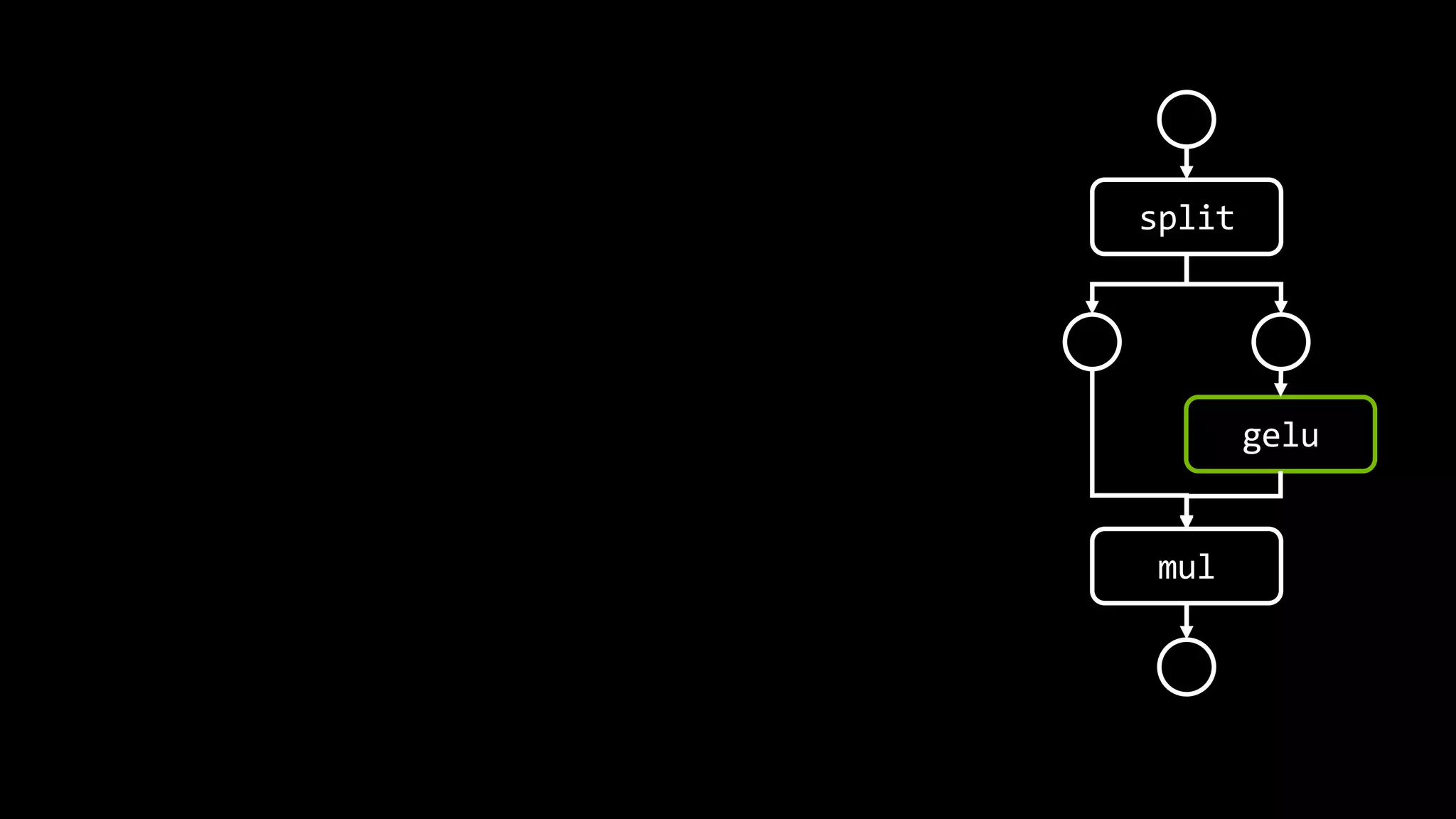
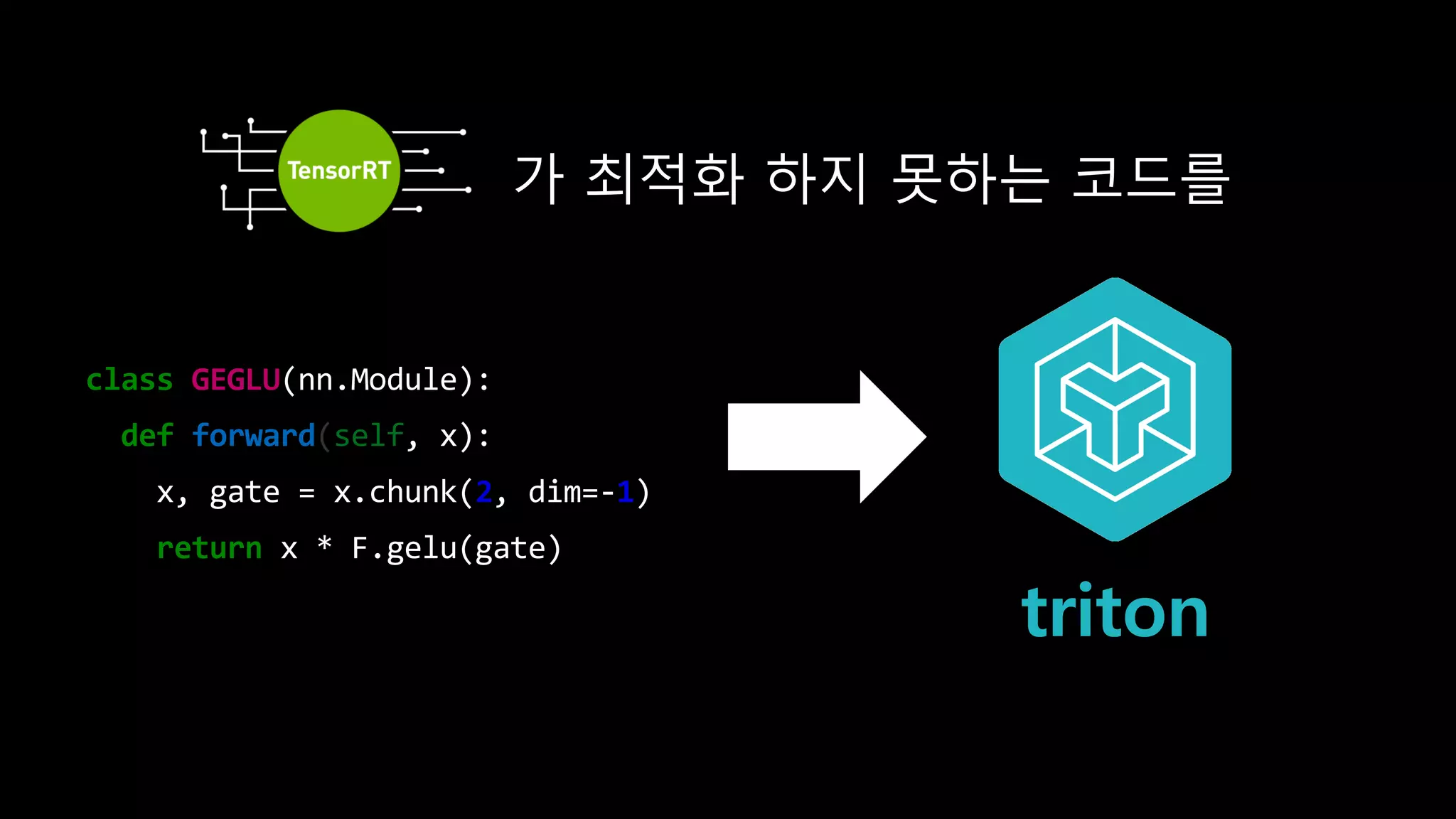
- 135. Nope. Static graph 만으론 모든걸 알 순 없음
- 136. class GEGLU(nn.Module): def forward(self, x): x, gate = x.chunk(2, dim=-1) return x * F.gelu(gate) https://github.com/CompVis/latent-diffusion/blob/main/ldm/modules/attention.py#L37-L44 split gelu mul x
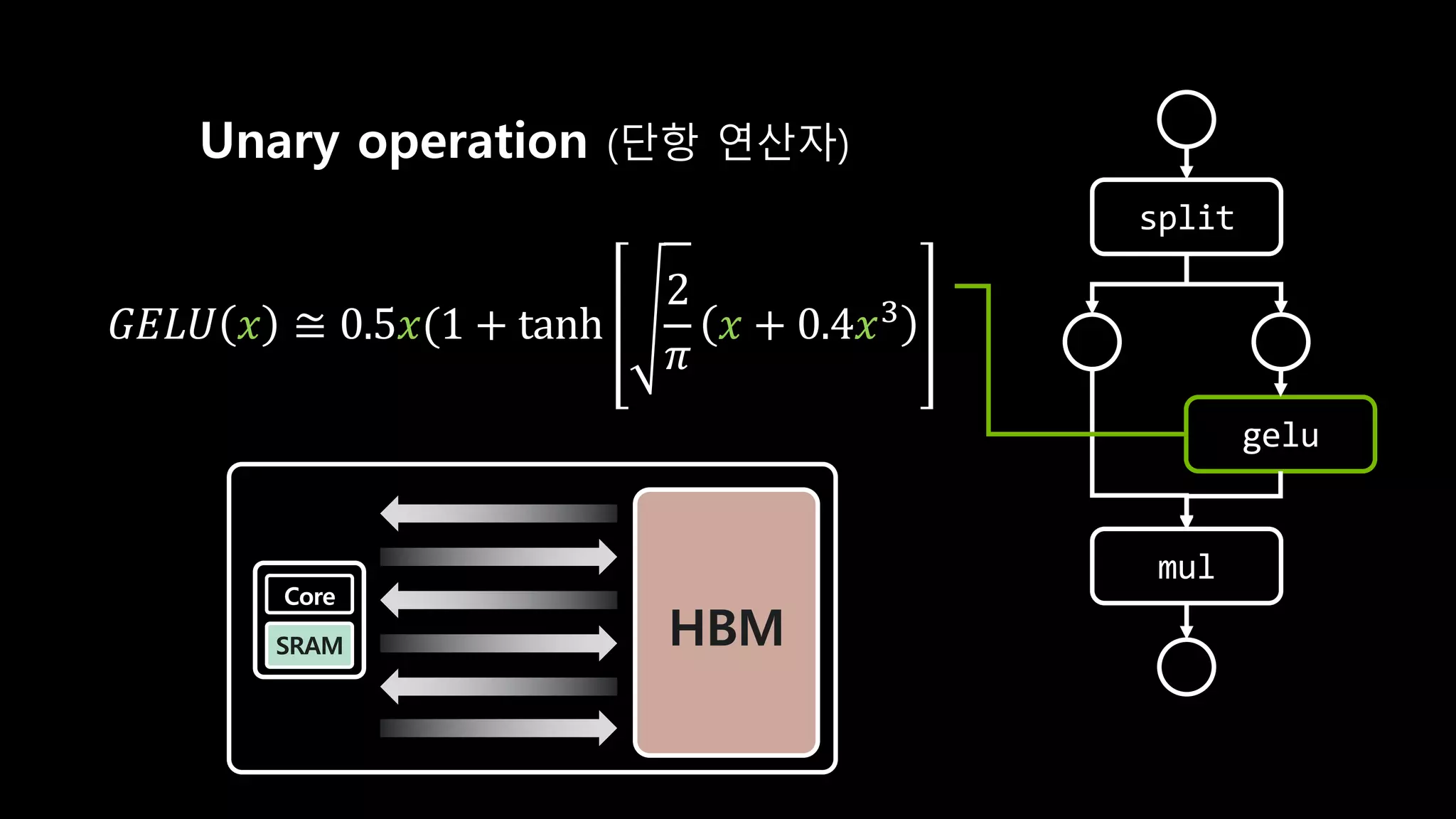
- 137. split gelu mul Unary operation (단항 연산자) 𝐺𝐸𝐿𝑈 𝑥 ≅ 0.5𝑥(1 + tanh 2 𝜋 𝑥 + 0.4𝑥4
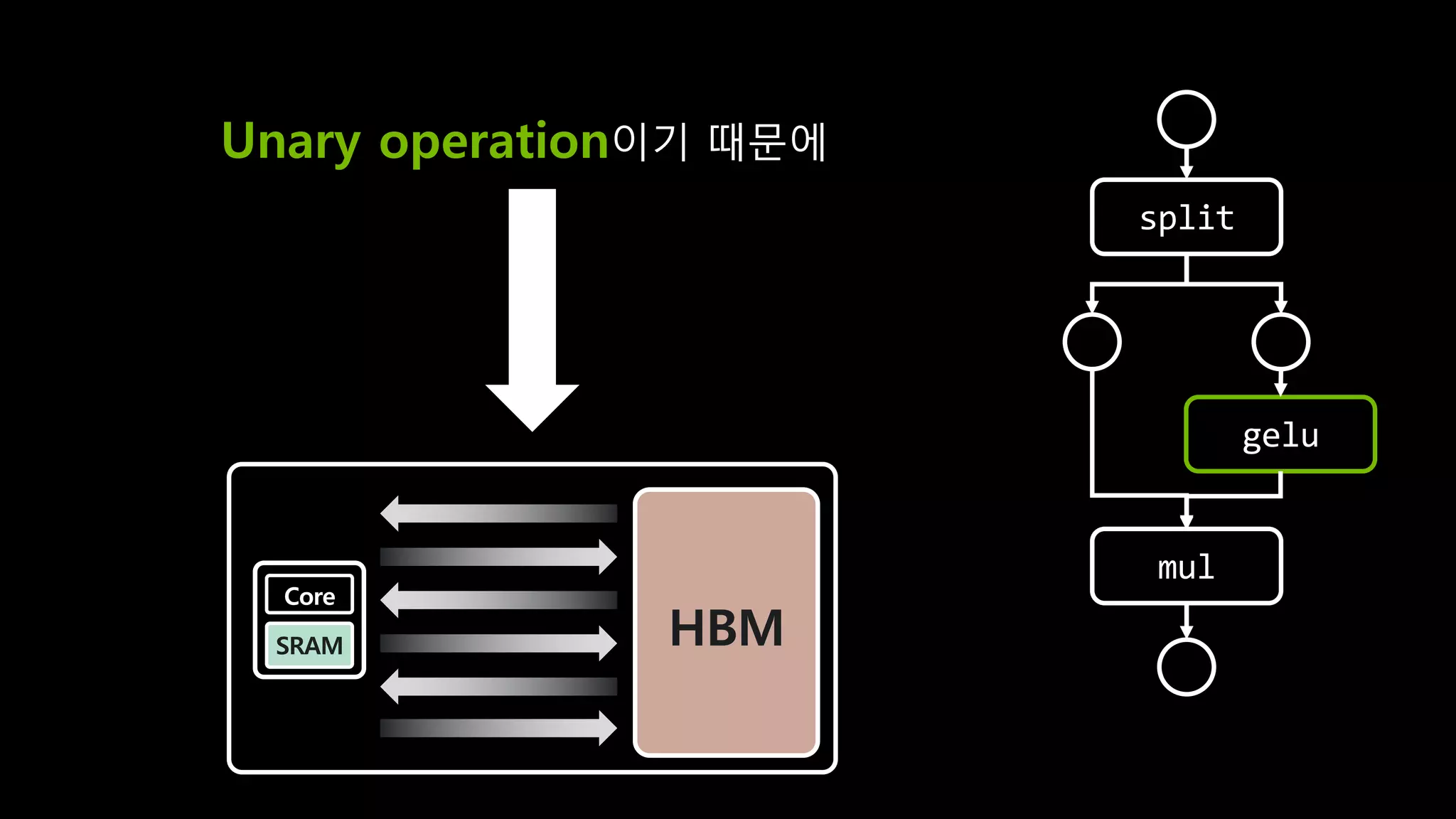
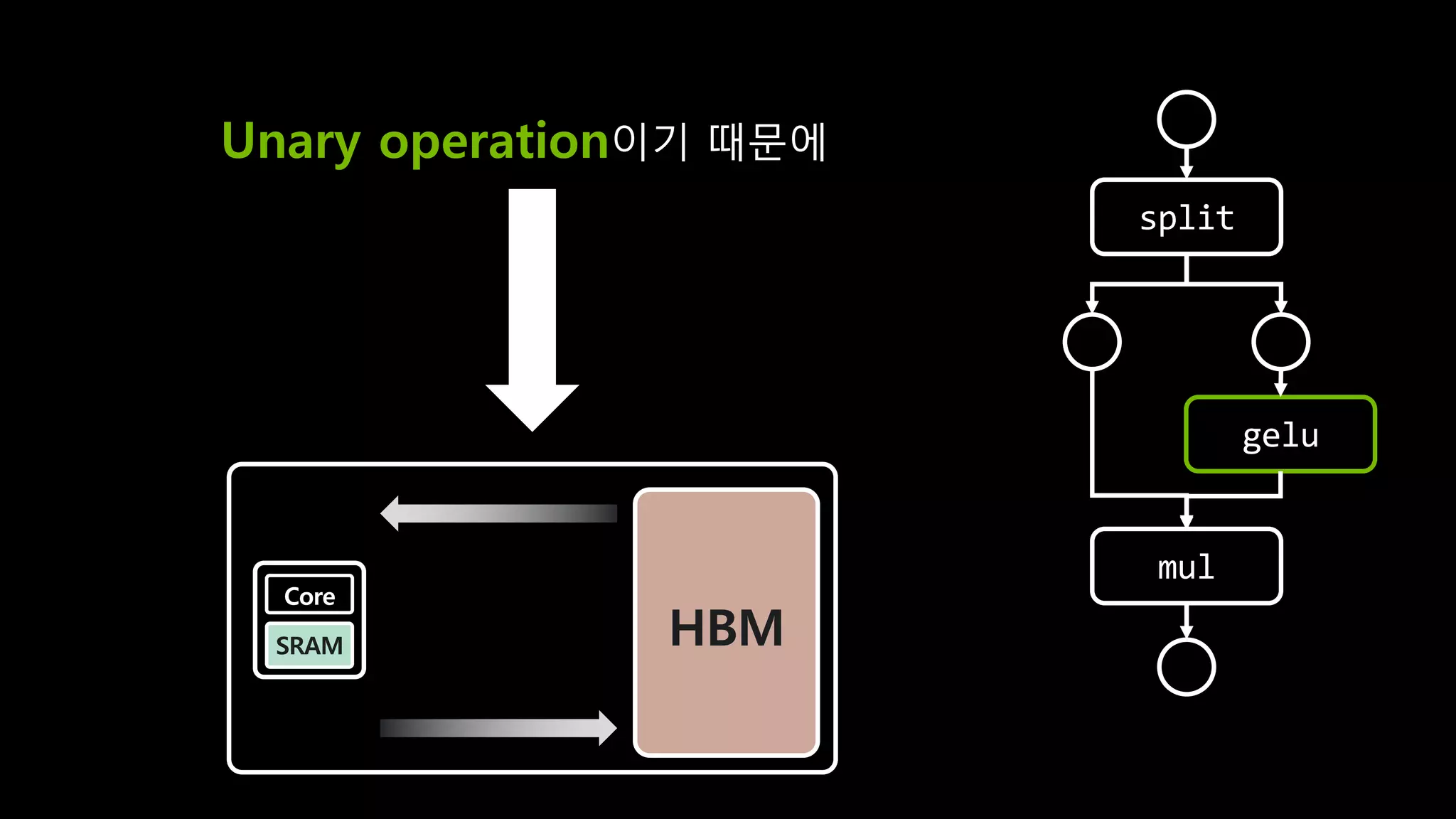
