반응형
책 읽어주는 딥러닝: 배우 유인나가 해리포터를 읽어준다면 DEVIEW 2017
- 1. 책 읽어주는 딥러닝: 배우 유인나가 해리포터를 읽어준다면 김태훈 / carpedm20
- 2. 김태훈 / carpedm20 /
- 3. 오늘의 주제
- 4. 음성 합성
- 5. 음성텍스트 음성 합성
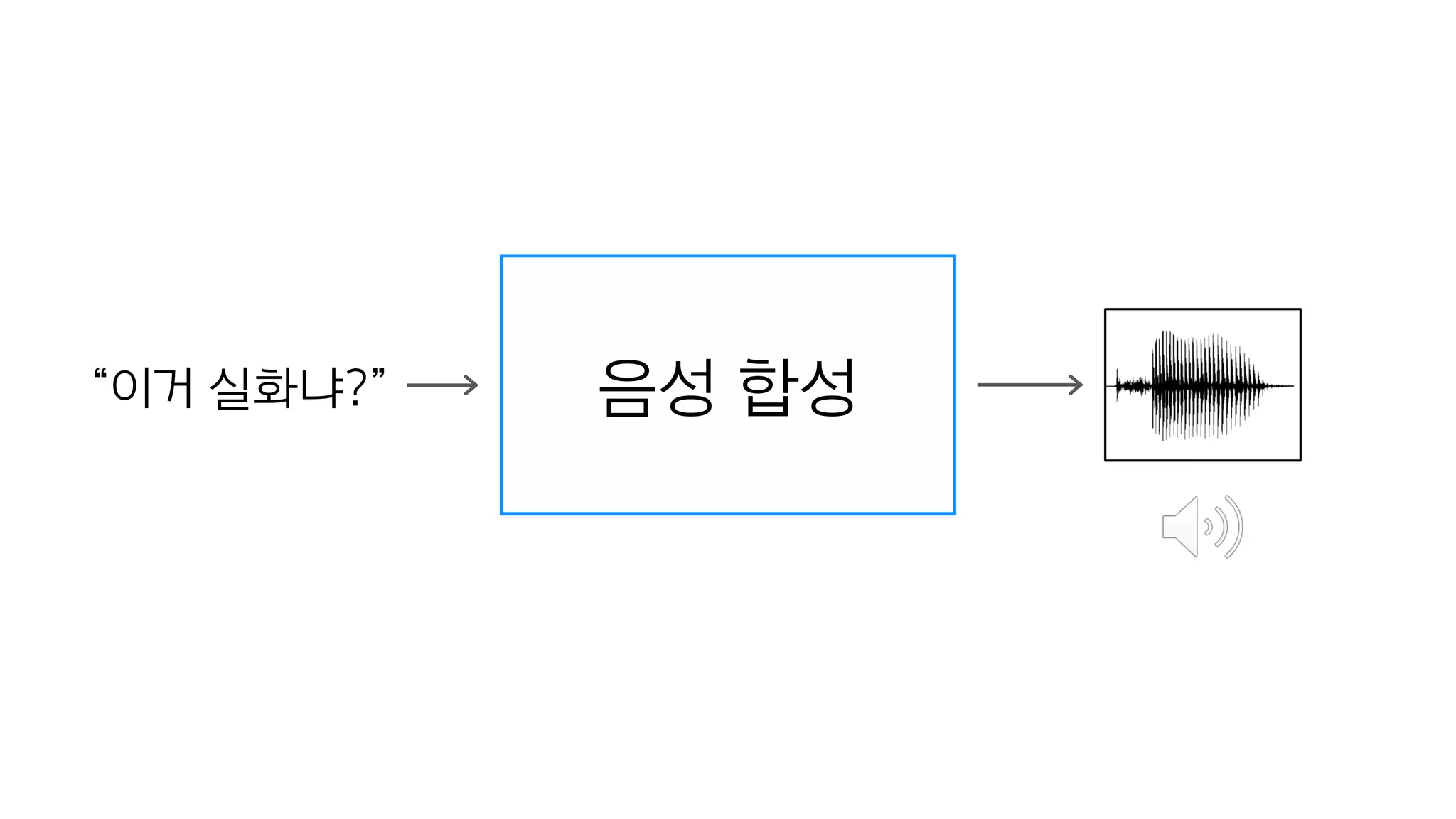
- 6. “이거 실화냐?” 음성 합성
- 7. 무엇을 할 수 있나요?
- 8. 1. 음성 안내 시스템 지하철, 박물관 2. 대화 인공지능 Siri, 스피커 3. 오디오북 성우가 필요한 대부분의 일
- 9. 많은 기업들이 기술을 보유
- 10. nVoice
- 11. 유인나 데모를 듣고나서..
- 12. “배우 유인나가 해리포터를 읽어준다면?”
- 13. 나도 할 수 있을까?
