반응형
스마트폰 위의 딥러닝
- 1. 스마트폰 위의 딥러닝 신범준 HYPERCONNECT 이 슬라이드는 네이버에서 제공한 나눔글꼴이 적용되어있습니다
- 2. 하이퍼커넥트의 머신러닝 성과
- 3. 하이퍼커넥트의 머신러닝 성과 PaaS 신고 이미지 검수 (클라우드)
- 4. 하이퍼커넥트의 머신러닝 성과 PaaS 신고 이미지 검수 (클라우드) 이미지 분류기 (모바일)
- 5. 하이퍼커넥트의 머신러닝 성과 실시간 배경따기 (모바일) PaaS 신고 이미지 검수 (클라우드) 이미지 분류기 (모바일)
- 6. 작은 딥러닝 모델을 잘 만들어 모바일에 배포해본 이야기 오늘의 주제
- 7. 왜 모바일 딥러닝?
- 8. 왜 모바일 딥러닝? 높은 지연 시간
- 9. 왜 모바일 딥러닝? 높은 지연 시간 낮은 대역폭
- 10. 왜 모바일 딥러닝? 높은 지연 시간 오프라인 낮은 대역폭
- 11. 왜 모바일 딥러닝? 높은 지연 시간 수 많은 기기 오프라인 낮은 대역폭
- 12. 왜 모바일 딥러닝? 프라이버시 높은 지연 시간 수 많은 기기 오프라인 낮은 대역폭
- 13. 가능한 응용
- 14. 가능한 응용 스마트폰
- 15. 가능한 응용 무인자동차스마트폰
- 16. 가능한 응용 무인자동차스마트폰 드론
- 17. 가능한 응용 무인자동차스마트폰 드론 VR/AR
- 18. 가능한 응용 무인자동차스마트폰 드론 VR/AR IOT
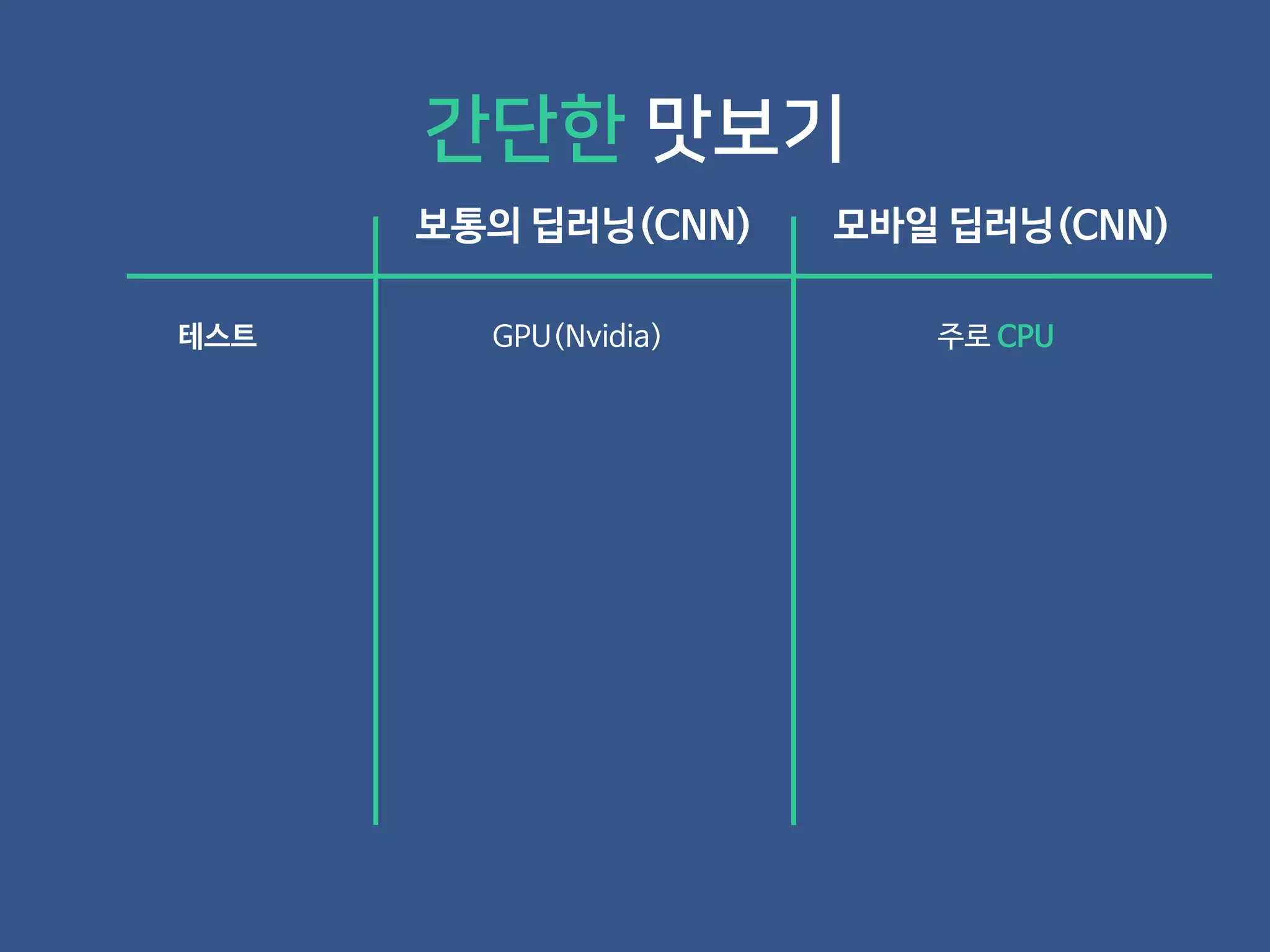
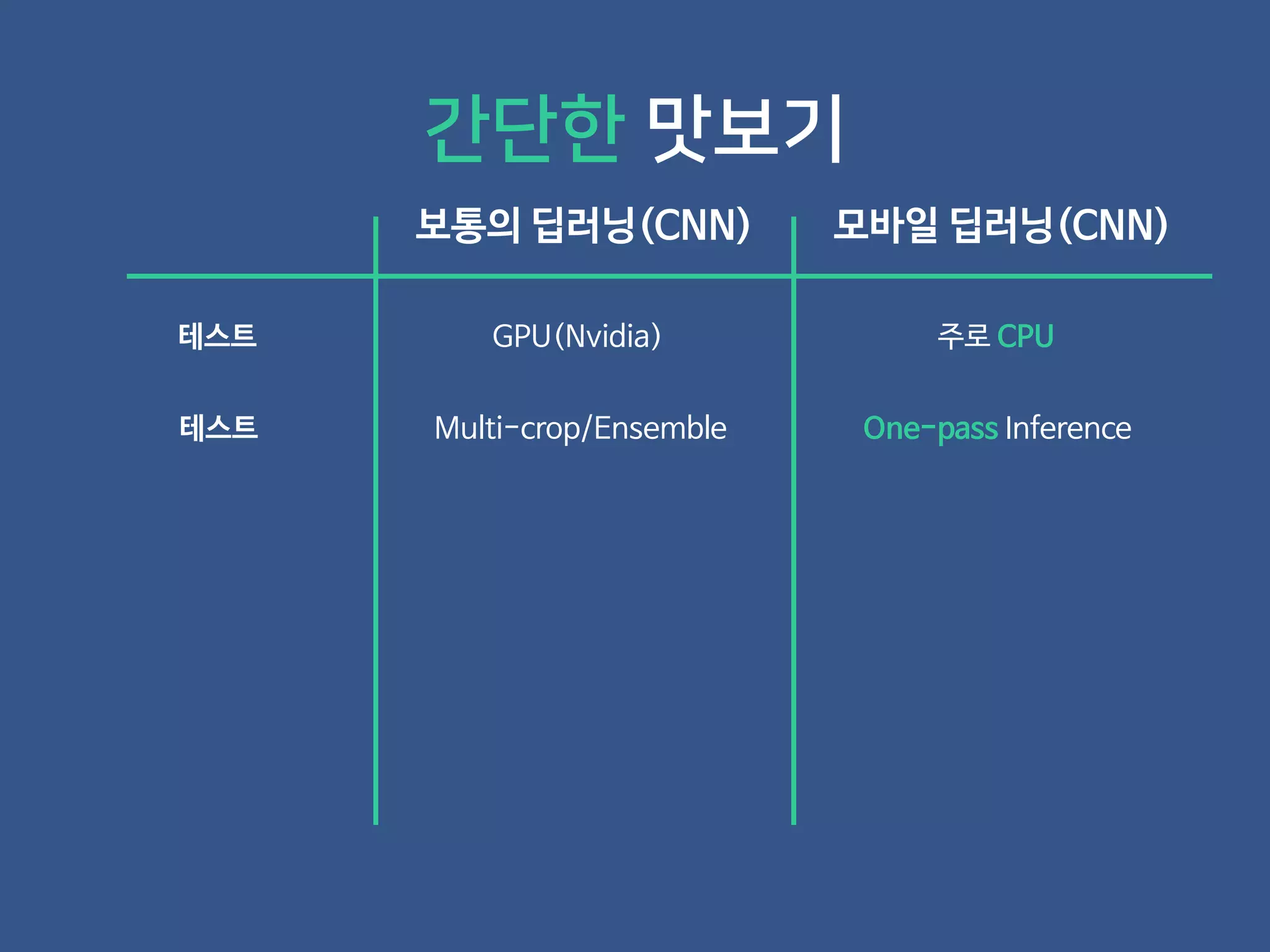
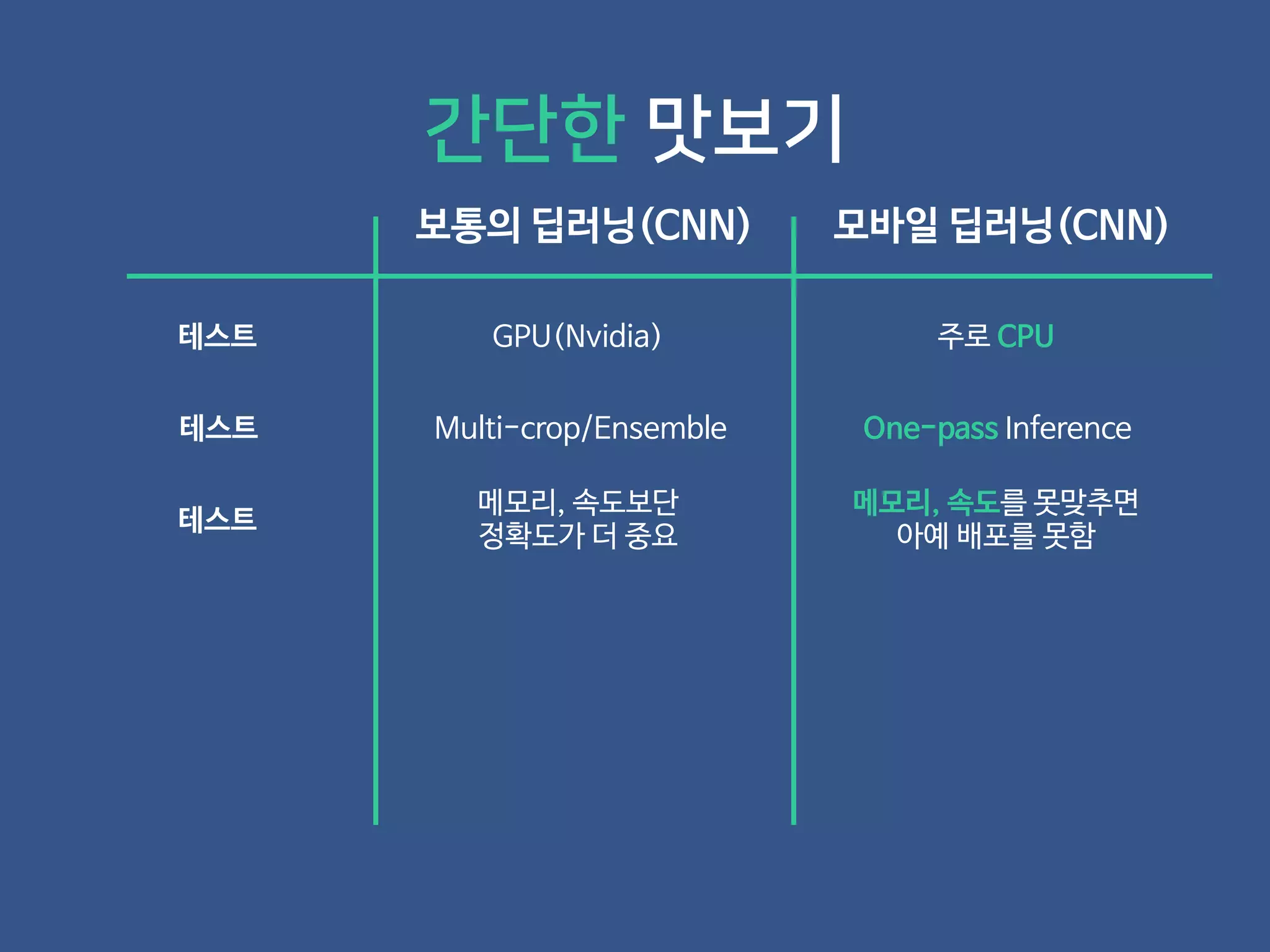
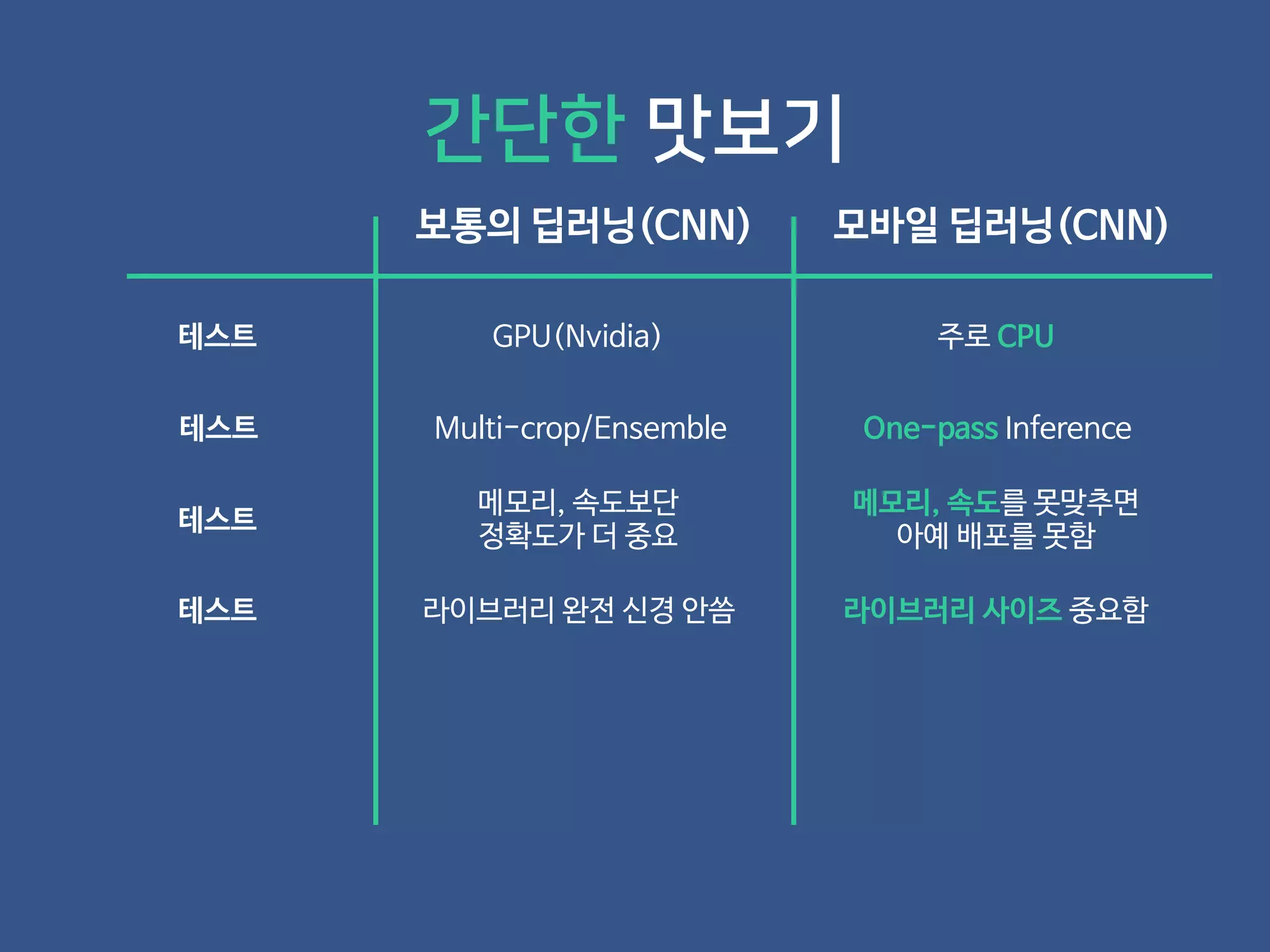
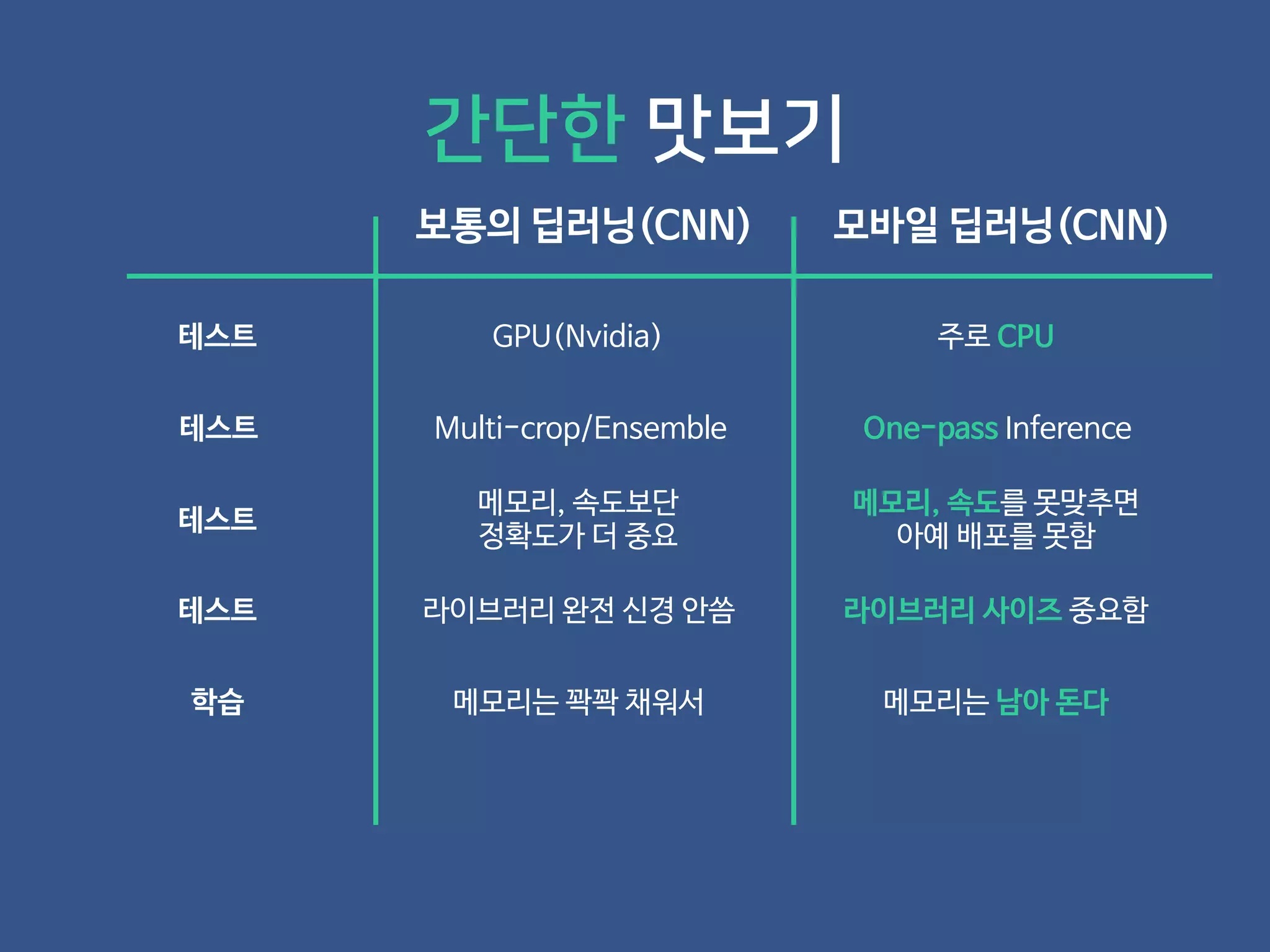
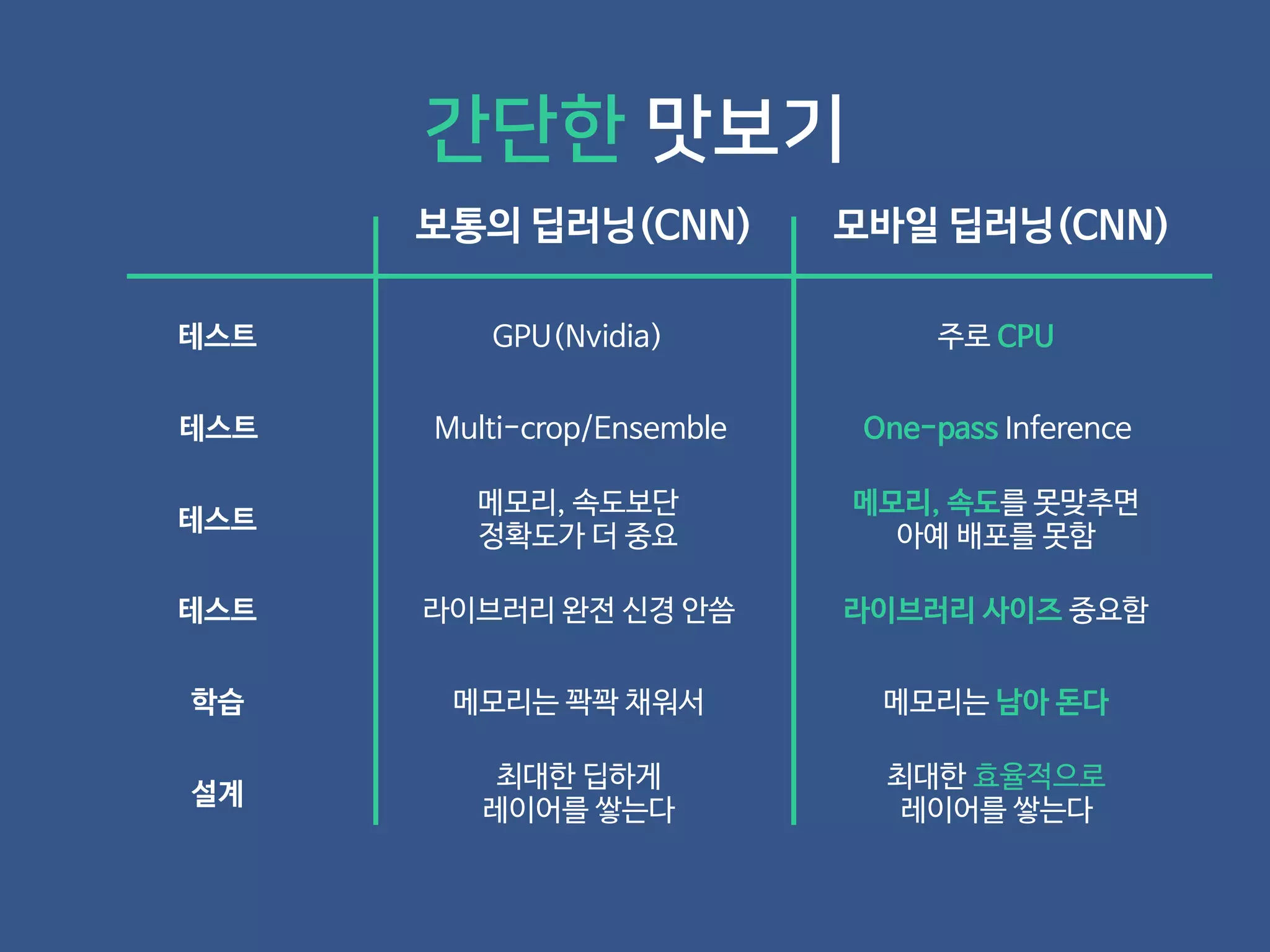
- 19. 보통의 딥러닝(CNN) 모바일 딥러닝(CNN) 간단한 맛보기
- 20. 보통의 딥러닝(CNN) 모바일 딥러닝(CNN) 테스트 GPU(Nvidia) 주로 CPU 간단한 맛보기