- 138. split gelu mul Unary operation (단항 연산자) HBM Core SRAM 𝐺𝐸𝐿𝑈 𝑥 ≅ 0.5𝑥(1 + tanh 2 𝜋 𝑥 + 0.4𝑥4
- 139. split gelu mul Unary operation이기 때문에 HBM Core SRAM HBM Core SRAM
- 140. split gelu mul Unary operation이기 때문에 HBM Core SRAM HBM Core SRAM
- 141. split gelu mul
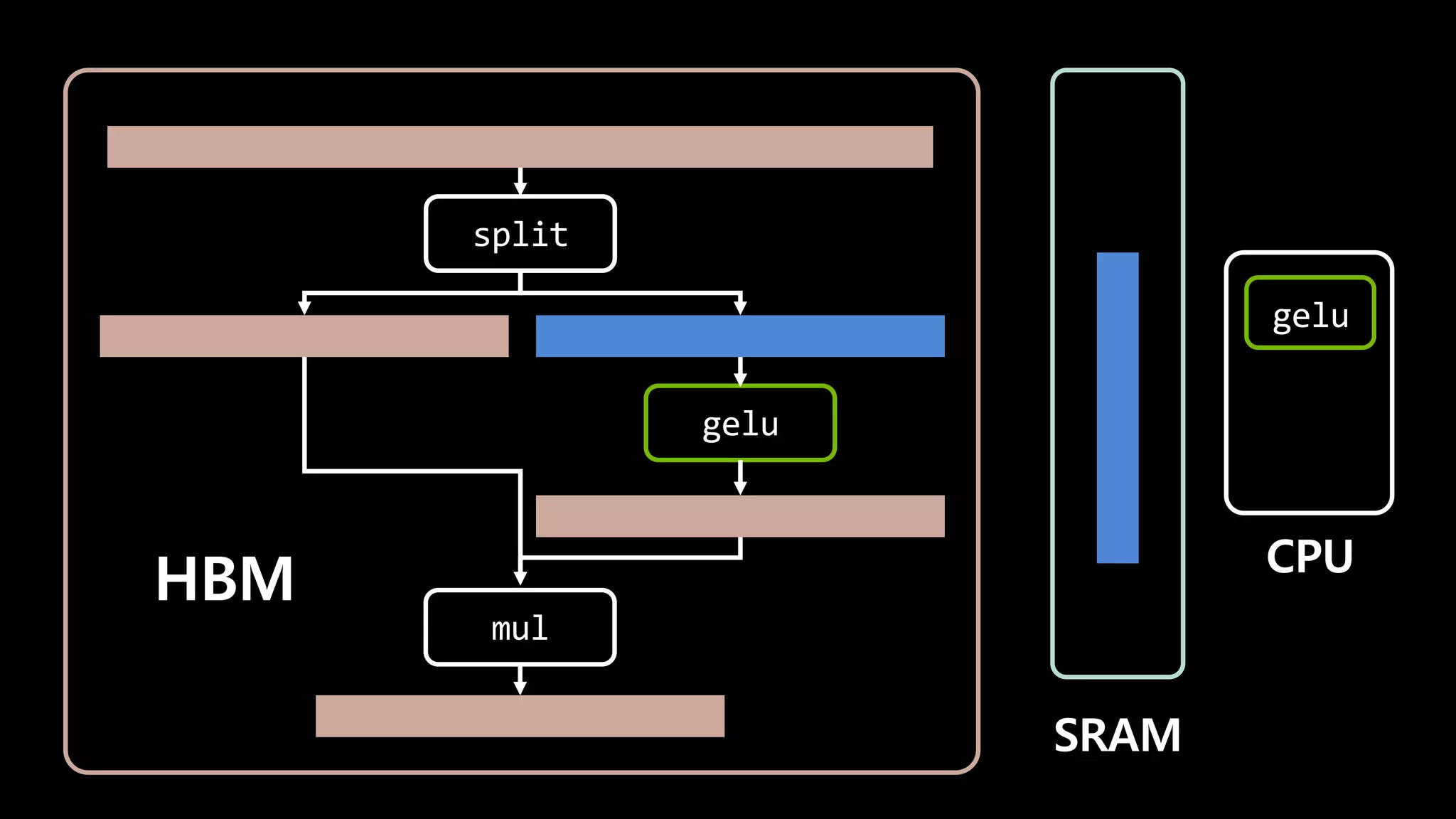
- 142. split gelu mul split gelu mul HBM
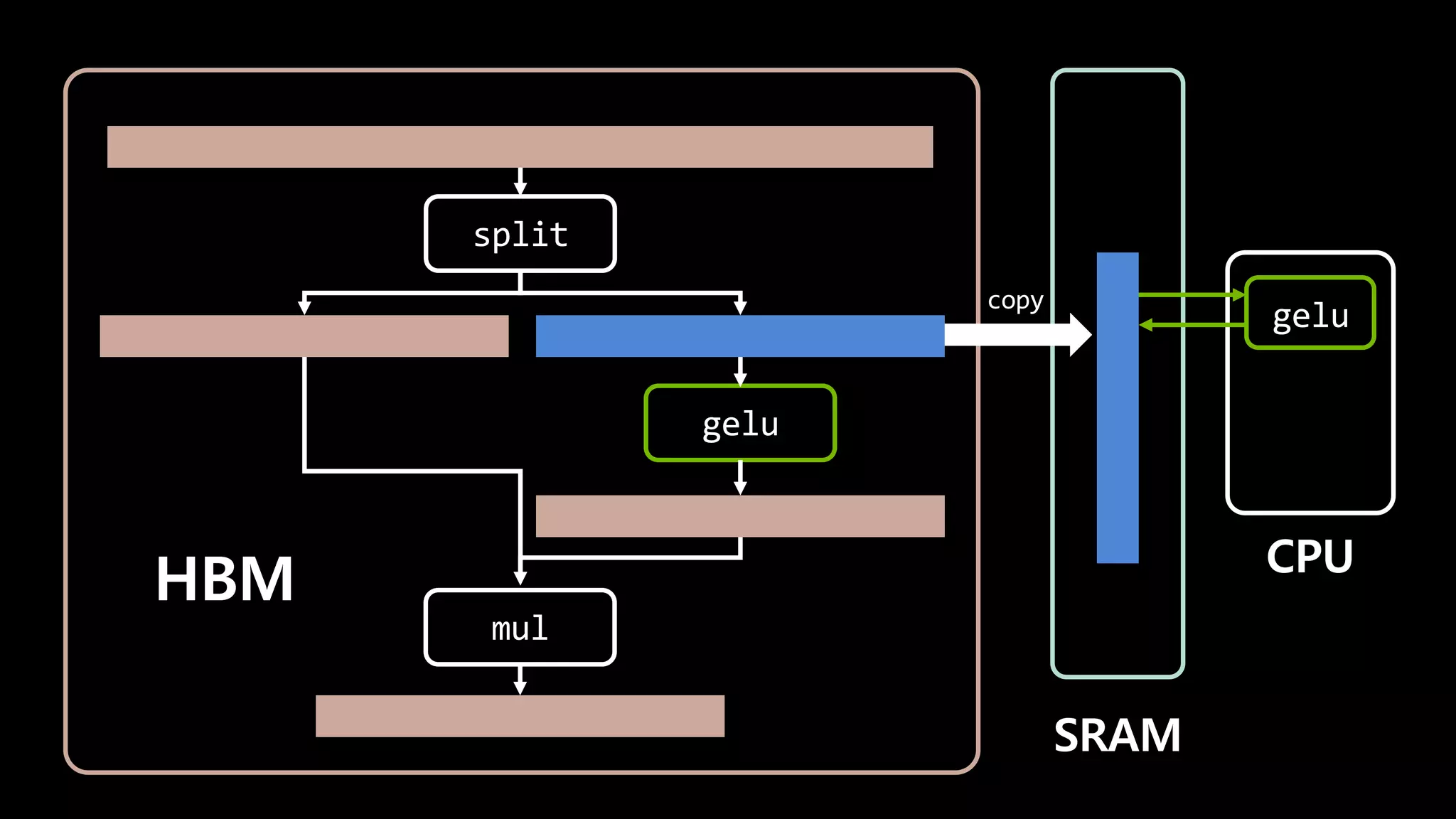
- 143. split gelu mul HBM SRAM gelu CPU
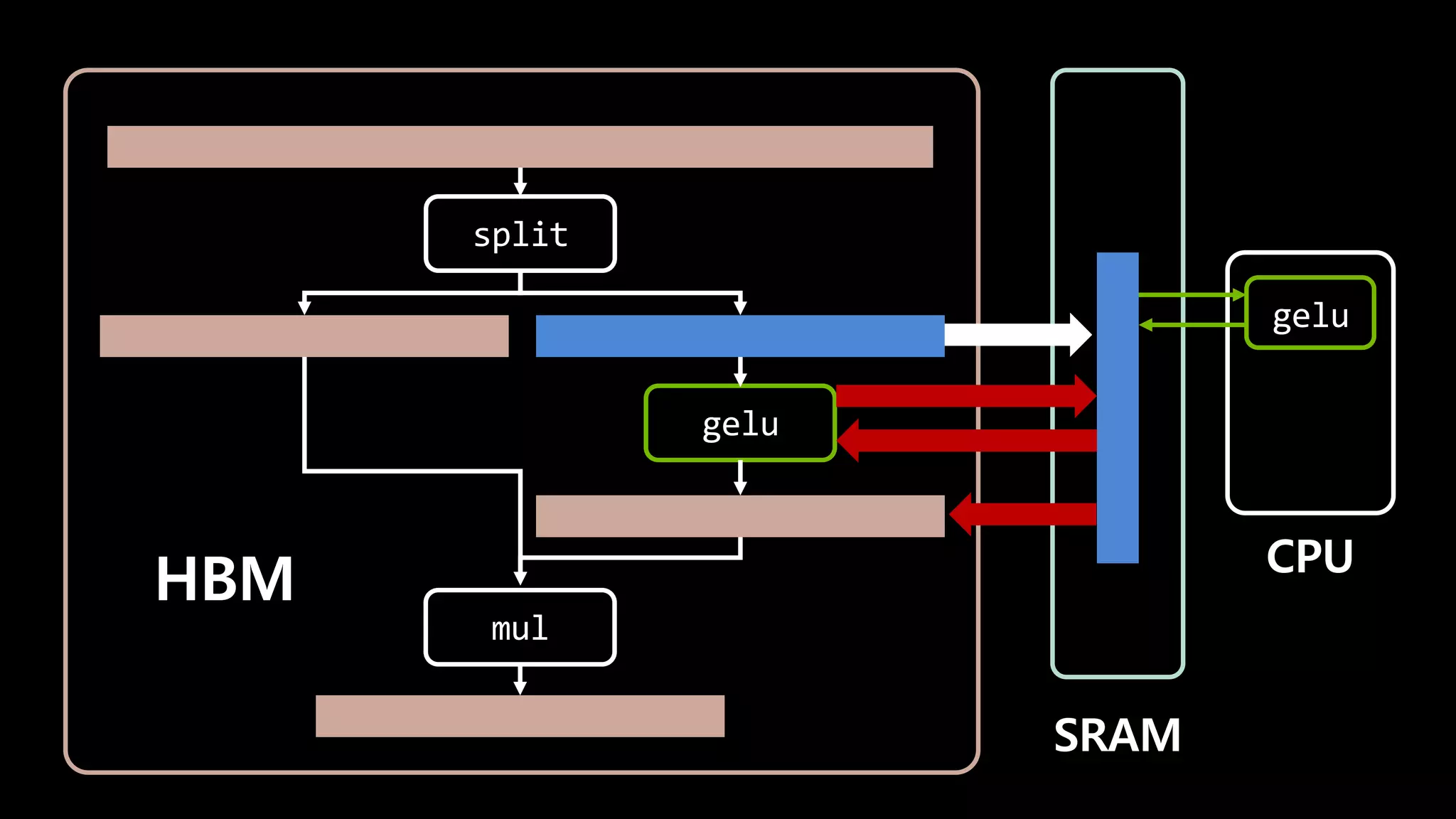
- 144. split gelu mul HBM SRAM CPU gelu copy
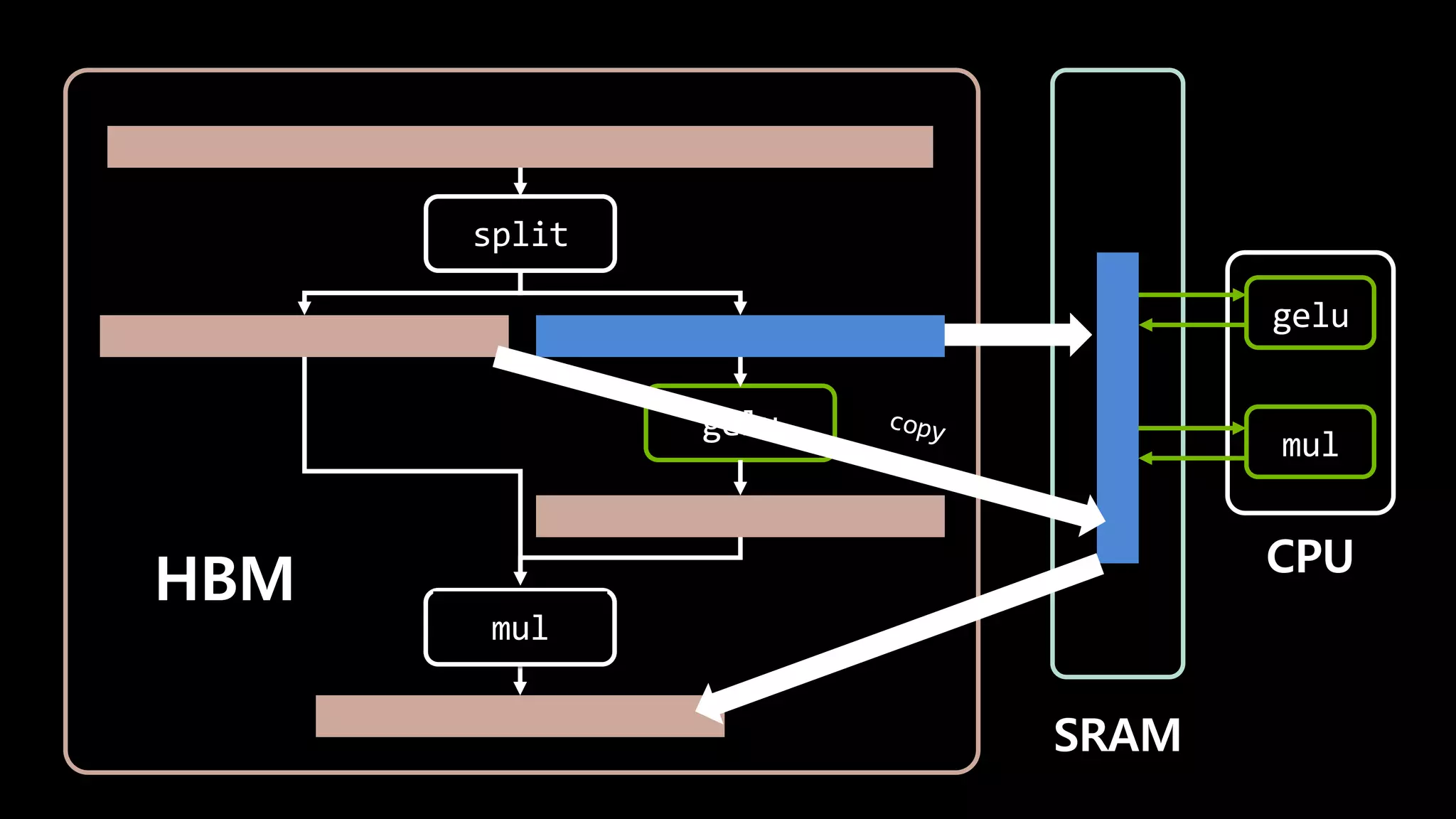
- 145. split gelu mul HBM SRAM gelu CPU
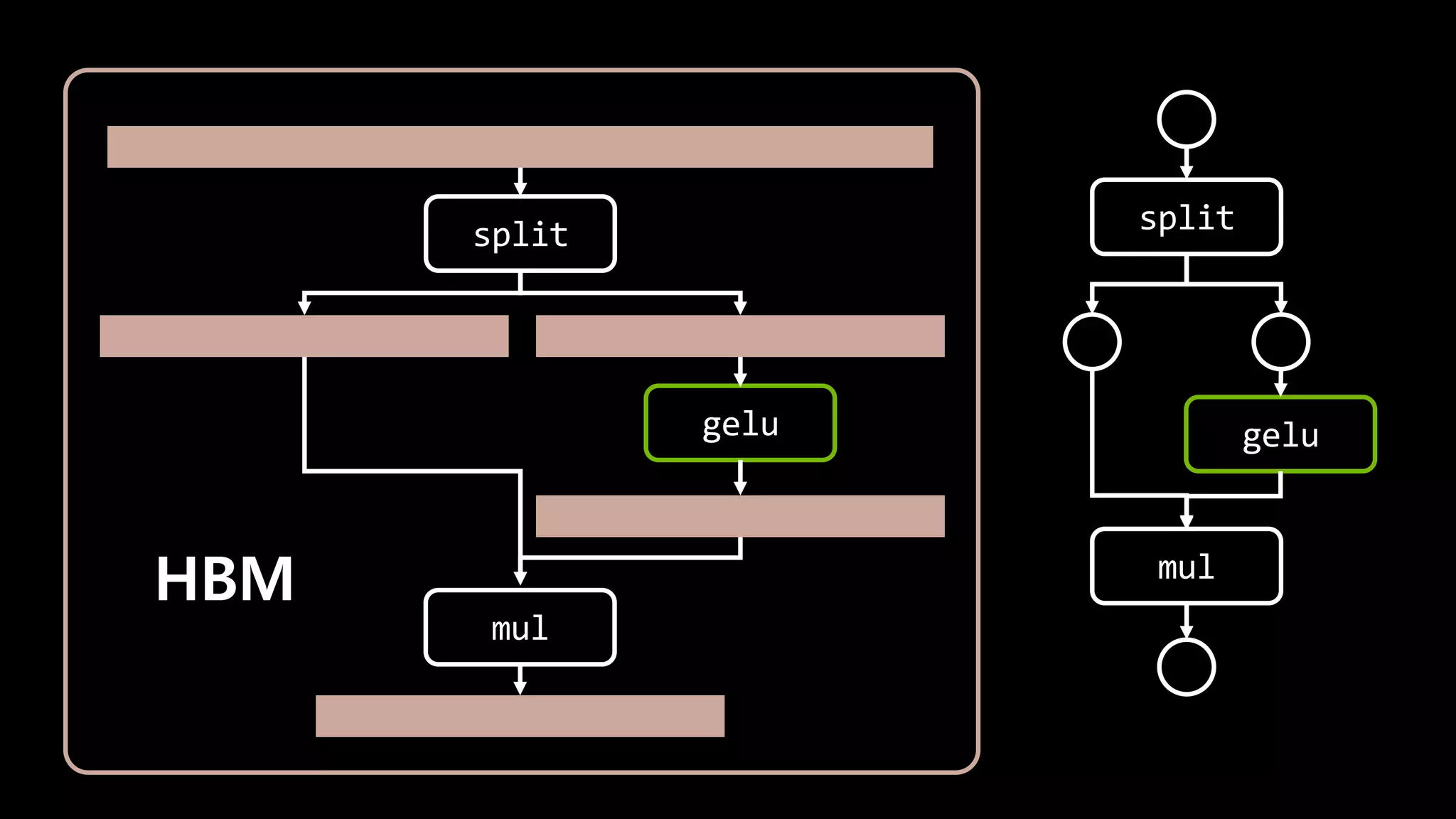