- 14. API
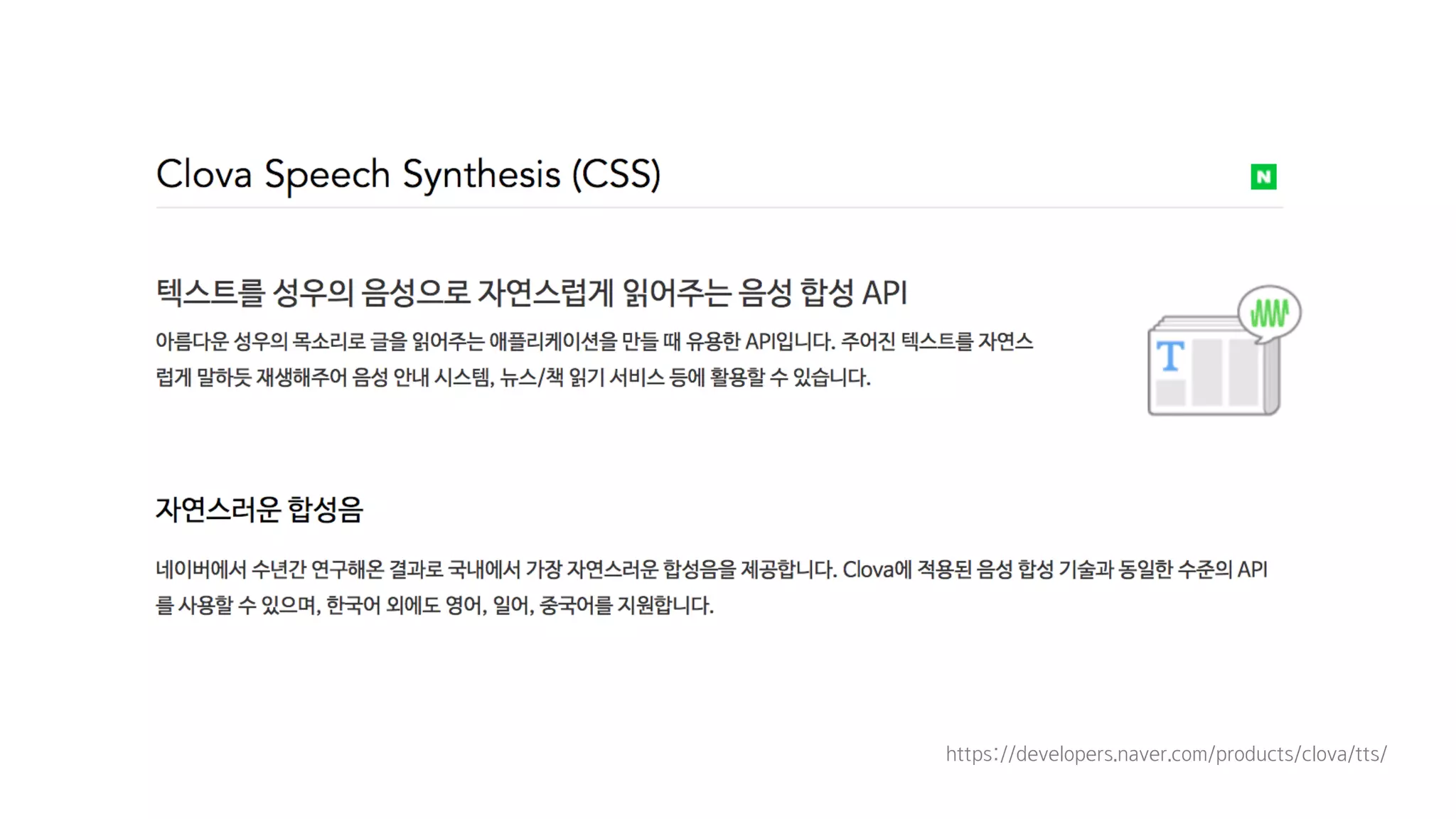
- 15. 유인나는 없음 ㅠㅠ
- 16. https://developers.naver.com/products/clova/tts/
- 17. https://developers.naver.com/products/clova/tts/
- 18. https://developers.naver.com/products/clova/tts/
- 19. 음..
- 20. 아쉽다
- 21. “자연스러운 목소리를 마음껏”
- 22. 그래서 로 직접 만들어 봤습니다
- 23. 한번 들어볼까요?
- 24. “존경하는 개발자 여러분.”
- 25. “저는 데브시스터즈에서 머신러닝 엔지니어로 일하고 있는 김태훈입니다.”
- 26. “이렇게 제 발표를 들으러 와 주셔서 정말 감사합니다.”