- 21. 보통의 딥러닝(CNN) 모바일 딥러닝(CNN) 테스트 GPU(Nvidia) 주로 CPU 테스트 Multi-crop/Ensemble One-pass Inference 간단한 맛보기
- 22. 보통의 딥러닝(CNN) 모바일 딥러닝(CNN) 테스트 GPU(Nvidia) 주로 CPU 테스트 Multi-crop/Ensemble One-pass Inference 간단한 맛보기 테스트 메모리, 속도보단 정확도가 더 중요 메모리, 속도를 못맞추면 아예 배포를 못함
- 23. 보통의 딥러닝(CNN) 모바일 딥러닝(CNN) 테스트 GPU(Nvidia) 주로 CPU 테스트 Multi-crop/Ensemble One-pass Inference 간단한 맛보기 테스트 메모리, 속도보단 정확도가 더 중요 메모리, 속도를 못맞추면 아예 배포를 못함 테스트 라이브러리 완전 신경 안씀 라이브러리 사이즈 중요함
- 24. 보통의 딥러닝(CNN) 모바일 딥러닝(CNN) 테스트 GPU(Nvidia) 주로 CPU 테스트 Multi-crop/Ensemble One-pass Inference 학습 메모리는 꽉꽉 채워서 메모리는 남아 돈다 간단한 맛보기 테스트 메모리, 속도보단 정확도가 더 중요 메모리, 속도를 못맞추면 아예 배포를 못함 테스트 라이브러리 완전 신경 안씀 라이브러리 사이즈 중요함
- 25. 보통의 딥러닝(CNN) 모바일 딥러닝(CNN) 테스트 GPU(Nvidia) 주로 CPU 테스트 Multi-crop/Ensemble One-pass Inference 학습 메모리는 꽉꽉 채워서 메모리는 남아 돈다 설계 최대한 딥하게 레이어를 쌓는다 최대한 효율적으로 레이어를 쌓는다 간단한 맛보기 테스트 메모리, 속도보단 정확도가 더 중요 메모리, 속도를 못맞추면 아예 배포를 못함 테스트 라이브러리 완전 신경 안씀 라이브러리 사이즈 중요함
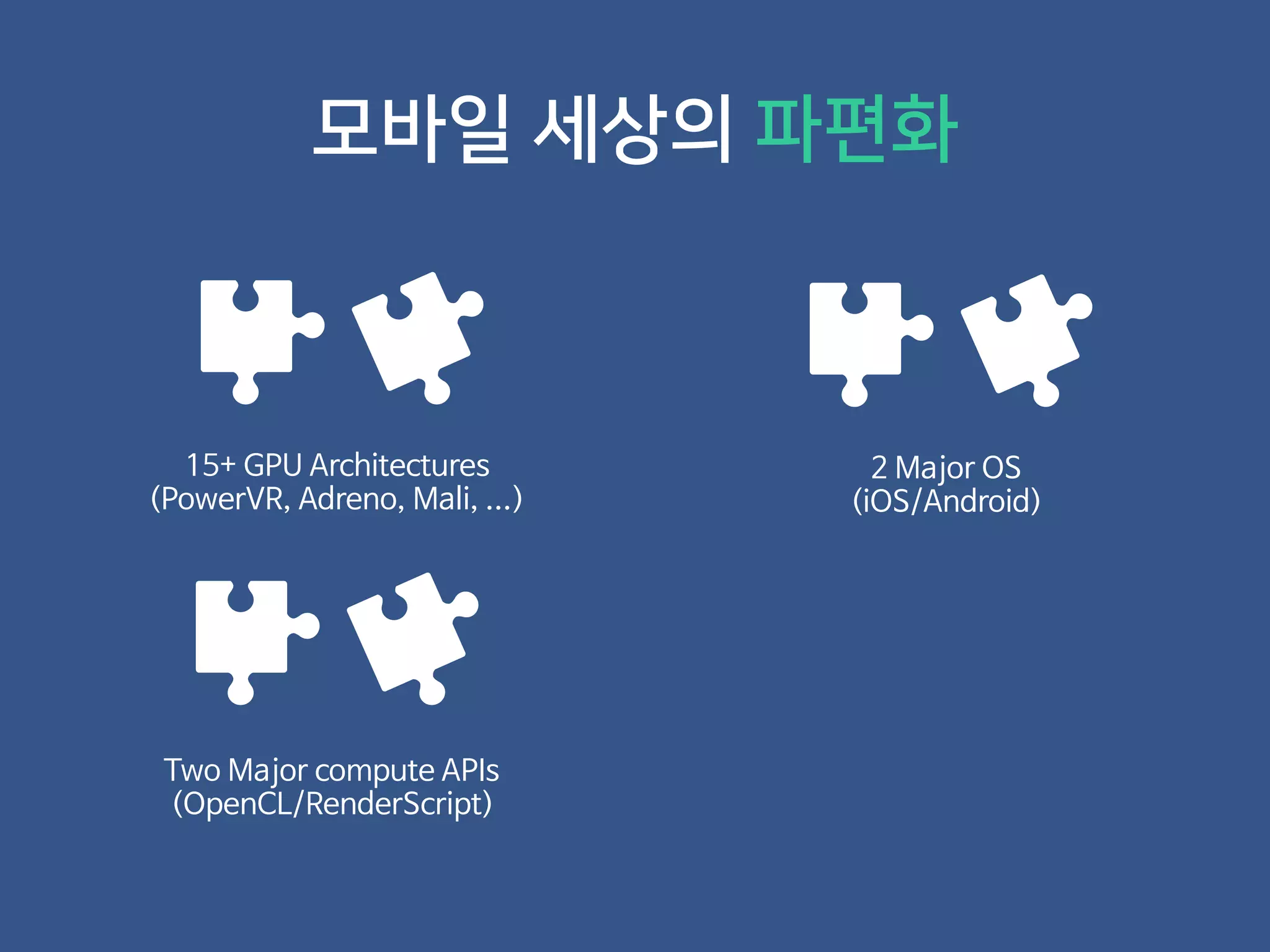
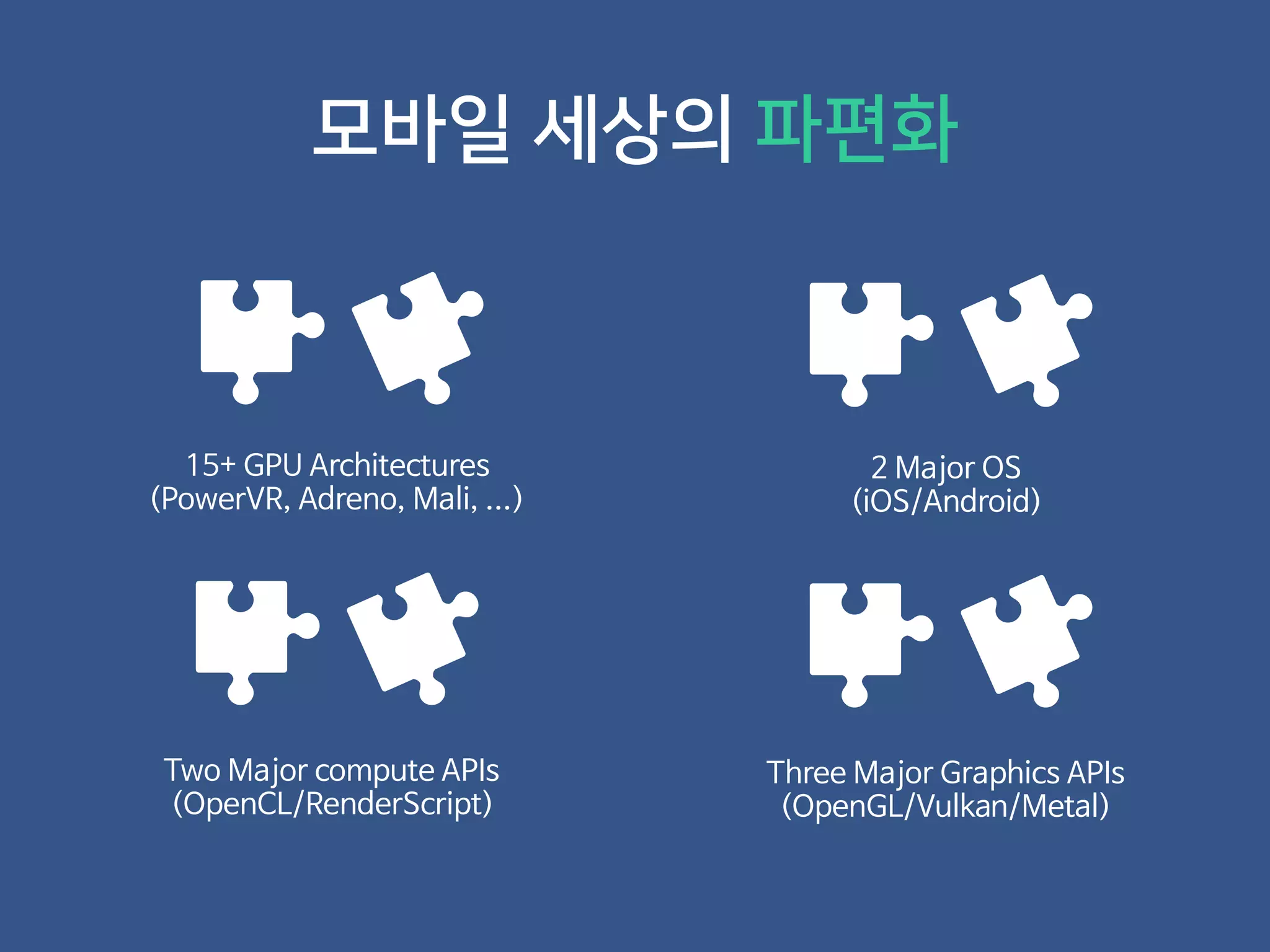
- 26. 모바일 세상의 파편화
- 27. 모바일 세상의 파편화 15+ GPU Architectures (PowerVR, Adreno, Mali, ...)