- 146. split gelu HBM SRAM gelu CPU copy mul mul
- 147. I/O가 7번 일어날 걸 1번으로 줄일 수 있다
- 148. I/O가 7번 일어날 걸 1번으로 줄일 수 있다
- 149. 가 최적화 하지 못하는 코드를 triton class GEGLU(nn.Module): def forward(self, x): x, gate = x.chunk(2, dim=-1) return x * F.gelu(gate)
- 150. OpenAI가 만든 언어 및 컴파일러 I/O 최적화된 op을 만들어 최적화
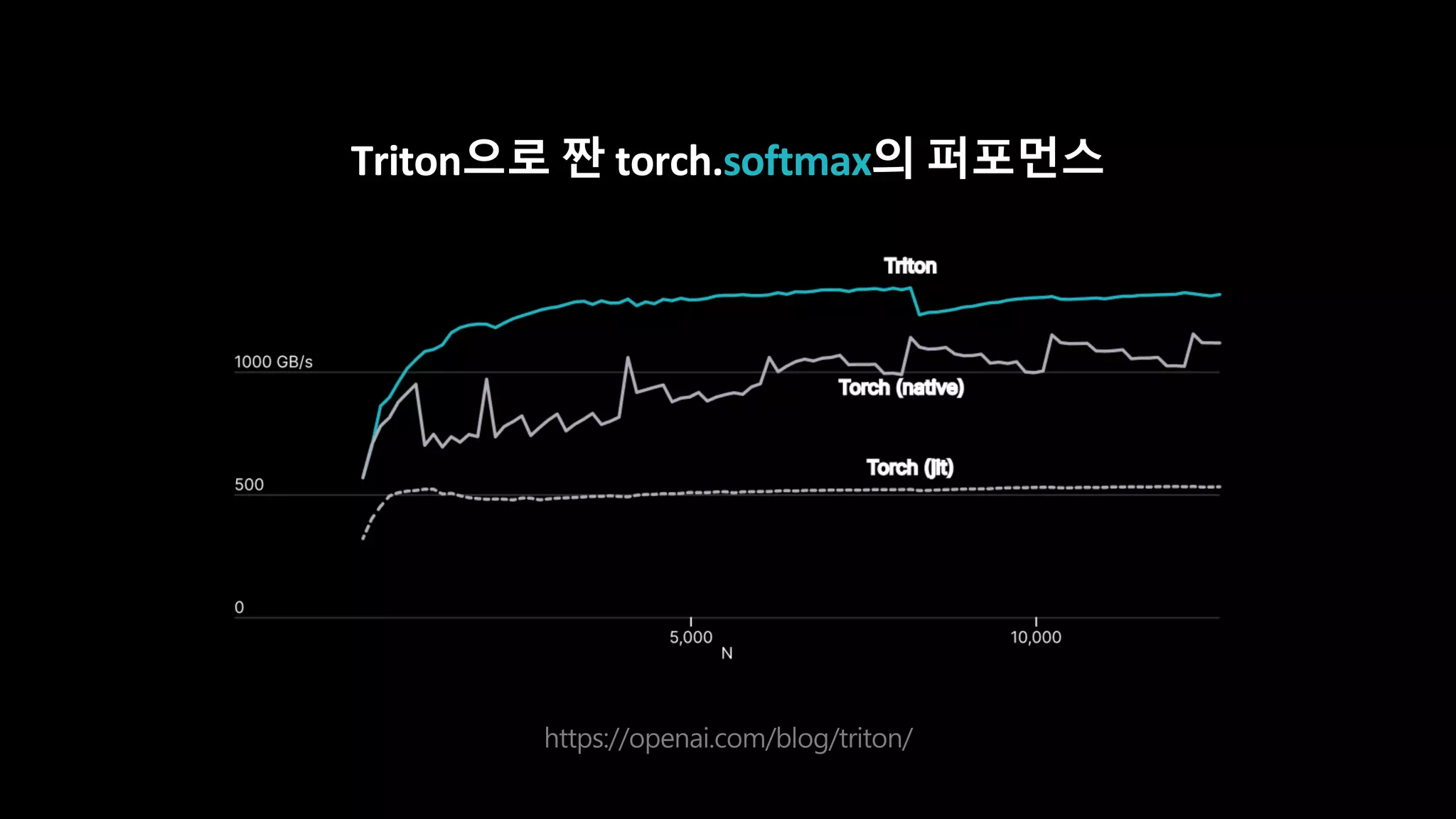
- 151. OpenAI가 만든 언어 및 컴파일러 I/O 최적화된 CUDA 코드를 최적화
- 152. https://openai.com/blog/triton/ Triton으로 짠 torch.softmax의 퍼포먼스
- 153. swish, gelu groupnorm layernorm cast … triton
- 154. Latency (sec) Latency Vanila FlashAttention FP16 Distillation TensorRT triton