- 28. 모바일 세상의 파편화 15+ GPU Architectures (PowerVR, Adreno, Mali, ...) 2 Major OS (iOS/Android)
- 29. 모바일 세상의 파편화 15+ GPU Architectures (PowerVR, Adreno, Mali, ...) 2 Major OS (iOS/Android) Two Major compute APIs (OpenCL/RenderScript)
- 30. 모바일 세상의 파편화 15+ GPU Architectures (PowerVR, Adreno, Mali, ...) 2 Major OS (iOS/Android) Two Major compute APIs (OpenCL/RenderScript) Three Major Graphics APIs (OpenGL/Vulkan/Metal)
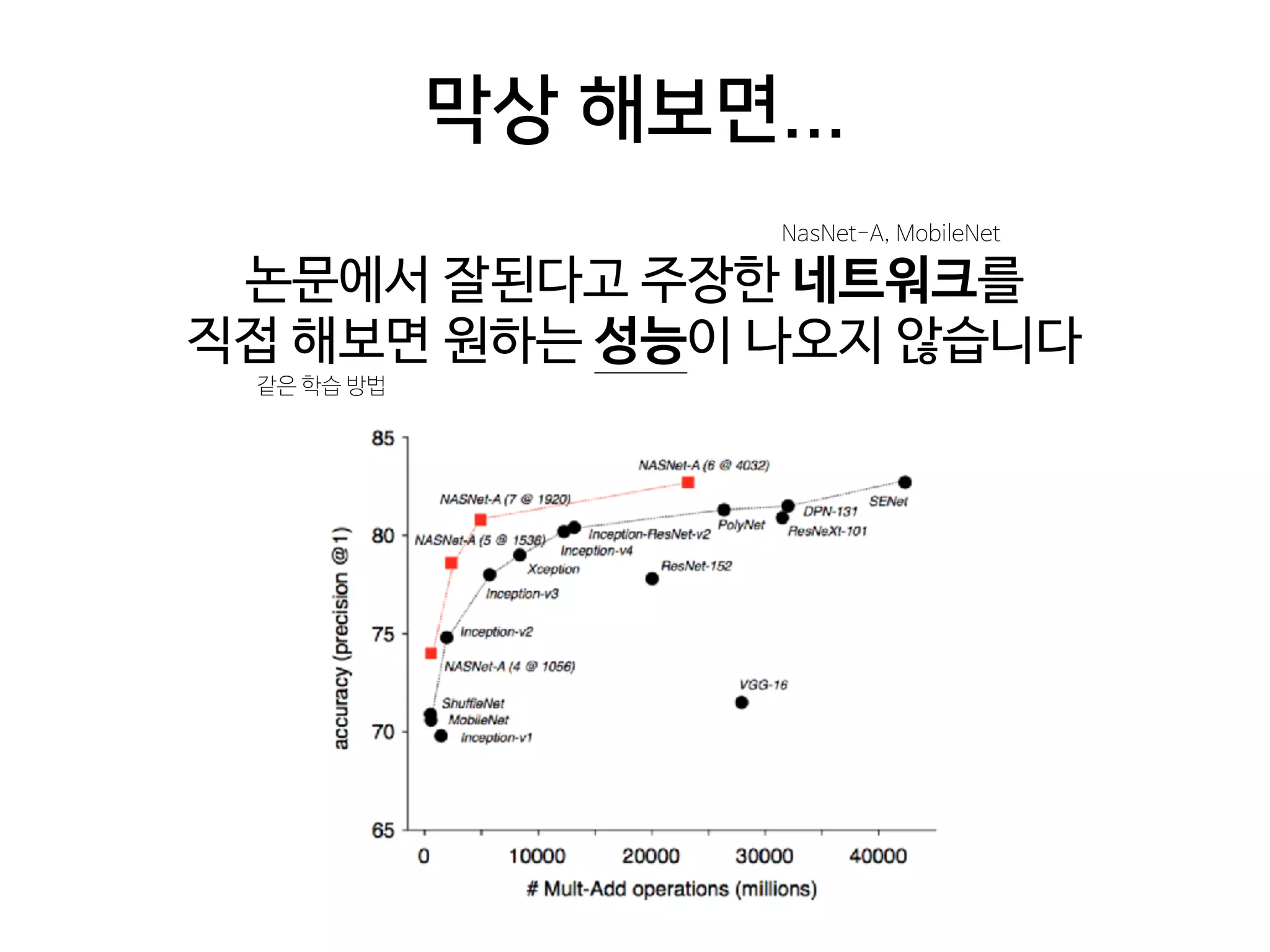
- 31. 막상 해보면... 논문에서 잘된다고 주장한 네트워크를 직접 해보면 원하는 성능이 나오지 않습니다 NasNet-A, MobileNet 같은 학습 방법
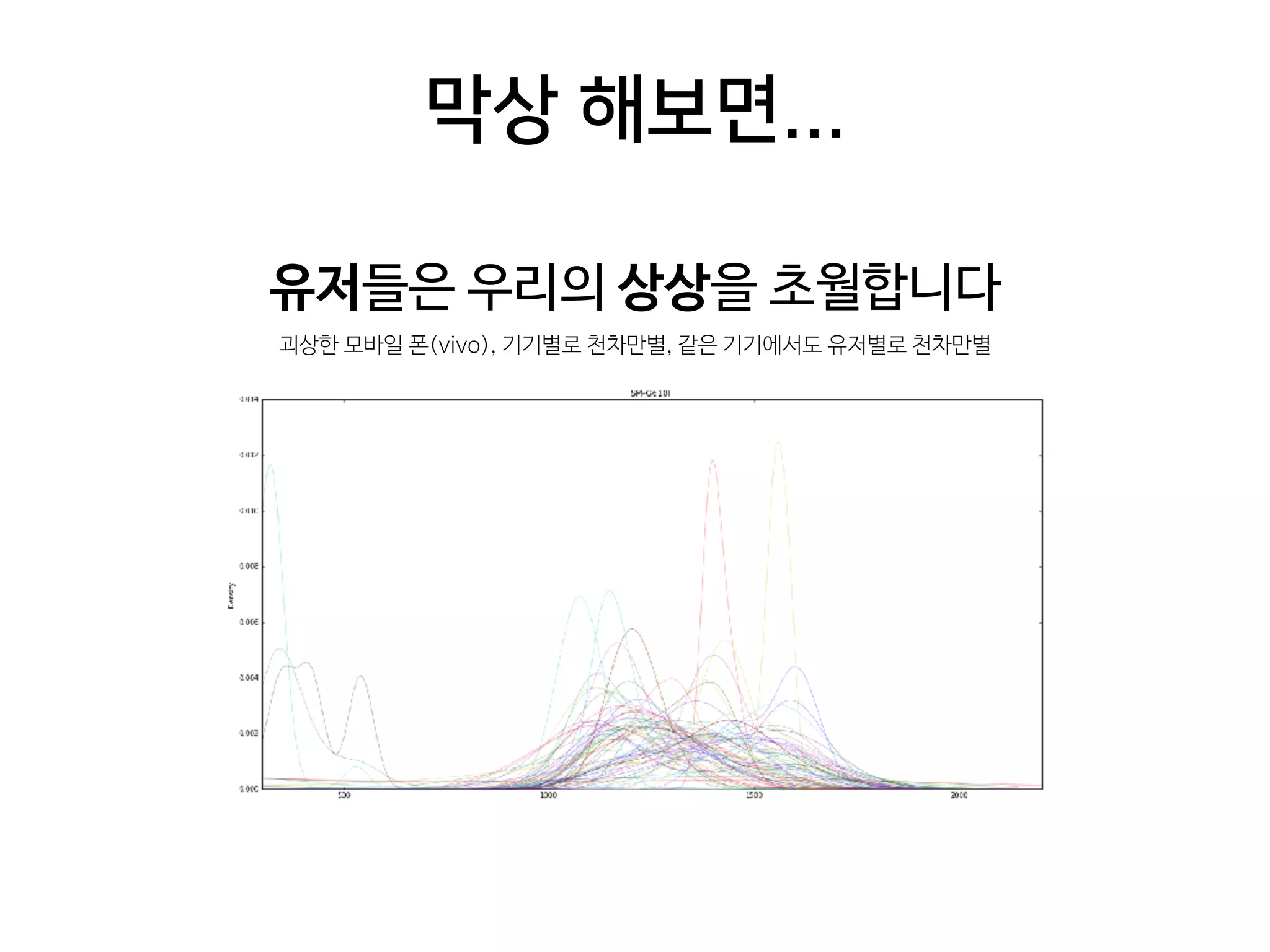
- 32. 막상 해보면... 유저들은 우리의 상상을 초월합니다 괴상한 모바일 폰(vivo), 기기별로 천차만별, 같은 기기에서도 유저별로 천차만별
- 33. 막상 해보면... 완벽한 데이터셋을 가지는건 항상 힘듭니다 Class Imbalance Problem, 좋은 평가지표, End-to-End 테스트 환경
- 34. 막상 해보면... 용량은 작고 속도는 빠르며 정확도는 높아야 합니다 그리고 배터리도 적게 쓰면 좋아요 iOS cellular download limit 150MB(2017.09.17)
- 35. 풀어야할 문제는 크게 2가지입니다
- 36. 용량을 적게 쓰고 속도가 빠르면서 예측 정확도가 높은 모델 만들기1. 딥러닝 모델을 효율적으로 구현하고 안정적으로 운영하기2.
- 37. 용량을 적게 쓰고 속도가 빠르면서 예측 정확도가 높은 모델 만들기1. 딥러닝 모델을 효율적으로 구현하고 안정적으로 운영하기2.
- 38. 유명한 모바일 딥러닝 아키텍쳐를 같이 살펴봅시다
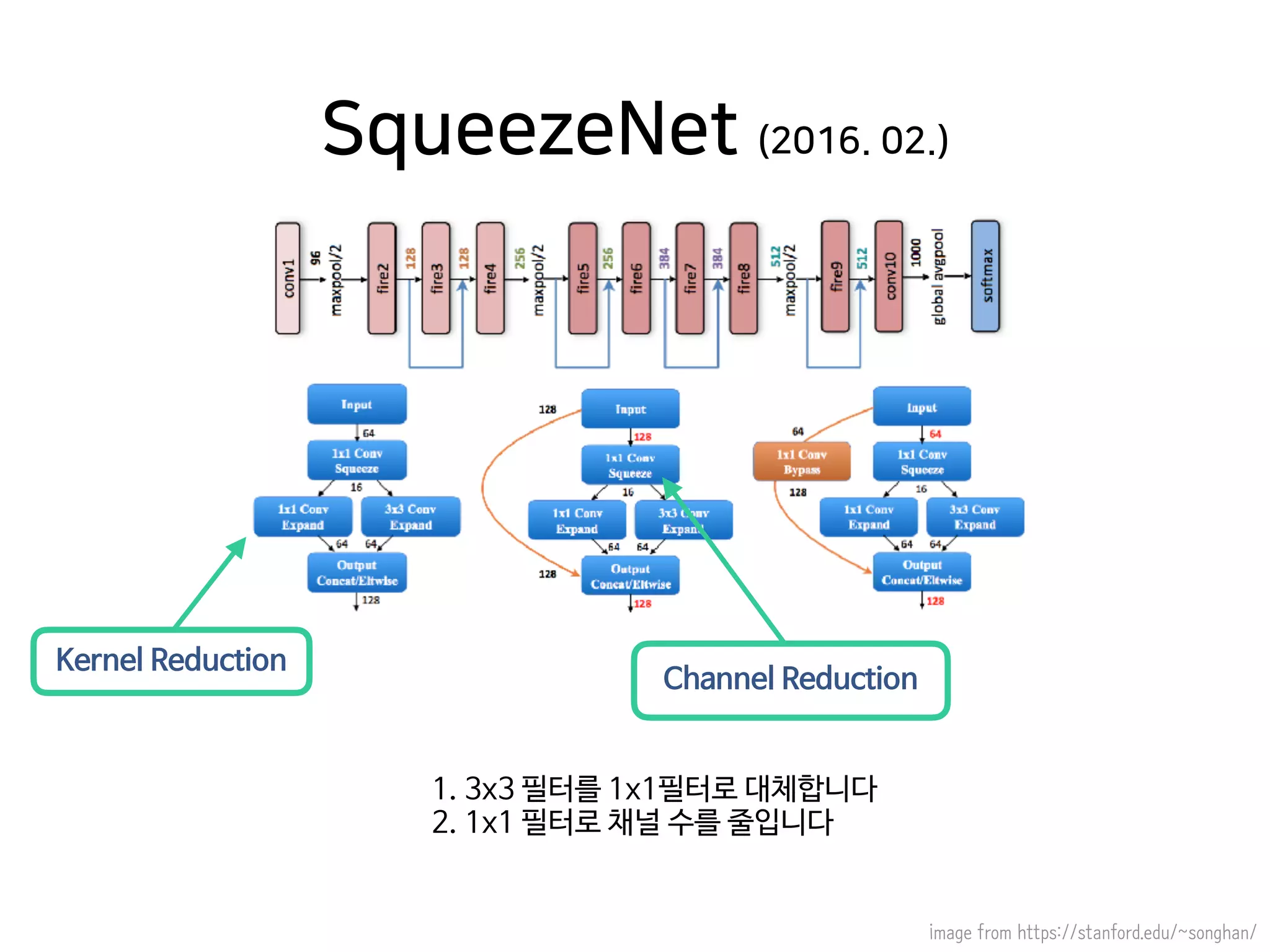
- 39. SqueezeNet (2016. 02.) image from https://stanford.edu/~songhan/ Kernel Reduction Channel Reduction 1. 3x3 필터를 1x1필터로 대체합니다 2. 1x1 필터로 채널 수를 줄입니다
- 40. SqueezeNet (2016. 02.) •첫 레이어에서 7x7이 아닌 3x3을 사용 •Pooling을 1,4,8 에서 {1,3,5}로 early + evenly downsampling SqueezeNet v1.1 을 사용하세요 ResNet도 v2 가 더 좋습니다. 항상 v1.X, V2를 확인하세요. image from https://github.com/DeepScale/SqueezeNet/tree/master/SqueezeNet_v1.1
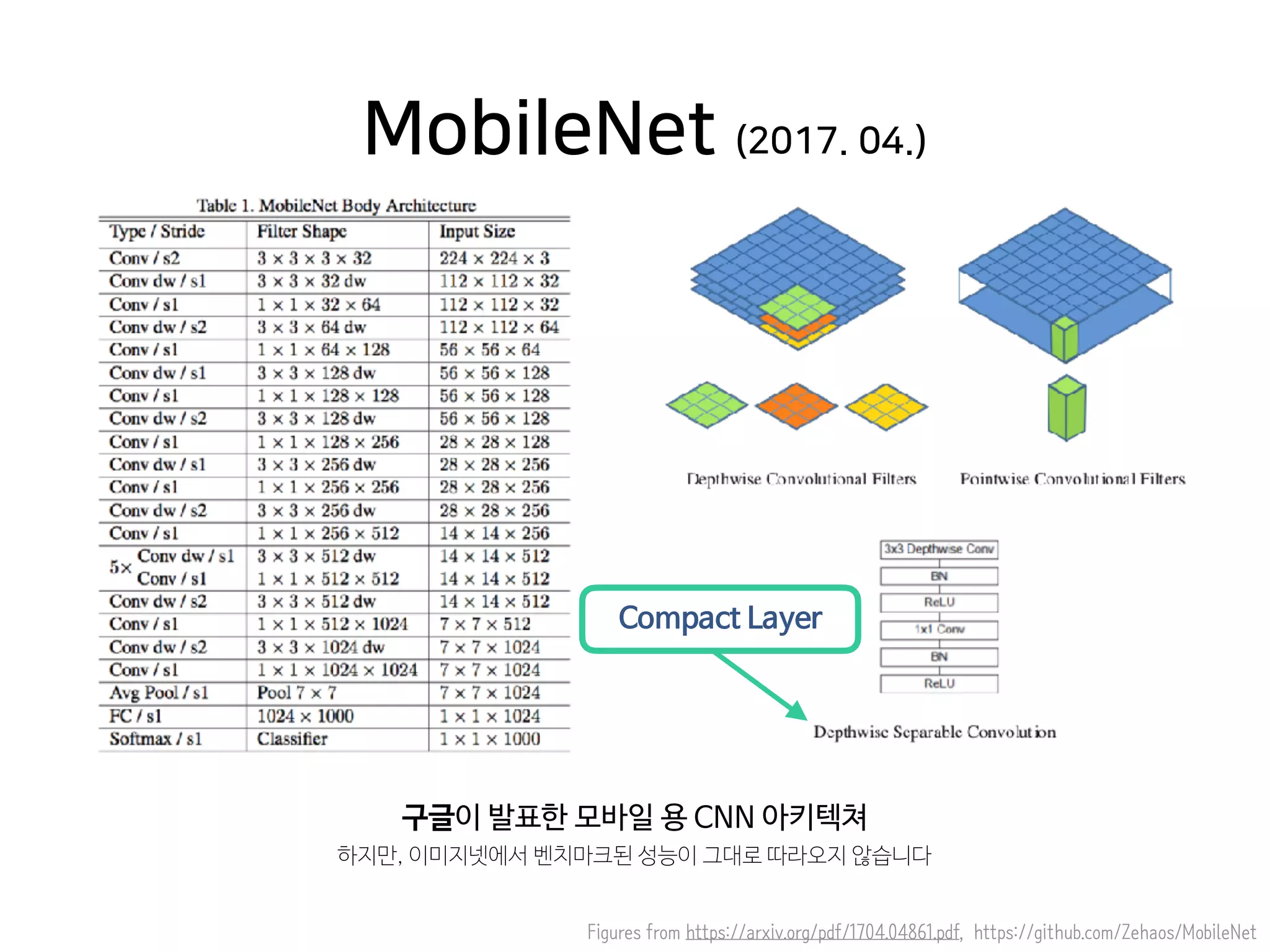
- 41. Figures from https://arxiv.org/pdf/1704.04861.pdf, https://github.com/Zehaos/MobileNet 구글이 발표한 모바일 용 CNN 아키텍쳐 하지만, 이미지넷에서 벤치마크된 성능이 그대로 따라오지 않습니다 MobileNet (2017. 04.) Compact Layer
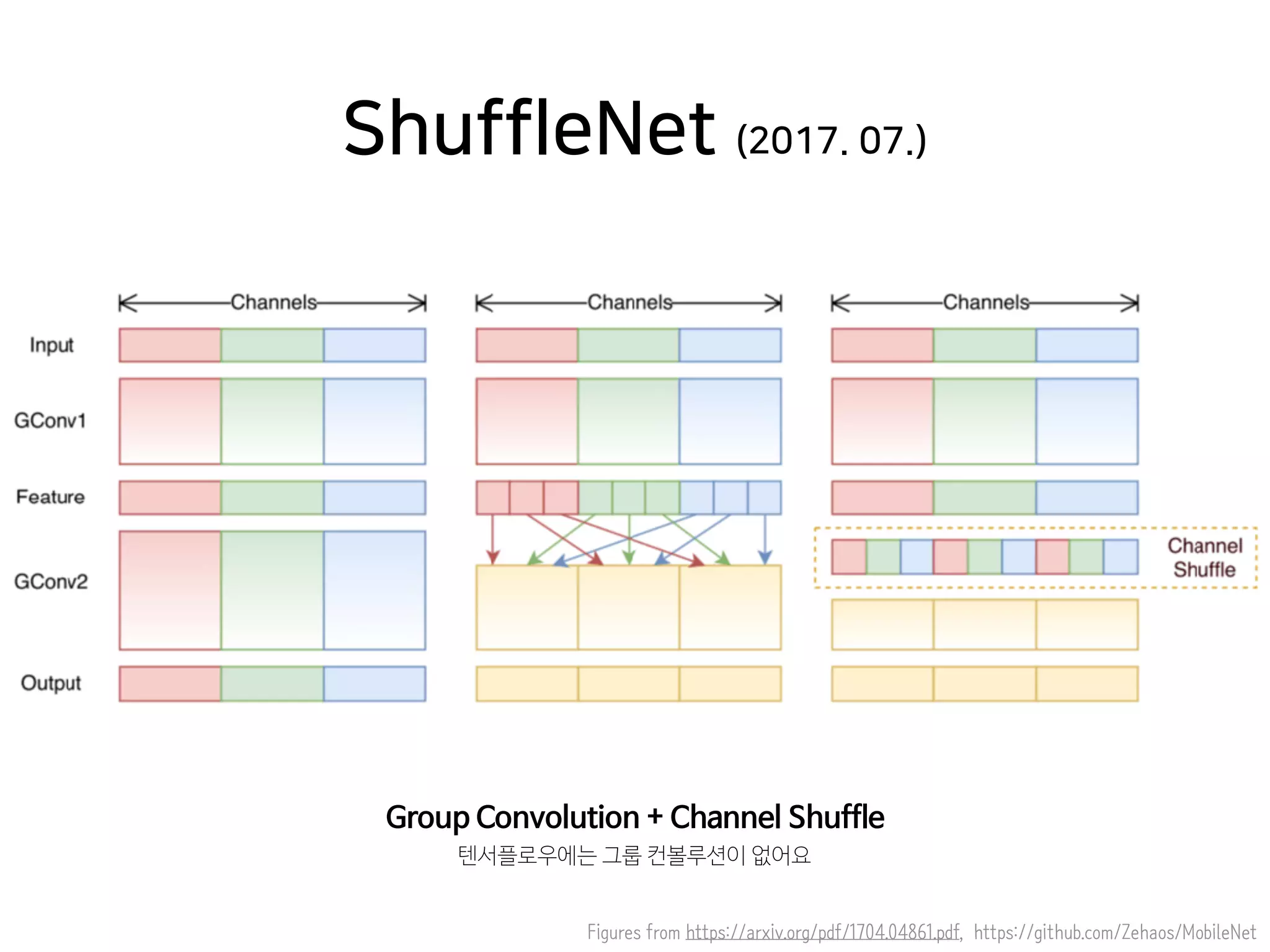
- 42. Figures from https://arxiv.org/pdf/1704.04861.pdf, https://github.com/Zehaos/MobileNet ShuffleNet (2017. 07.) Group Convolution + Channel Shuffle 텐서플로우에는 그룹 컨볼루션이 없어요
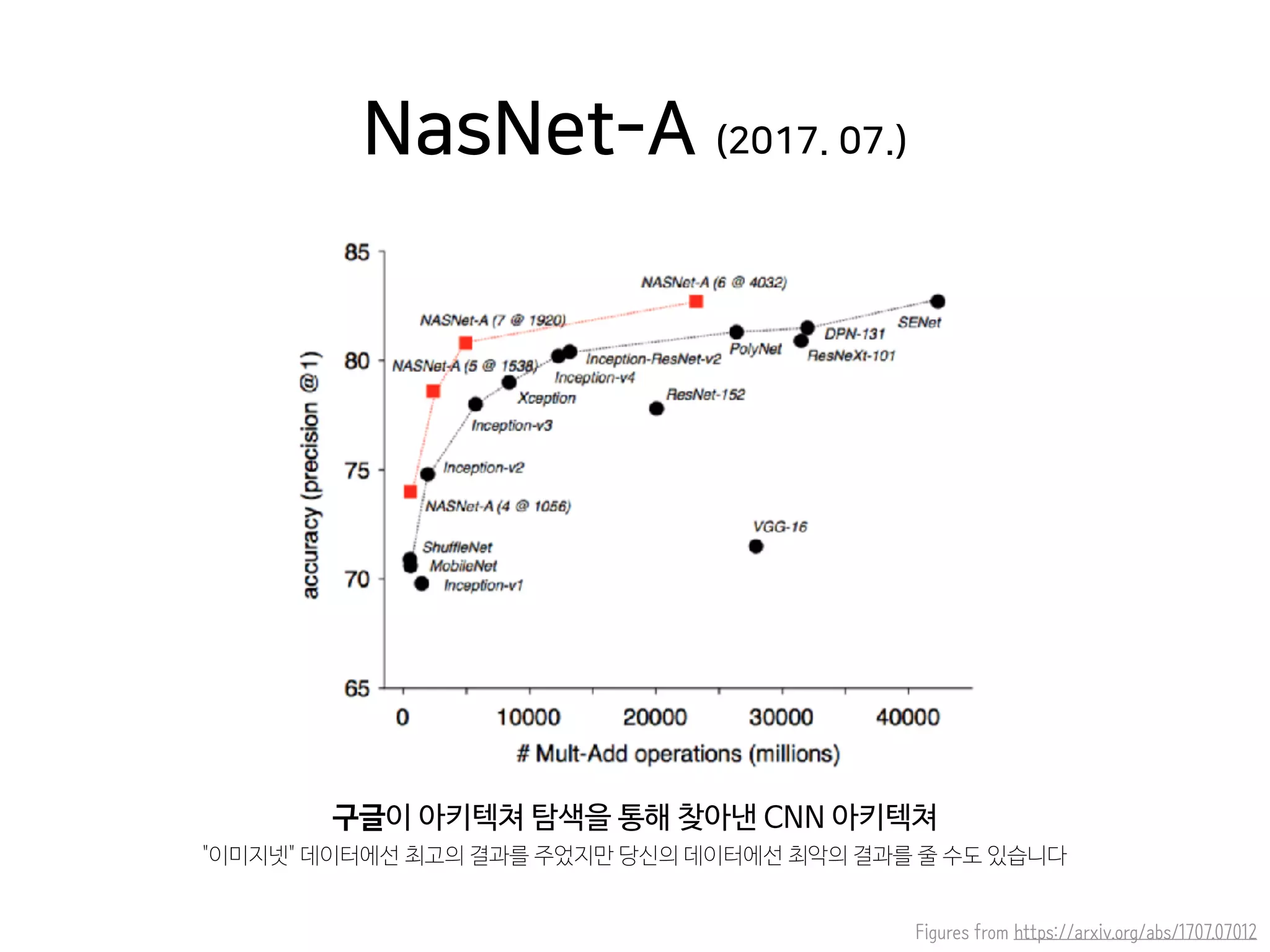
- 43. Figures from https://arxiv.org/abs/1707.07012 구글이 아키텍쳐 탐색을 통해 찾아낸 CNN 아키텍쳐 "이미지넷" 데이터에선 최고의 결과를 주었지만 당신의 데이터에선 최악의 결과를 줄 수도 있습니다 NasNet-A (2017. 07.)
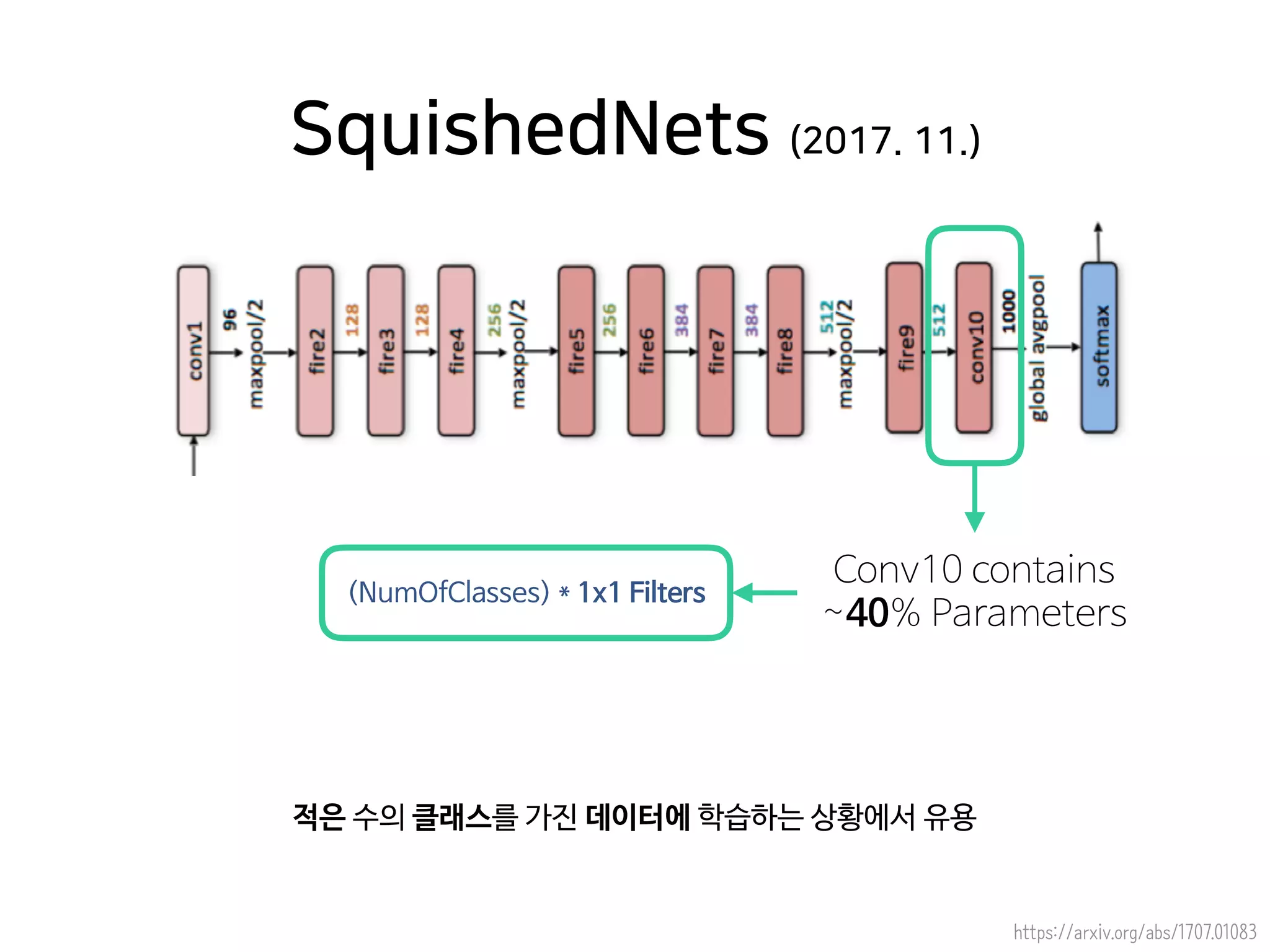
- 44. https://arxiv.org/abs/1707.01083 적은 수의 클래스를 가진 데이터에 학습하는 상황에서 유용 SquishedNets (2017. 11.) Conv10 contains ~40% Parameters (NumOfClasses) * 1x1 Filters
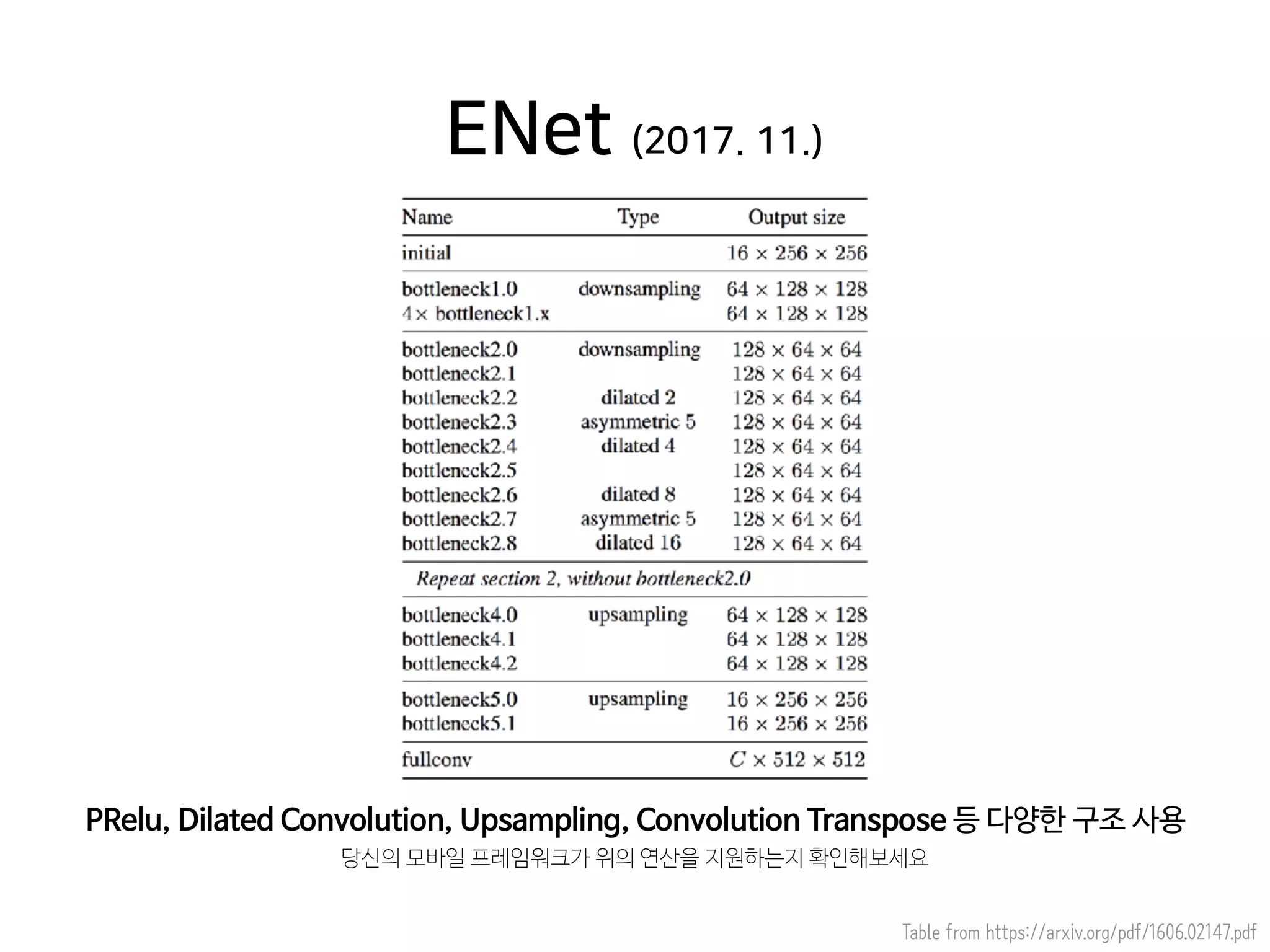
- 45. Table from https://arxiv.org/pdf/1606.02147.pdf PRelu, Dilated Convolution, Upsampling, Convolution Transpose 등 다양한 구조 사용 ENet (2017. 11.) 당신의 모바일 프레임워크가 위의 연산을 지원하는지 확인해보세요