- 155. 1. Distillation 2. TensorRT & triton
- 156. 빨라진 Diffusion model
- 157. 어떤 인프라로 서빙하고 있는가
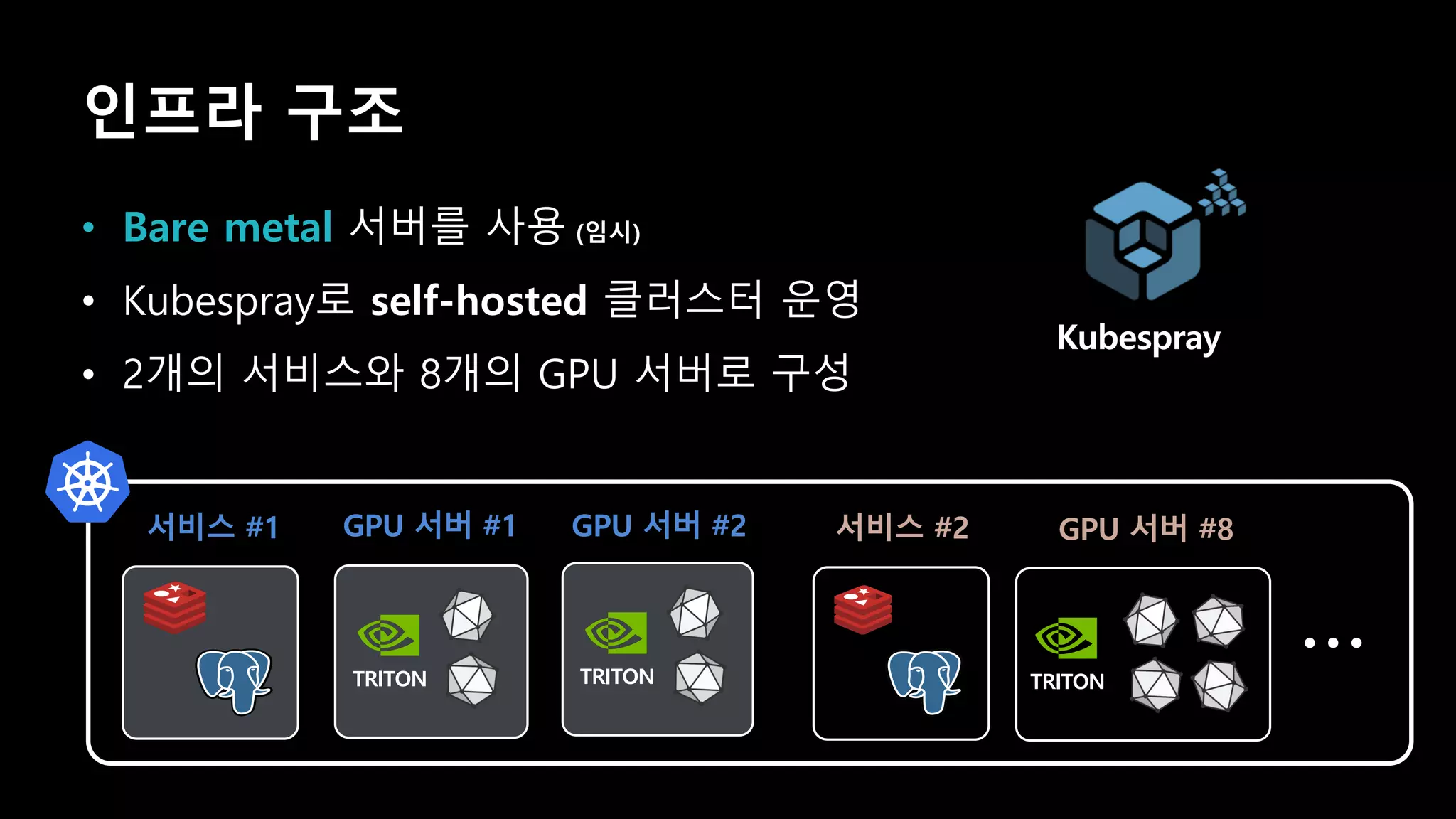
- 158. 인프라 구조 • Bare metal 서버를 사용 (임시) • Kubespray로 self-hosted 클러스터 운영 • 2개의 서비스와 8개의 GPU 서버로 구성 Kubespray 서비스 #1 GPU 서버 #2 TRITON GPU 서버 #1 TRITON GPU 서버 #8 TRITON 서비스 #2
- 159. 모델 서빙 관리 = TRITON Inference Server
- 160. TRITON 의 장점 • Ensemble Models, Scheduler 및 dlpack • TensorRT • GRPC • Dynamic Batching TRITON INFERNCE SERVER
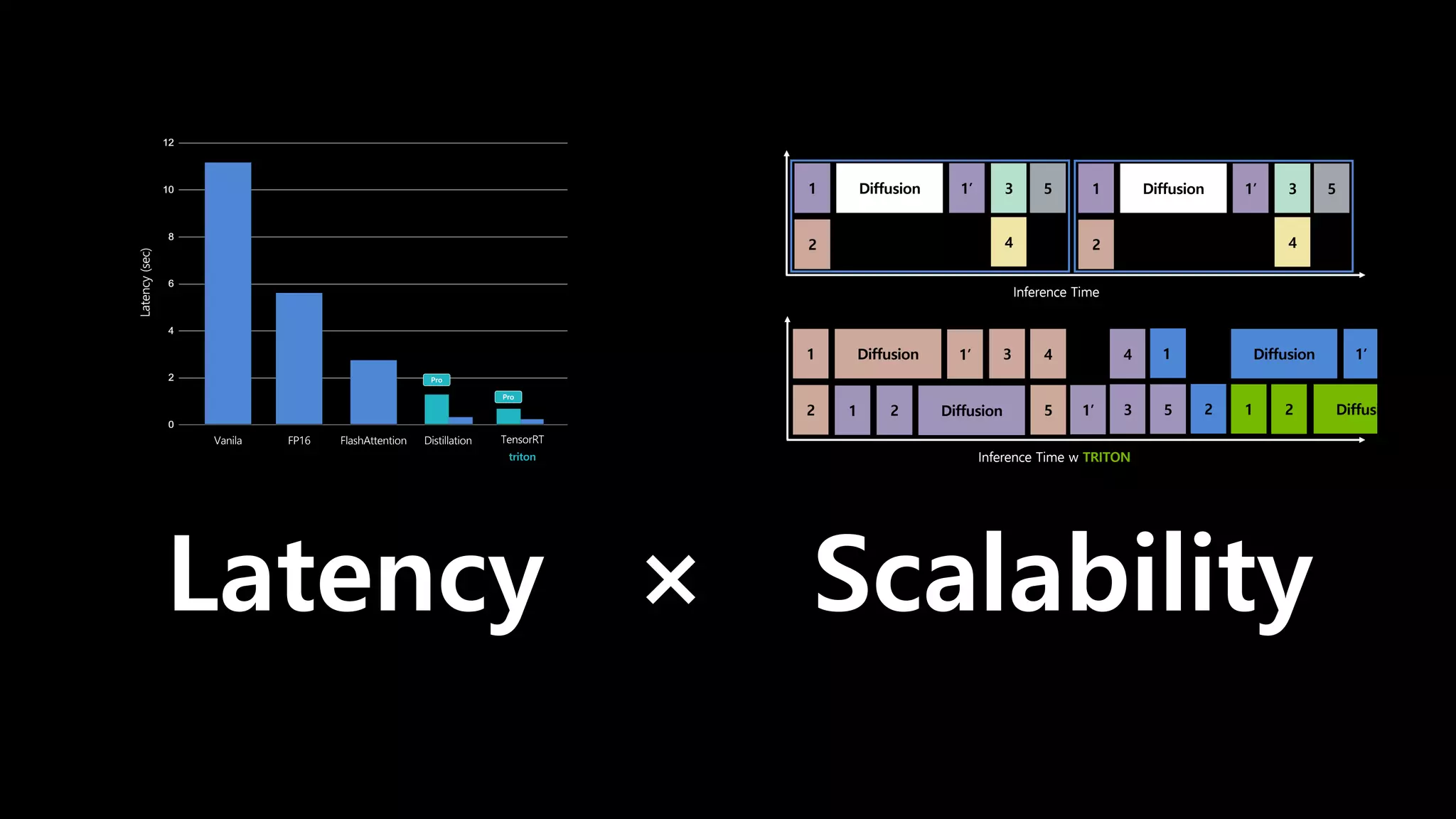