- 46. 효율적인 CNN 구조를 만드는데 도움이 될 6가지 지혜
- 47. 1. Fully-Connected 레이어를 Global Average Pooling으로 대체 •VGG 이후 Network in Network, Inception부터 주로 사용한 방법 •모바일 딥러닝에 국한된 이야기는 아님 •Fully Convolutional 함 Figure from http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture9.pdf
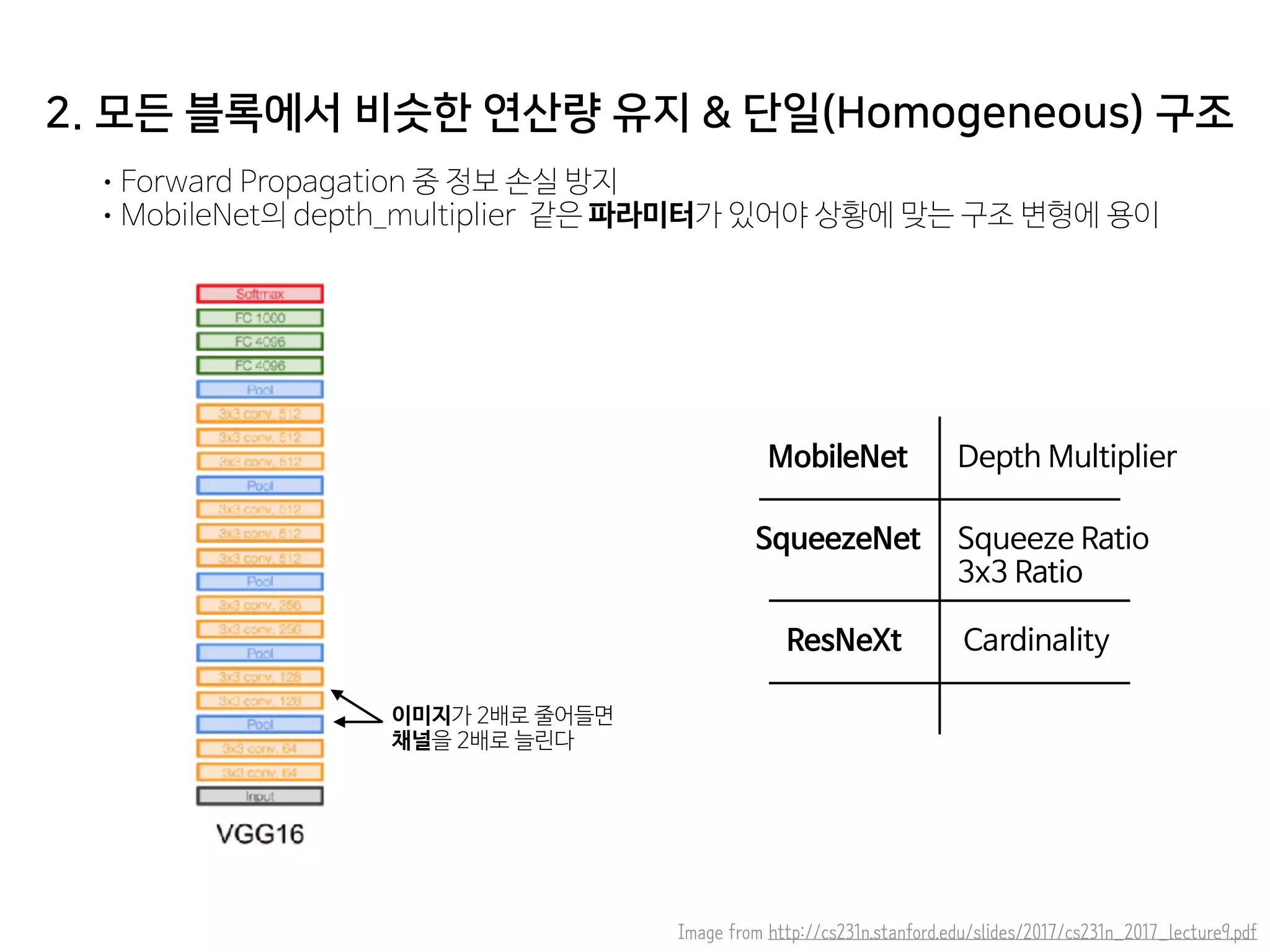
- 48. 2. 모든 블록에서 비슷한 연산량 유지 & 단일(Homogeneous) 구조 •Forward Propagation 중 정보 손실 방지 •MobileNet의 depth_multiplier 같은 파라미터가 있어야 상황에 맞는 구조 변형에 용이 이미지가 2배로 줄어들면 채널을 2배로 늘린다 MobileNet SqueezeNet Depth Multiplier Image from http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture9.pdf Squeeze Ratio 3x3 Ratio ResNeXt Cardinality
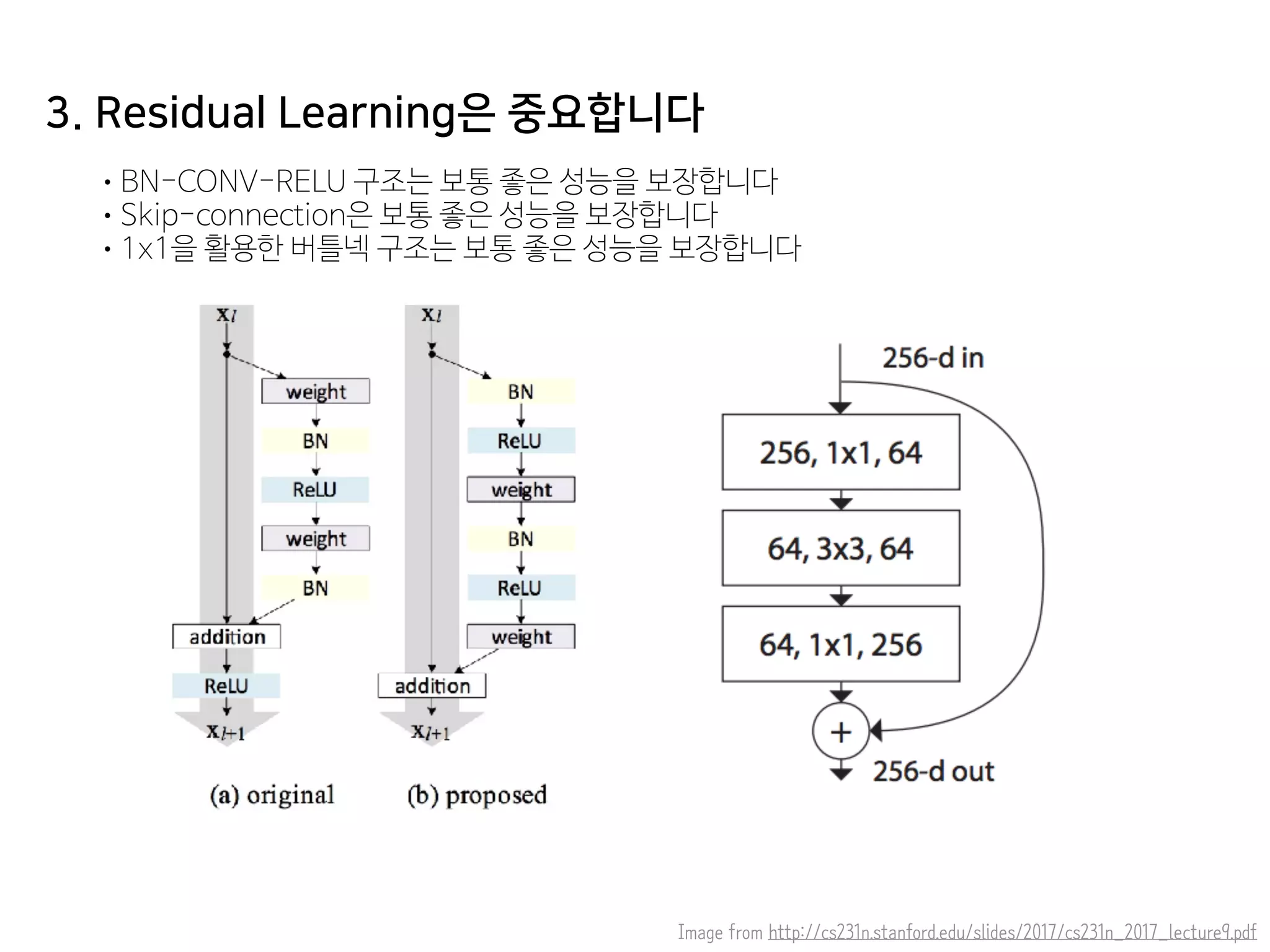
- 49. 3. Residual Learning은 중요합니다 •BN-CONV-RELU 구조는 보통 좋은 성능을 보장합니다 •Skip-connection은 보통 좋은 성능을 보장합니다 •1x1을 활용한 버틀넥 구조는 보통 좋은 성능을 보장합니다 Image from http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture9.pdf
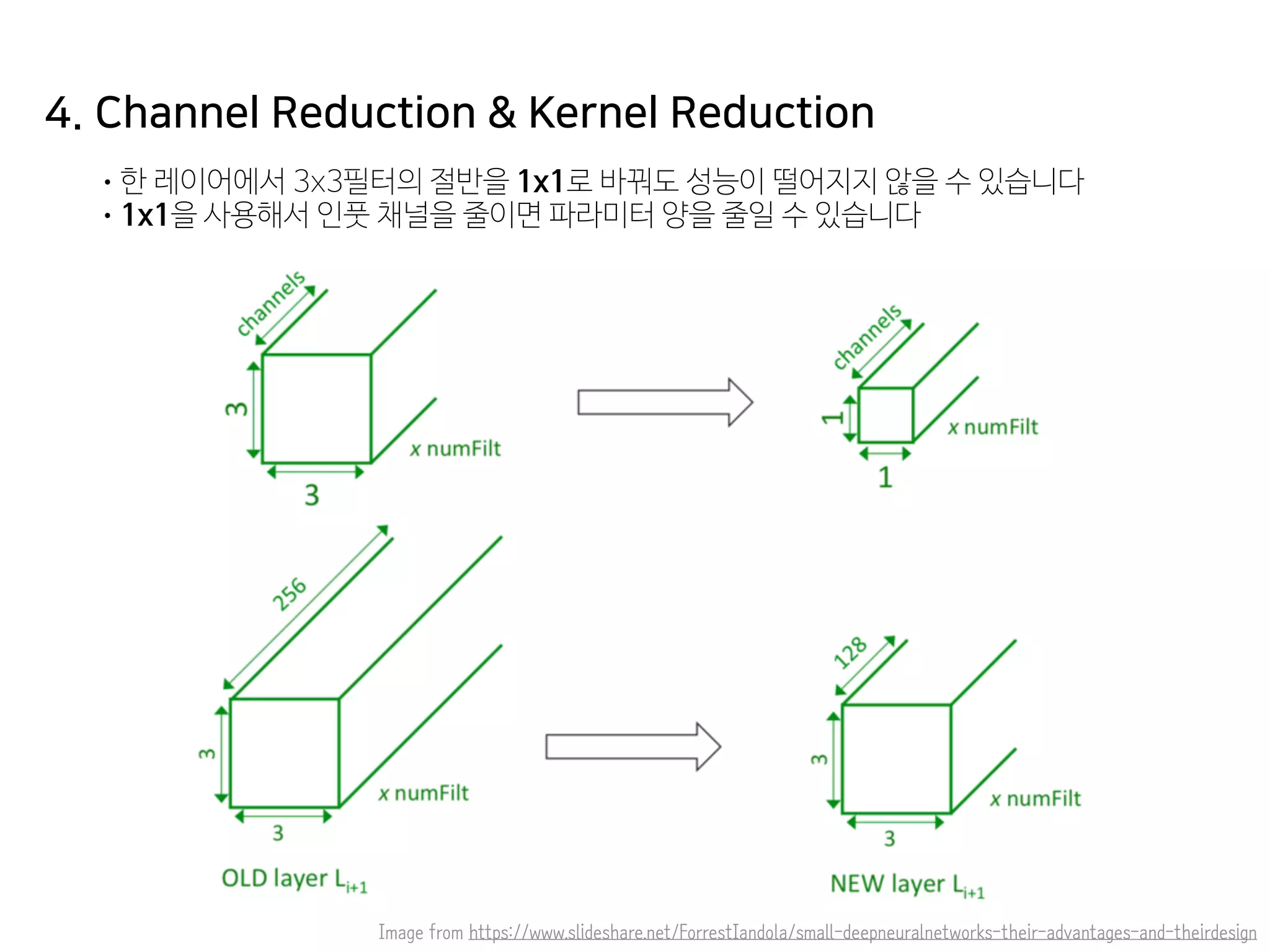
- 50. 4. Channel Reduction & Kernel Reduction •한 레이어에서 3x3필터의 절반을 1x1로 바꿔도 성능이 떨어지지 않을 수 있습니다 •1x1을 사용해서 인풋 채널을 줄이면 파라미터 양을 줄일 수 있습니다 Image from https://www.slideshare.net/ForrestIandola/small-deepneuralnetworks-their-advantages-and-theirdesign
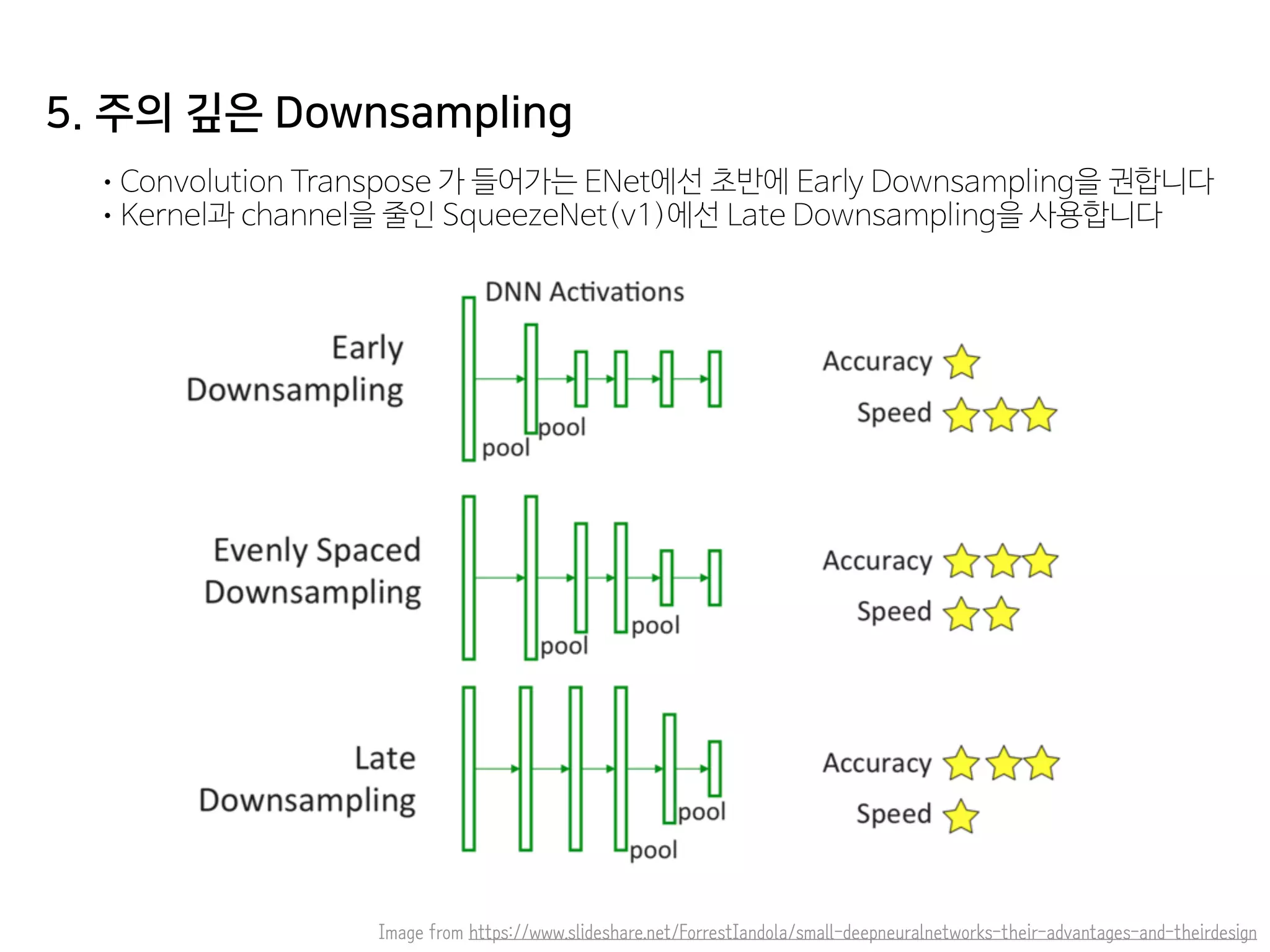
- 51. 5. 주의 깊은 Downsampling •Convolution Transpose 가 들어가는 ENet에선 초반에 Early Downsampling을 권합니다 •Kernel과 channel을 줄인 SqueezeNet(v1)에선 Late Downsampling을 사용합니다 Image from https://www.slideshare.net/ForrestIandola/small-deepneuralnetworks-their-advantages-and-theirdesign
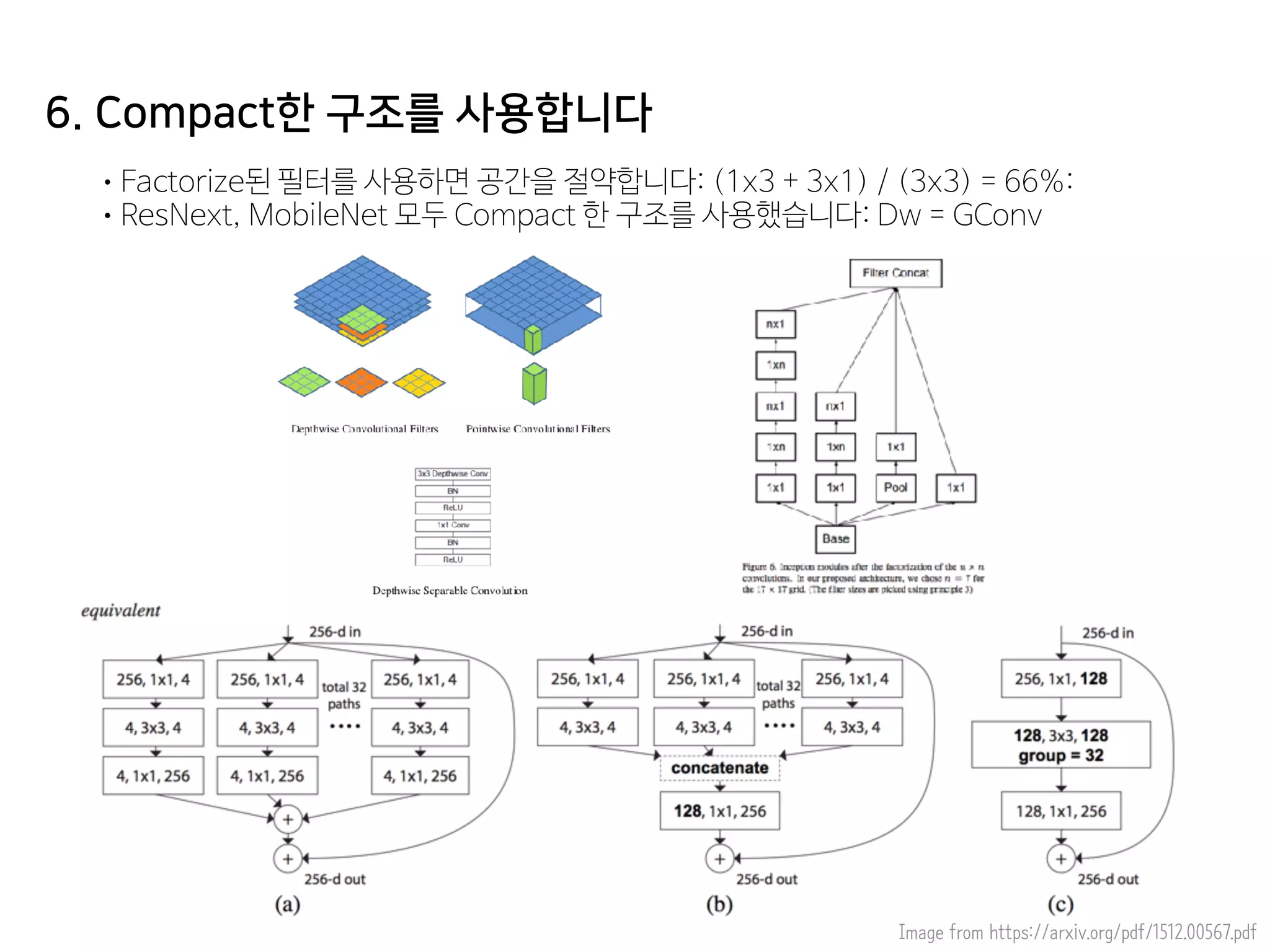
- 52. 6. Compact한 구조를 사용합니다 •Factorize된 필터를 사용하면 공간을 절약합니다: (1x3 + 3x1) / (3x3) = 66%: •ResNext, MobileNet 모두 Compact 한 구조를 사용했습니다: Dw = GConv Image from https://arxiv.org/pdf/1512.00567.pdf
- 53. 이제 좋은 구조를 만들었으니
- 54. "잘" 학습해야합니다
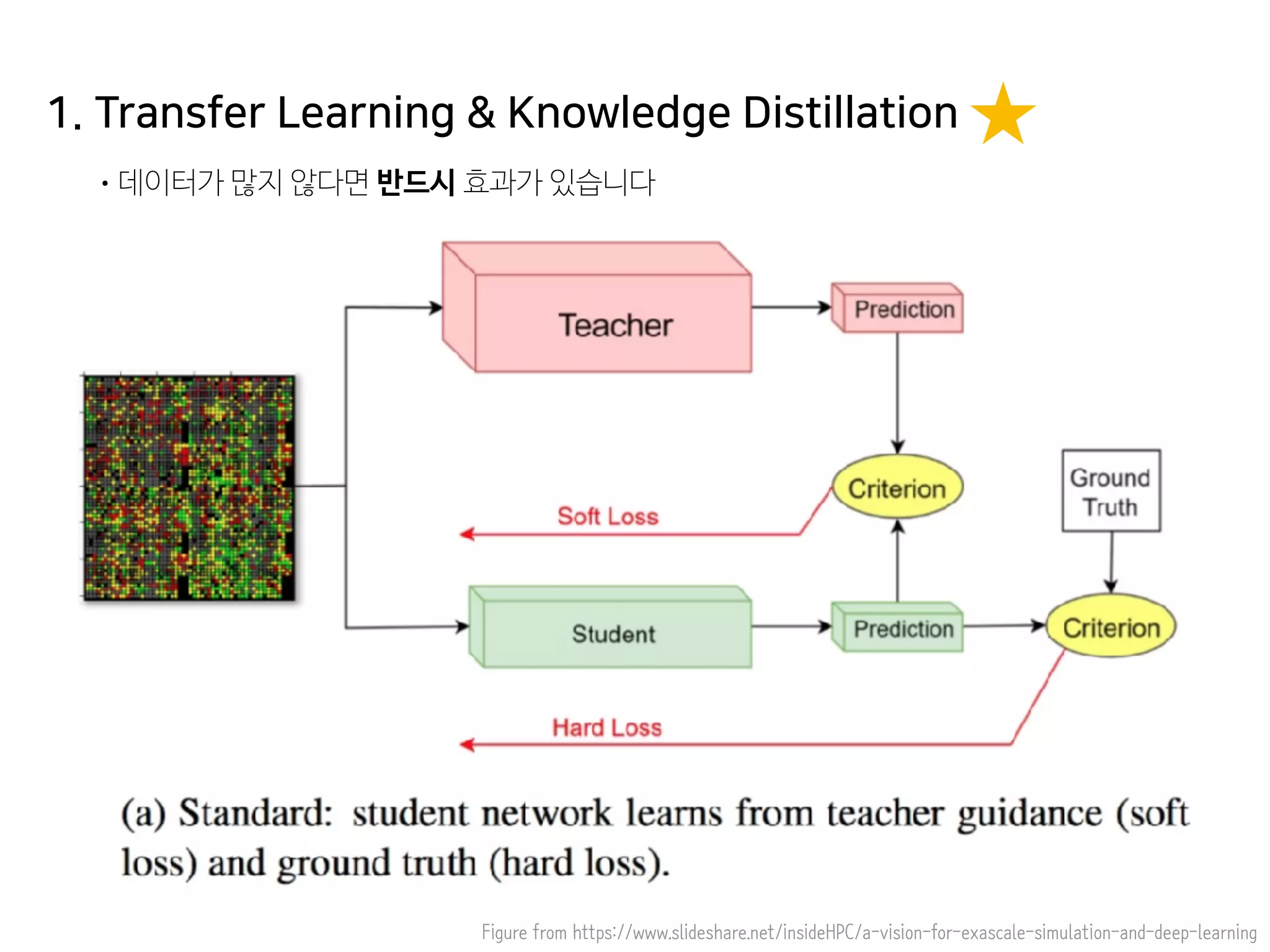
- 55. 1. Transfer Learning & Knowledge Distillation •데이터가 많지 않다면 반드시 효과가 있습니다 Figure from https://www.slideshare.net/insideHPC/a-vision-for-exascale-simulation-and-deep-learning
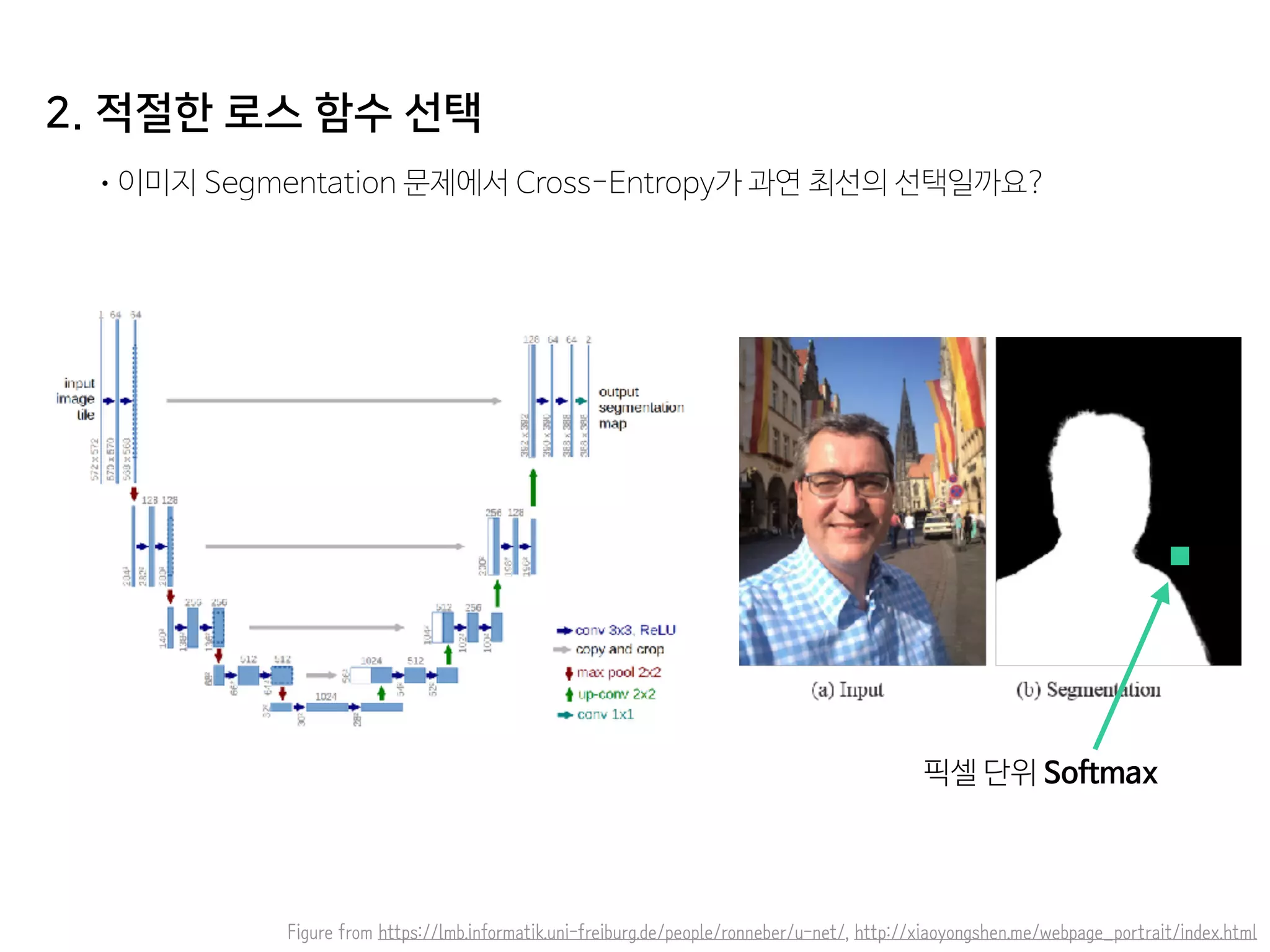
- 56. 2. 적절한 로스 함수 선택 •이미지 Segmentation 문제에서 Cross-Entropy가 과연 최선의 선택일까요? Figure from https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/, http://xiaoyongshen.me/webpage_portrait/index.html 픽셀 단위 Softmax
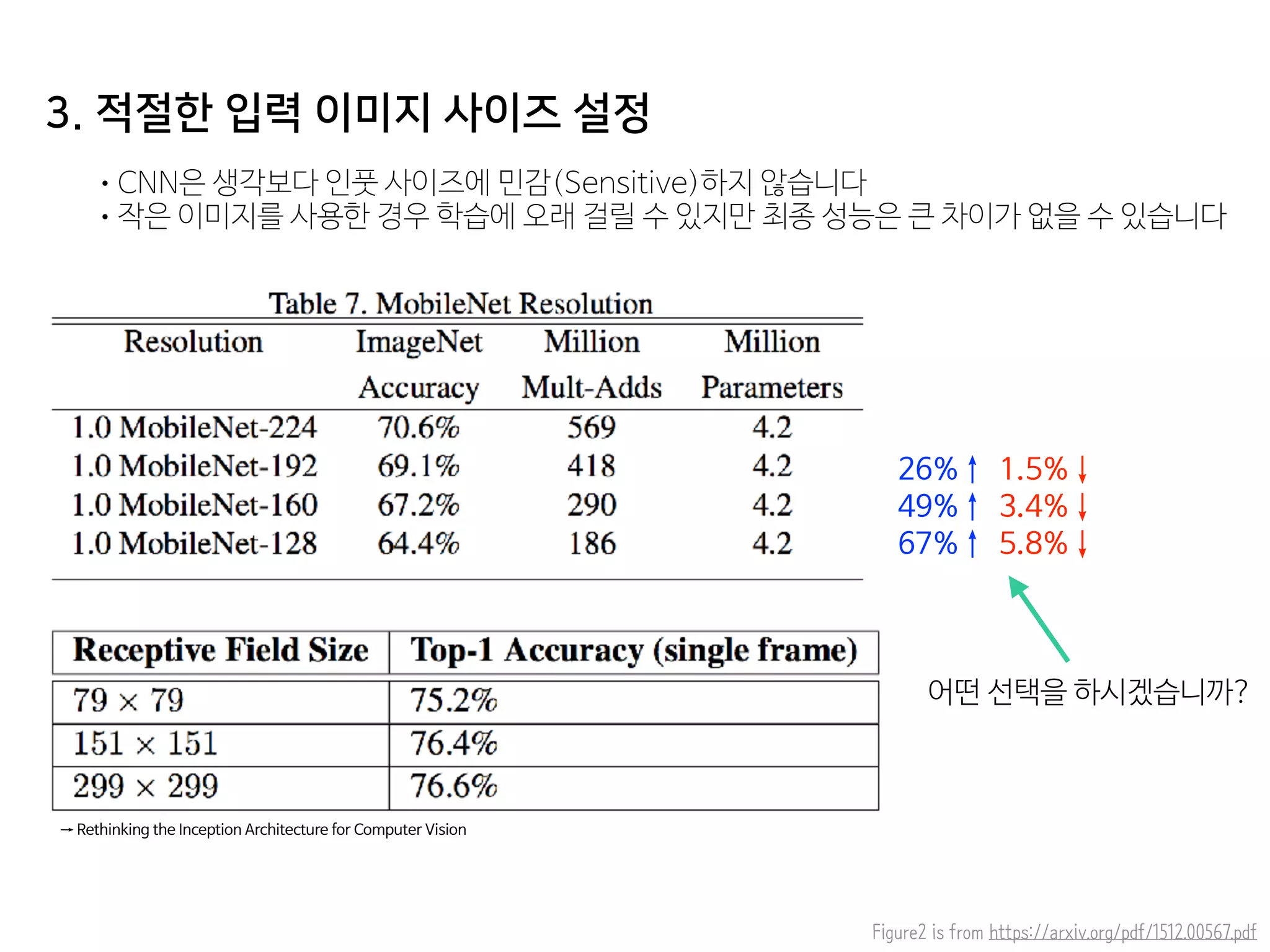
- 57. 3. 적절한 입력 이미지 사이즈 설정 •CNN은 생각보다 인풋 사이즈에 민감(Sensitive)하지 않습니다 •작은 이미지를 사용한 경우 학습에 오래 걸릴 수 있지만 최종 성능은 큰 차이가 없을 수 있습니다 Figure2 is from https://arxiv.org/pdf/1512.00567.pdf 26%↑ 1.5%↓ 49%↑ 3.4%↓ 67%↑ 5.8%↓ → Rethinking the Inception Architecture for Computer Vision 어떤 선택을 하시겠습니까?