- 161. TRITON 의 장점 • Ensemble Models, Scheduler 및 dlpack • TensorRT • GRPC • Dynamic Batching TRITON INFERNCE SERVER
- 162. Latency Vanila FlashAttention FP16 Distillation TensorRT triton Latency (sec) ×3
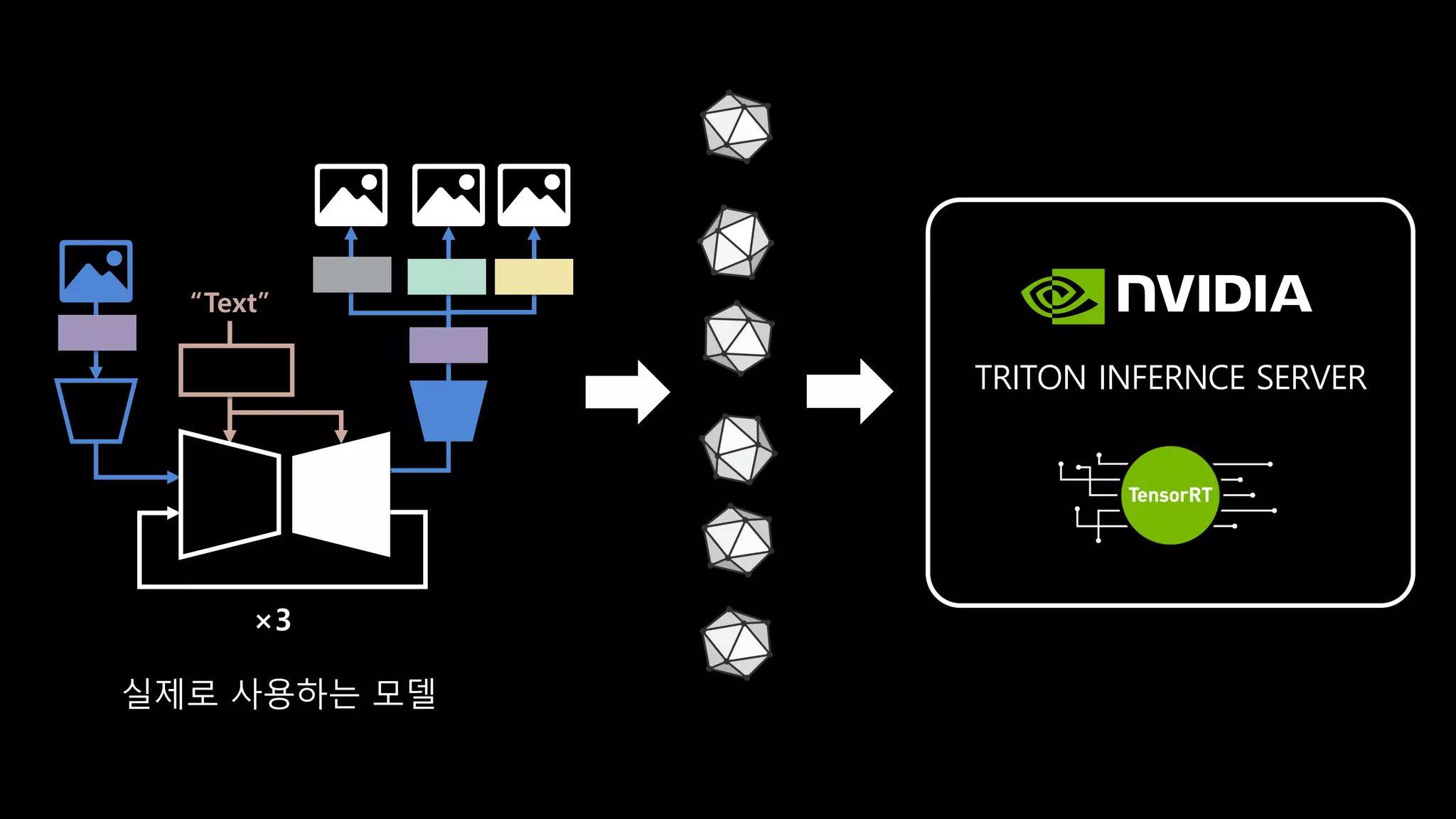
- 163. ×3 왜 이렇게까지..?
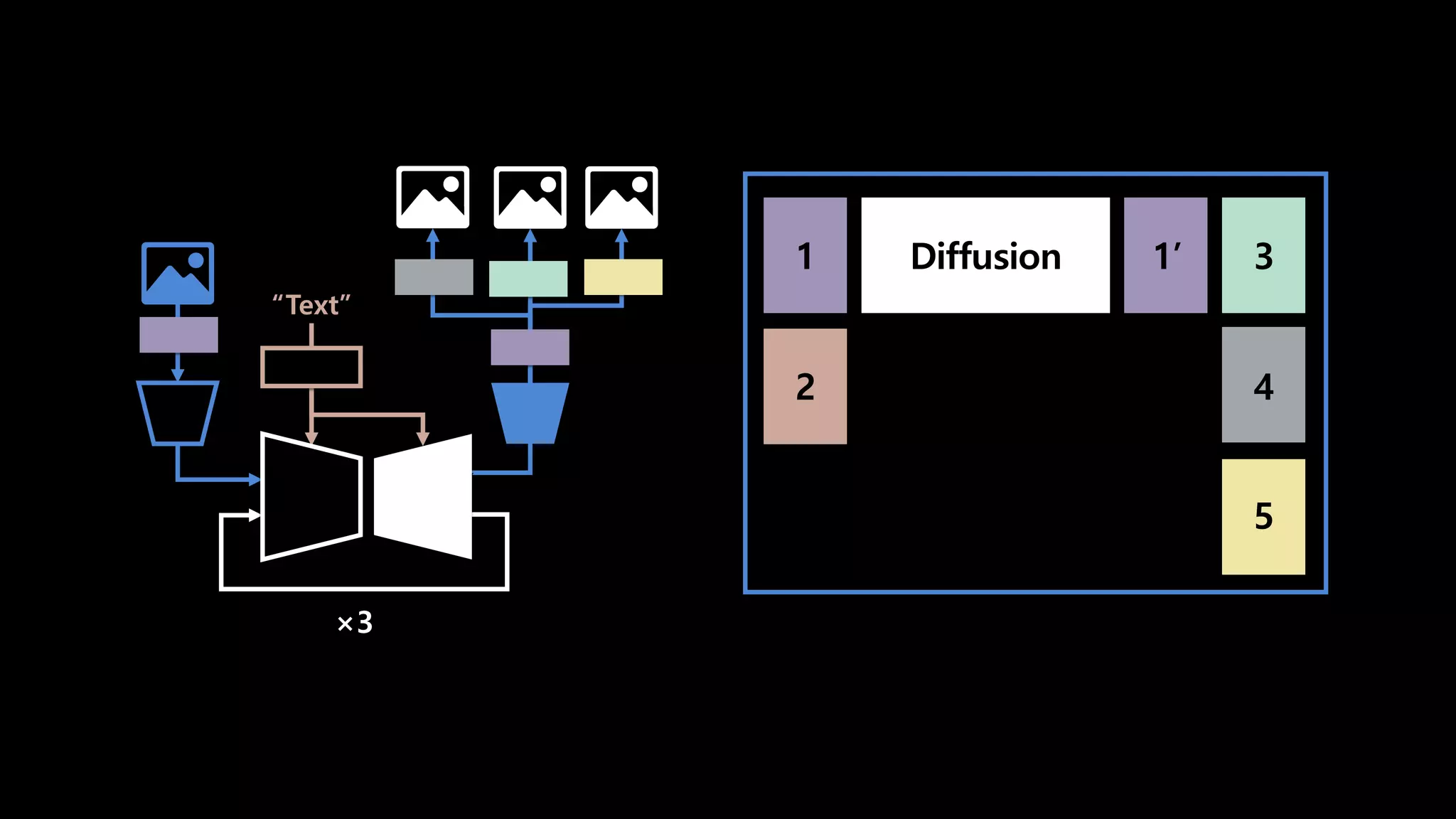
- 164. ×3 “Text” TRITON INFERNCE SERVER 실제로 사용하는 모델
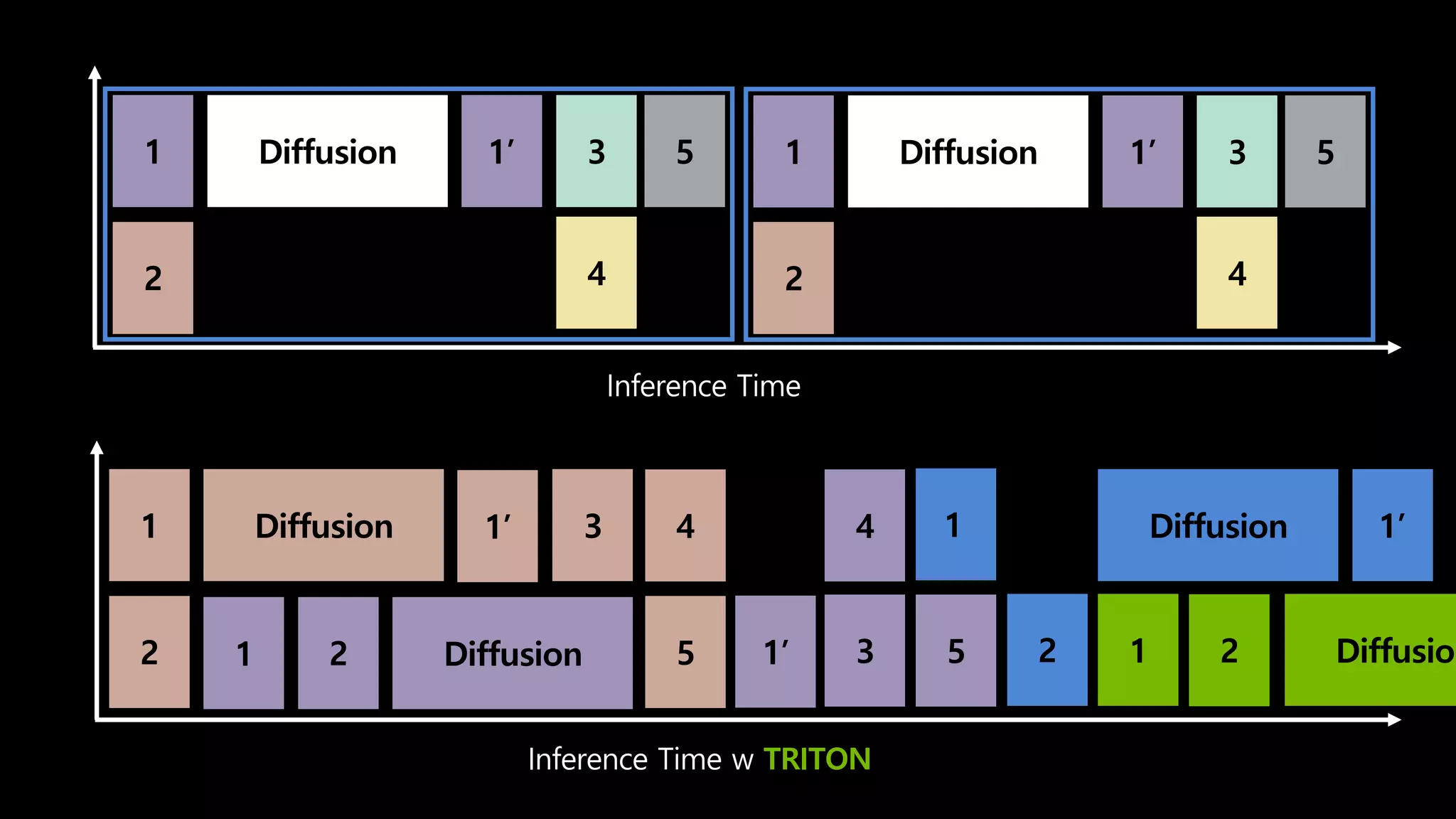
- 165. 1 2 1’ Diffusion “Text” ×3 3 4 5
- 166. 단순화를 위해 GPU 하나에 동시 실행 가능한 모델 = 2개
- 167. Inference Time 1 2 1’ Diffusion 3 4 5 1 2 1’ Diffusion 3 4 5
- 168. Diffusion 1 1 2 Inference Time Inference Time w TRITON 1 2 1’ Diffusion 3 4 5 1 2 1’ Diffusion 3 4 5 3 2 Diffusion 4 5 1’ 1’ 1 3 1 4 5 2 1 2 1’ Diffusion 1 Diffusion 2
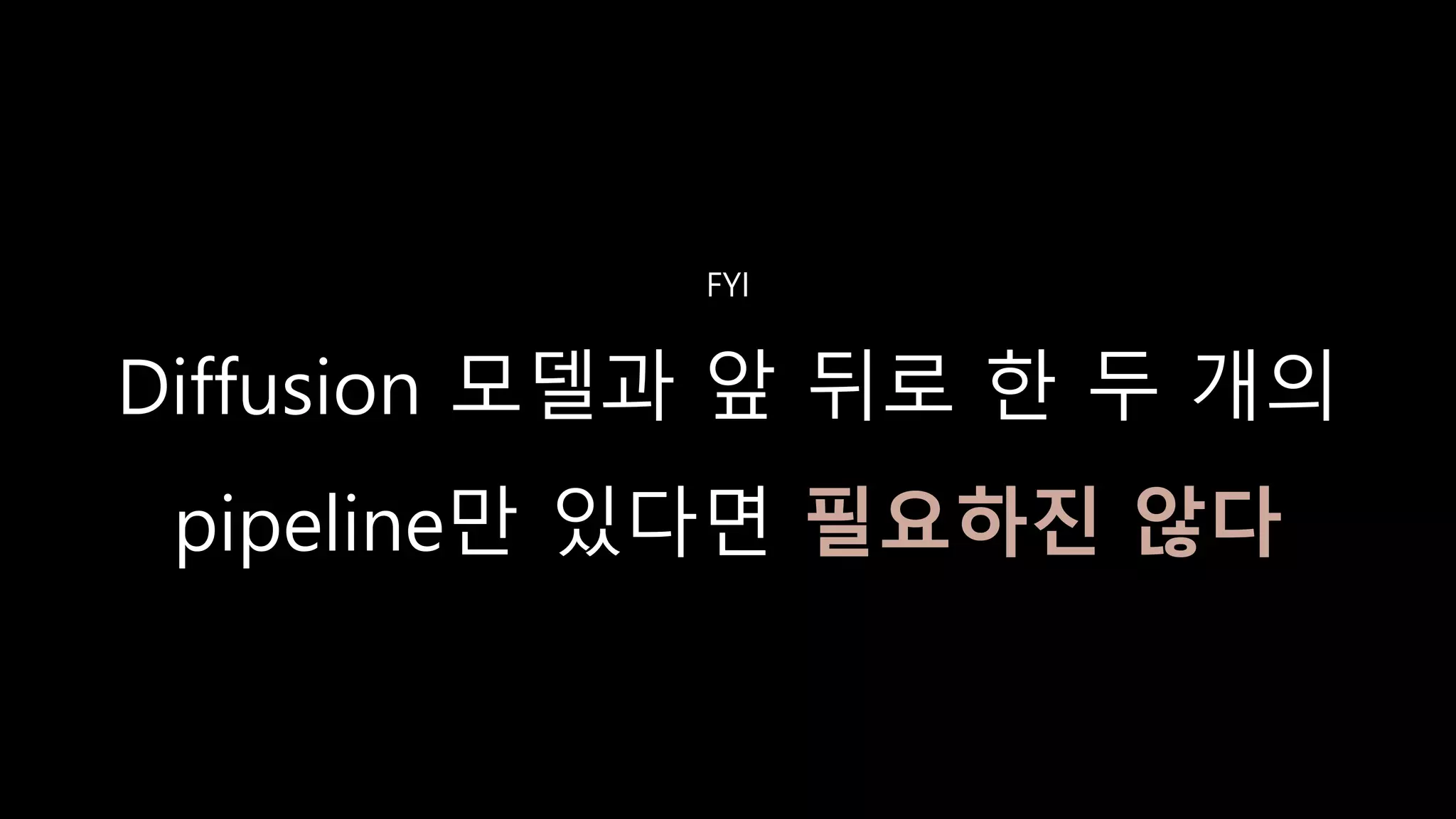
- 169. https://openai.com/blog/techniques-for-training-large-neural-networks/
- 170. FYI Diffusion 모델과 앞 뒤로 한 두 개의 pipeline만 있다면 필요하진 않다
- 171. 그래서
- 172. 값비싼 Diffusion model을 받드는 저비용 MLOps
- 173. Latency × Scalability
- 174. 네
- 175. 값비싼 Diffusion model를 받드는 저비용 MLOps
- 176. 값비싼 Diffusion model를 받드는 저비용 MLOps
- 177. 값비싼 Diffusion model를 받드는 저비용 MLOps
- 178. 값비싼 Diffusion model를 받드는 저비용 MLOps
- 179. 마지막으로