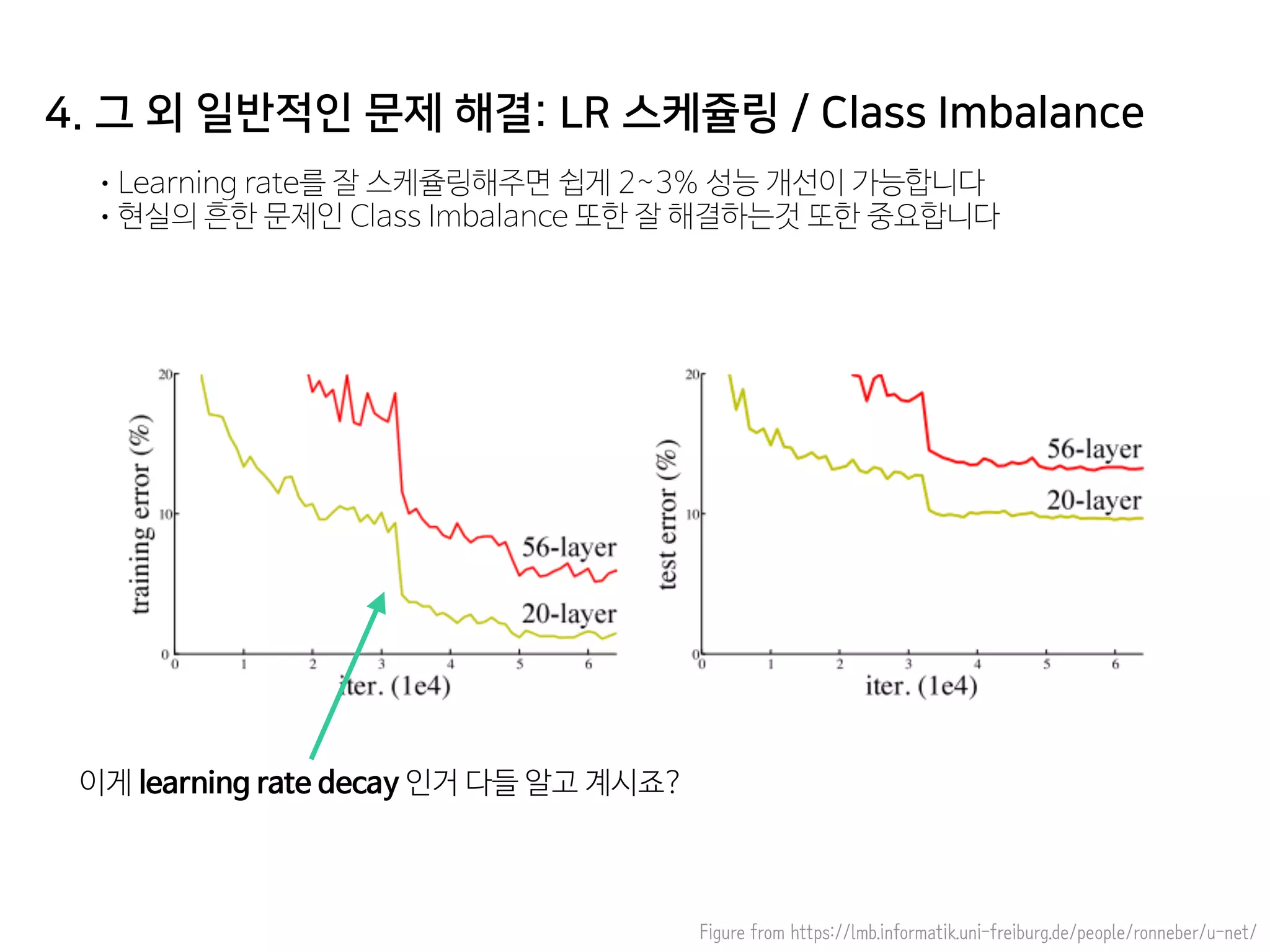
- 58. 4. 그 외 일반적인 문제 해결: LR 스케쥴링 / Class Imbalance •Learning rate를 잘 스케쥴링해주면 쉽게 2~3% 성능 개선이 가능합니다 •현실의 흔한 문제인 Class Imbalance 또한 잘 해결하는것 또한 중요합니다 Figure from https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/ 이게 learning rate decay 인거 다들 알고 계시죠?
- 59. 3가지 교훈 용량을 적게 쓰고 속도가 빠르면서 예측 정확도가 높은 모델 만들기
- 60. 이미지넷 벤치마크 성능은 쉽게 일반화되지 않는다1. - 실제 실험 결과, SqueezeNet > MobileNet > NasNet - 고민없이 선택한 MobileNet이 최선이 아닐 수 있다 모바일 CNN 논문 뿐만 아니라 CNN 전체 논문을 팔로업 해야한다2. - MobileNet, SqueezeNet 보다 ResNet 의 구조가 더 큰 도움이 될 수도 있다 - Inception, ResNet, DenseNet 등 유명 네트워크의 경험과 관찰로부터 배우자 기본에 충실하면 매우 작은 크기의 모델로 놀라운 성능을 만들어낼 수 있다3. - 데이터의 양과 질(Distillation, class Imbalance)에 부족함은 없는가? - 문제에 적합한 로스함수를 사용하고 있는가? - 현재 최적화 방법이 가장 최선인가? - 이미 여러 Teacher-Student 논문에서 놀라운 결과가 발표됨
- 61. 용량을 적게 쓰고 속도가 빠르면서 예측 정확도가 높은 모델 만들기1. 딥러닝 모델을 효율적으로 구현하고 안정적으로 운영하기2.
- 62. 우리가 선택할 수 있는 딥러닝 프레임워크
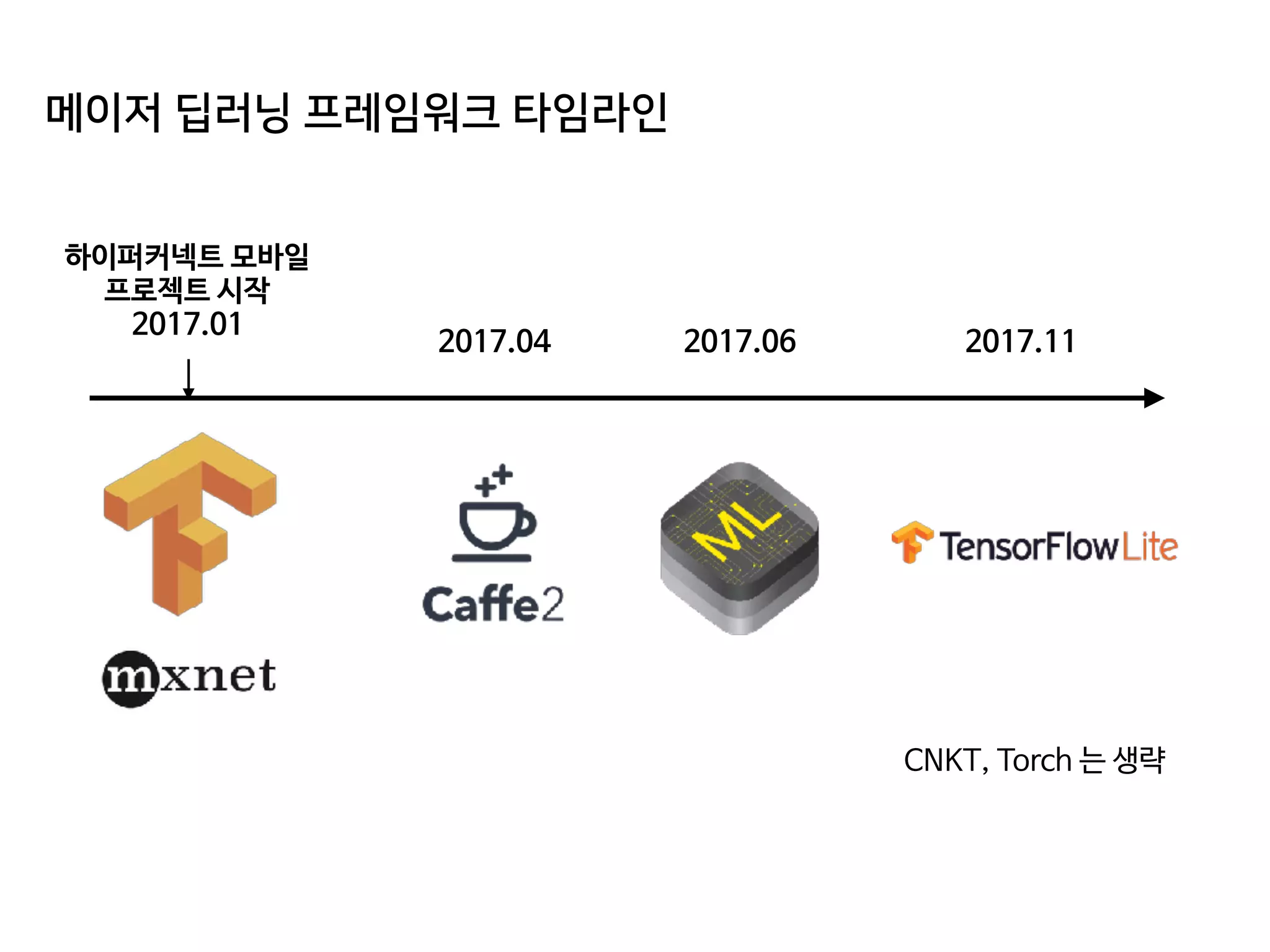
- 63. 메이저 딥러닝 프레임워크 타임라인 하이퍼커넥트 모바일 프로젝트 시작 2017.01 CNKT, Torch 는 생략
- 64. 메이저 딥러닝 프레임워크 타임라인 하이퍼커넥트 모바일 프로젝트 시작 2017.01 2017.04 CNKT, Torch 는 생략
- 65. 메이저 딥러닝 프레임워크 타임라인 하이퍼커넥트 모바일 프로젝트 시작 2017.01 2017.04 2017.06 CNKT, Torch 는 생략
- 66. 메이저 딥러닝 프레임워크 타임라인 하이퍼커넥트 모바일 프로젝트 시작 2017.01 2017.04 2017.06 2017.11 CNKT, Torch 는 생략
- 67. Wait Calculation 기술 발전 속도가 빠르기 때문에 지금 로켓 만들기를 시작하는 것보다 N년 뒤에 만들면 오히려 안드로메다에 더 빨리 도착할 수 있다 N은 얼마인가?
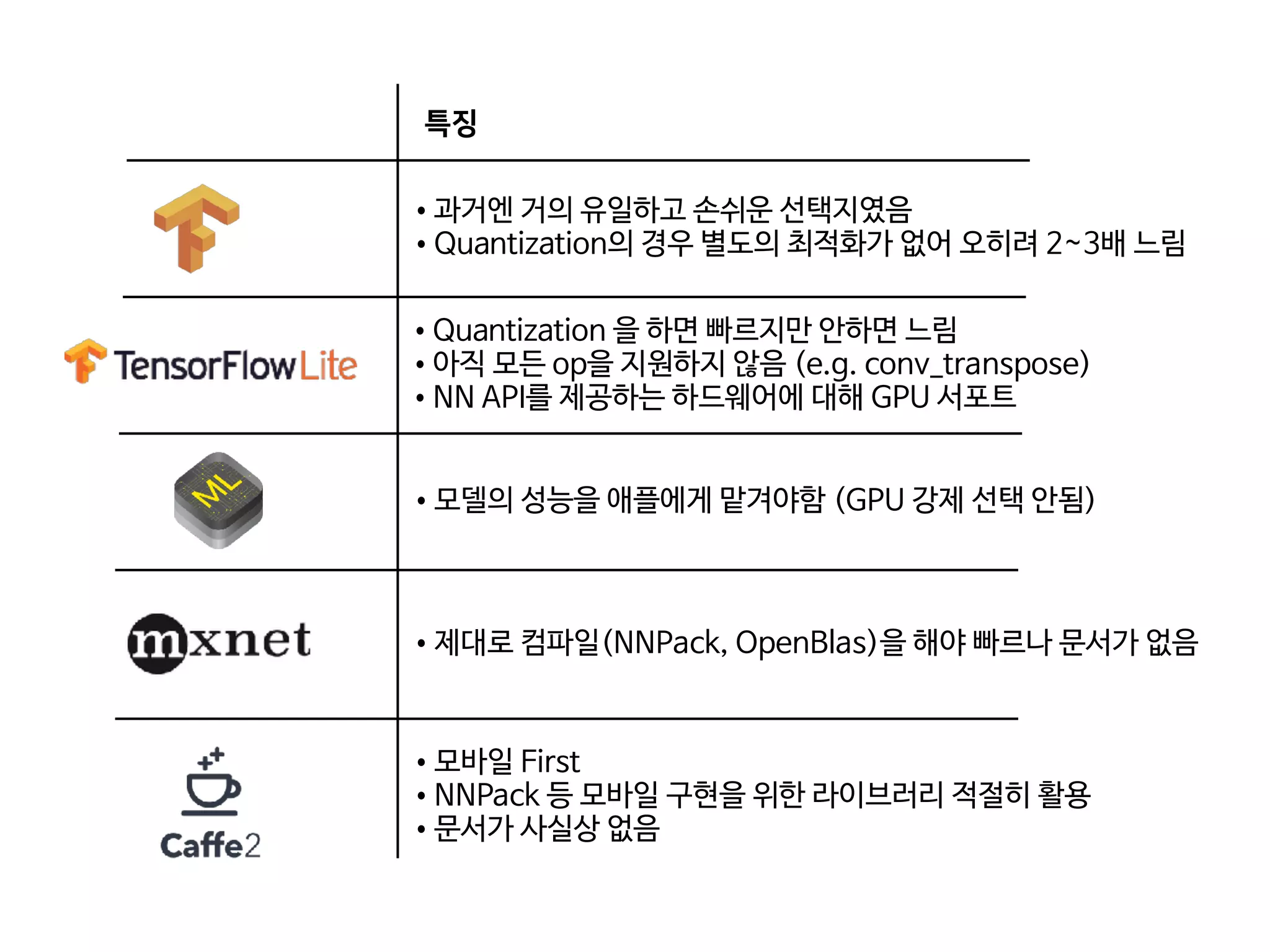
- 68. 특징 •과거엔 거의 유일하고 손쉬운 선택지였음 •Quantization의 경우 별도의 최적화가 없어 오히려 2~3배 느림 •모델의 성능을 애플에게 맡겨야함 (GPU 강제 선택 안됨) •Quantization 을 하면 빠르지만 안하면 느림 •아직 모든 op을 지원하지 않음 (e.g. conv_transpose) •NN API를 제공하는 하드웨어에 대해 GPU 서포트 •모바일 First •NNPack 등 모바일 구현을 위한 라이브러리 적절히 활용 •문서가 사실상 없음 •제대로 컴파일(NNPack, OpenBlas)을 해야 빠르나 문서가 없음
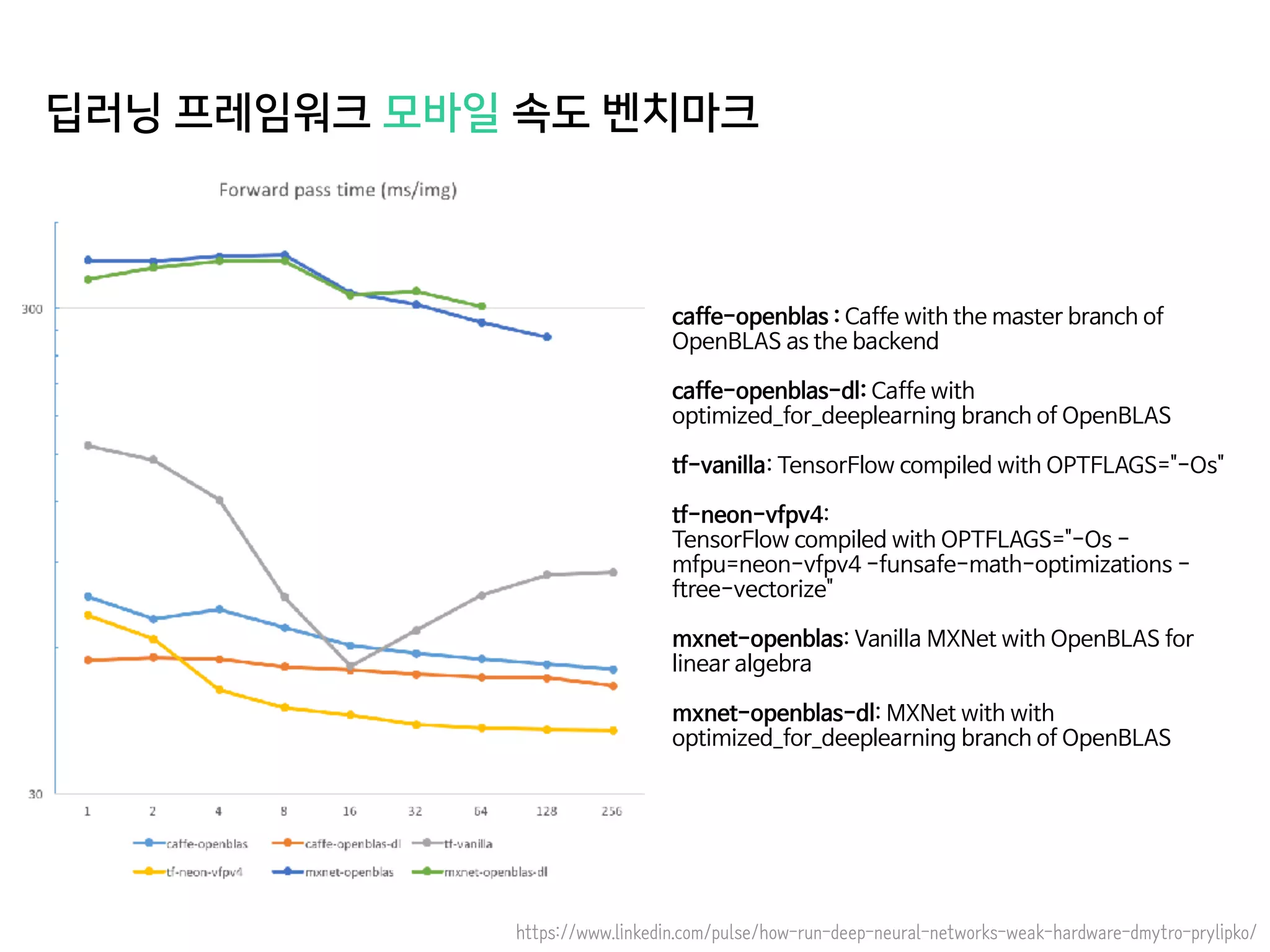
- 69. 딥러닝 프레임워크 모바일 속도 벤치마크 https://www.linkedin.com/pulse/how-run-deep-neural-networks-weak-hardware-dmytro-prylipko/ caffe-openblas : Caffe with the master branch of OpenBLAS as the backend caffe-openblas-dl: Caffe with optimized_for_deeplearning branch of OpenBLAS tf-vanilla: TensorFlow compiled with OPTFLAGS="-Os" tf-neon-vfpv4: TensorFlow compiled with OPTFLAGS="-Os - mfpu=neon-vfpv4 -funsafe-math-optimizations - ftree-vectorize" mxnet-openblas: Vanilla MXNet with OpenBLAS for linear algebra mxnet-openblas-dl: MXNet with with optimized_for_deeplearning branch of OpenBLAS
- 70. 그래서, 프레임워크 어떻게 선택해야할까요? 3가지 기준
- 71. 학습에 사용한 프레임워크에서 얻어진 파라미터를 쉽게 모바일 용으로 컨버팅 가능해야한다 •Batch Normalization 에서 Epsilon이 분모에 더하는 등의 차이 •Convolution의 다양한 옵션 구현(dilate) •NCHW - NHWC •HWOI - IOHW •실제로 돌려봐야 성능과 속도를 알 수 있습니다 1. 모바일 환경(Arm NEON)에 최적화된 구현이 있어야 한다 •Quantization을 한다면 SIMD instruction을 활용해야 의미가 있다 2. 매우 빠르게 변화하는 딥러닝 세계에 같이 대응할 커뮤니티가 존재해야한다 •Batch Normalization, Batch Renormalization, (...) •새로운 네트워크 구조를 만들었으면 모바일로 옮겨서 빠르게 실험해봐야합니다 (End-to-End) 3.
- 72. 프레임워크를 선택했으면
- 73. 모바일 환경에 유용한 압축/구현 방법을 적용해야합니다 3가지를 소개합니다
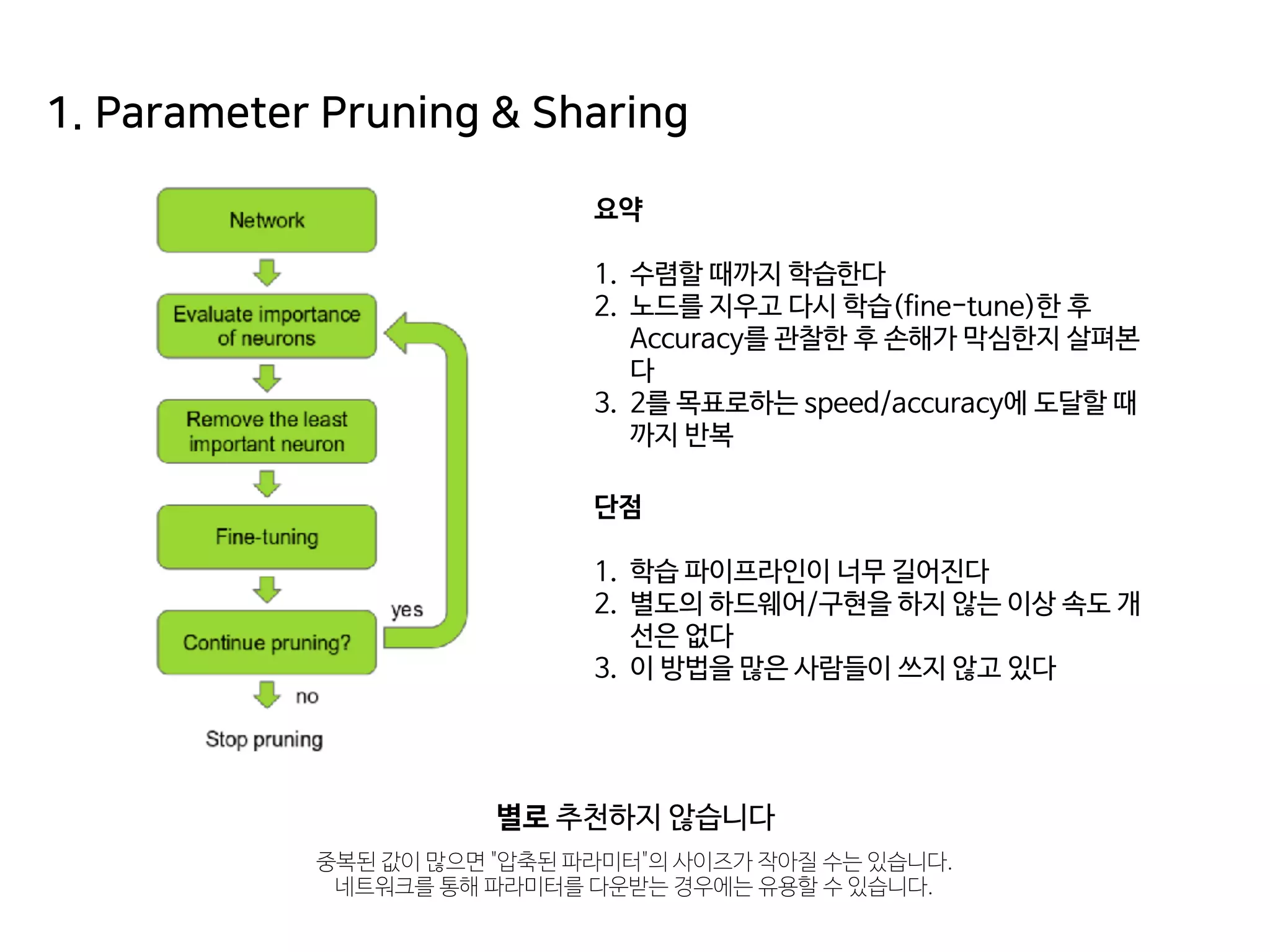
- 74. 1. Parameter Pruning & Sharing 요약 1. 수렴할 때까지 학습한다 2. 노드를 지우고 다시 학습(fine-tune)한 후 Accuracy를 관찰한 후 손해가 막심한지 살펴본 다 3. 2를 목표로하는 speed/accuracy에 도달할 때 까지 반복 별로 추천하지 않습니다 중복된 값이 많으면 "압축된 파라미터"의 사이즈가 작아질 수는 있습니다. 네트워크를 통해 파라미터를 다운받는 경우에는 유용할 수 있습니다. 단점 1. 학습 파이프라인이 너무 길어진다 2. 별도의 하드웨어/구현을 하지 않는 이상 속도 개 선은 없다 3. 이 방법을 많은 사람들이 쓰지 않고 있다
- 75. Figure from https://arxiv.org/pdf/1711.02638.pdf •Tucker Decomposition, CP Decomposition •Pruning과 마찬가지로 학습 파이프라인이 너무 길어진다 •적용 범위가 제한적이다 (특히 convolution 연산) •최근엔 Compression-Aware한 학습 방법이 제안되고 있음 2. Low Rank Approximation / Decomposition Loss function from Compression-aware Training of Deep Networks (NIPS2017) 파라미터가 Low Rank를 가지도록 만드는 레귤라이져
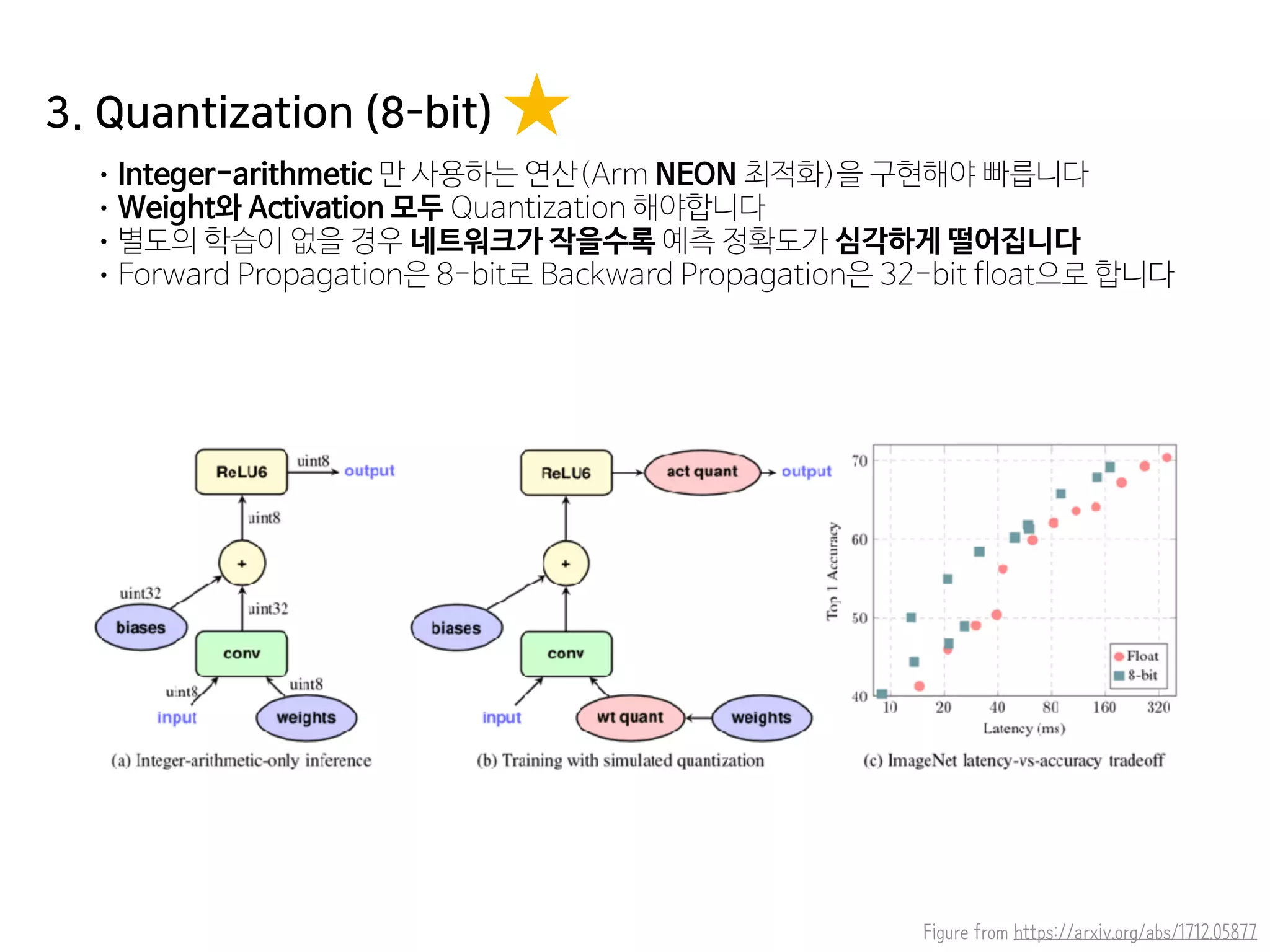
- 76. 3. Quantization (8-bit) •Integer-arithmetic 만 사용하는 연산(Arm NEON 최적화)을 구현해야 빠릅니다 •Weight와 Activation 모두 Quantization 해야합니다 •별도의 학습이 없을 경우 네트워크가 작을수록 예측 정확도가 심각하게 떨어집니다 •Forward Propagation은 8-bit로 Backward Propagation은 32-bit float으로 합니다 Figure from https://arxiv.org/abs/1712.05877
- 77. Figure from https://arxiv.org/abs/1712.05877 •GPU에서 Quantization 관련 보조 노드(Fake Quant) 때문에 3~4배 더 느려집니다 •Tensorflow Mobile에서는 같은 이유로 2배 가량 더 느려집니다 •하지만, TensorFlowLite 로는 2배 이상 빠릅니다 3. Quantization (8-bit)
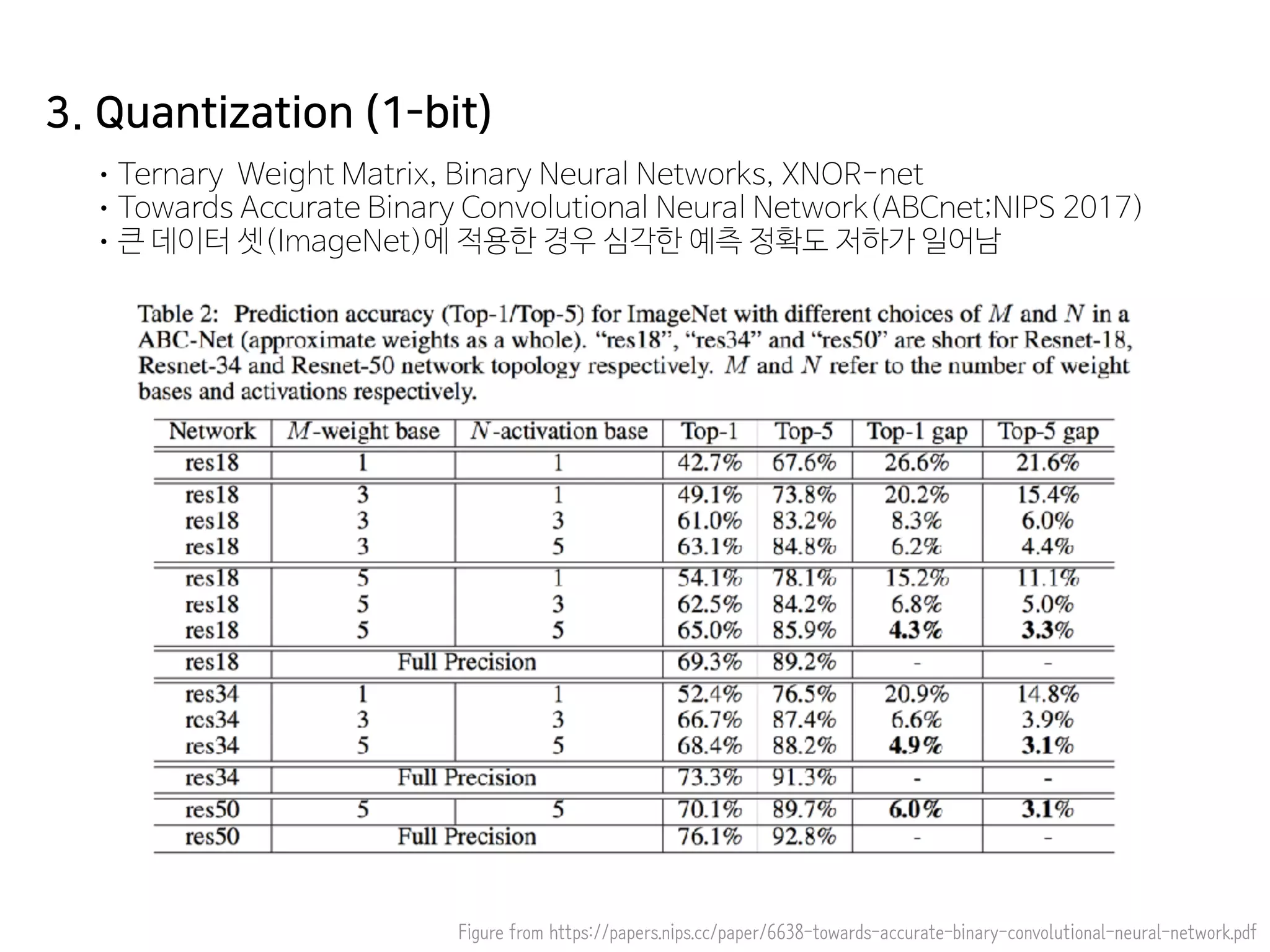
- 78. Figure from https://papers.nips.cc/paper/6638-towards-accurate-binary-convolutional-neural-network.pdf •Ternary Weight Matrix, Binary Neural Networks, XNOR-net •Towards Accurate Binary Convolutional Neural Network(ABCnet;NIPS 2017) •큰 데이터 셋(ImageNet)에 적용한 경우 심각한 예측 정확도 저하가 일어남 3. Quantization (1-bit)
- 79. 그래서, 어떤 기법을 사용해야할까요?
- 80. AlexNet, VGG 등 over-parameterized된 모델만 사용한 실험은 신뢰하면 안된다1. - 실제 모바일에서 벤치마킹한 속도가 있어야한다 모델과 구현이 최대한 독립적이여야 한다2. - 네트워크 구조를 바꾸는 것보단 8-bit를 사용하는게 훨씬 독립적이다 - 학습 파이프라인이 3단계 이상 늘어나면 현실적으로 힘들다 특별한 하드웨어를 요구하는 구현은 무의미하다3. - Deep Compression 은 EIE(Efficient Inference Engine)란 하드웨어에서만 빠르다
- 81. 모바일에 딥러닝 올리기, 참 쉽죠?
- 82. 구현 디테일
- 83. 암호화 압축률 VS
- 84. 암호화 압축률 VS Dynamic frequency scaling
- 85. 암호화 압축률 VS Dynamic frequency scaling Big-Little
- 86. 암호화 압축률 VS Dynamic frequency scaling 빠른 I/O 는 중요합니다(OpenGL) Big-Little
- 87. 암호화 압축률 VS Dynamic frequency scaling 빠른 I/O 는 중요합니다(OpenGL) 적절한 후처리 Big-Little
- 88. 암호화 압축률 VS Dynamic frequency scaling 빠른 I/O 는 중요합니다(OpenGL) ABGR, Orientation 에 유의적절한 후처리 Big-Little
- 89. 다가올 미래
- 90. 5G World
- 91. 5G World Hardware Support
- 92. 5G World Hardware Support XLA
- 93. 감사합니다
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
반응형
'IT 둘러보기' 카테고리의 다른 글
| 소프트웨어 엔지니어의 한국/미국 직장생활 (2) | 2023.03.14 |
|---|---|
| 스타트업은 데이터를 어떻게 바라봐야 할까? (개정판) (0) | 2023.03.14 |
| 코로나19로 인해 변화된 우리 시대의 데이터 트랜드 (1) | 2023.03.14 |
| 메타버스 서비스에 Android 개발자가 할 일이 있나요? (1) | 2023.03.13 |
| 상상을 현실로 만드는, 이미지 생성 모델을 위한 엔지니어링 (1) | 2023.03.13 |
| 책 읽어주는 딥러닝: 배우 유인나가 해리포터를 읽어준다면 (1) | 2023.03.13 |
| Material design 3분 만에 살펴보기 (0) | 2023.03.10 |
| 넷플릭스의 문화 : 자유와 책임 (한국어 번역본) (1) | 2023.03.10 |