- 180. 남들과 똑같은 정보만 보고 듣고 행동하면 그 어떠한 혁신도 만들어내지 못합니다
- 181. 저는 AI에 대한 집념으로 2018년 로부터 합류 제의를 받았고 한국에서 학부를 마치고 미국으로가 2년 간 세계 최고의 인재들과 함께 AI 개발을 했습니다
- 182. 2021년 Symbiote AI 기술로 만든 3D 모델들 3년 전 OpenAI를 퇴사하고 Generative AI로 어떤 가치와 시장을 혁신할 수 있을지 고민해 왔습니다
- 183. 작년 1월부터 작고 뾰족한 시장에서 시작해 광고 없이 37만 명의 글로벌 유저를 모았고 유저와 끊임 없이 대화하며 타겟 시장과 심리를 깊게 이해해 왔습니다 https://bit.ly/retrospect-virtu
- 184. Symbiote AI는 Global, Technology, Service 기업을 지향하며 기술적 격차와 유저 중심의 제품으로 Day 1부터 글로벌 서비스로 저희 자신의 가치를 증명하고자 합니다
- 185. 자신의 가치를 역사에 증명하기 위해 살아가는 분들과 불가능을 이뤄내고 싶습니다. 관심 있는 분은 편하게 연락주세요! Mail: taehoon@symbiote-ai.com
- 186. 지난 3년간 저희가 밟아 왔던 발자취는 https://bit.ly/retrospect-virtu 에서 보실 수 있습니다
- 187. symbiote-ai.com
- 188. 감사합니다
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
반응형
'IT 둘러보기' 카테고리의 다른 글
| 스타트업은 데이터를 어떻게 바라봐야 할까? (개정판) (0) | 2023.03.14 |
|---|---|
| 코로나19로 인해 변화된 우리 시대의 데이터 트랜드 (1) | 2023.03.14 |
| 메타버스 서비스에 Android 개발자가 할 일이 있나요? (1) | 2023.03.13 |
| 스마트폰 위의 딥러닝 (3) | 2023.03.13 |
| 책 읽어주는 딥러닝: 배우 유인나가 해리포터를 읽어준다면 (1) | 2023.03.13 |
| Material design 3분 만에 살펴보기 (0) | 2023.03.10 |
| 넷플릭스의 문화 : 자유와 책임 (한국어 번역본) (1) | 2023.03.10 |
| 버전관리를 들어본적 없는 사람들을 위한 DVCS - Git (0) | 2023.03.10 |