- 27. “아직은 턱없이 부족한 음성합성 모델이지만”
- 28. “오늘 데이터와 코드를 오픈소스로 공개해서”
- 29. “여러분들과 함께 더 좋은 모델로 만들어 나갔으면 좋겠습니다”
- 30. “코드는 발표가 끝나고 공개할 예정이며,”
- 31. “이제 다시 발표자가 진행하도록 하겠습니다.”
- 32. 어떠신가요?
- 33. 오늘의 발표
- 34. 1. 데이터 2. 모델 3. 결과
- 35. 1. 데이터 2. 모델 3. 결과
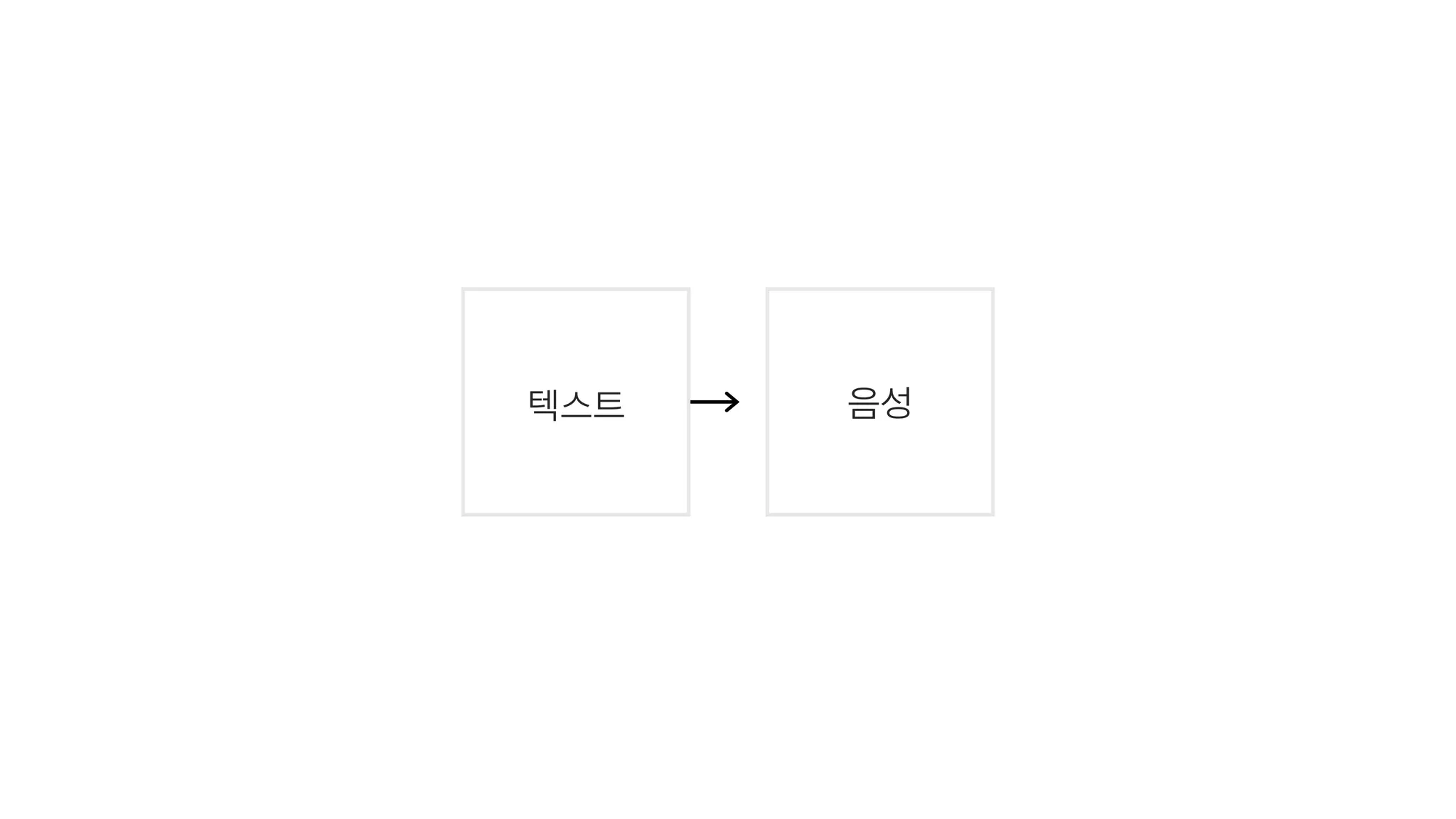
- 36. 텍스트 ↔ 음성
- 37. 직접 만들어야.. 공개 데이터가 없다
- 38. http://news.jtbc.joins.com/html/033/NB11521033.html
- 39. 데이터 프로세싱
- 40. 1. 음성 추출 + 2. 문장 별 자르기 + 3. 텍스트 ↔ 음성 맞추기
- 41. 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다 노가다
- 42. 직접 하진 않았고 자동화 Google Speech API, Text similarity
- 43. 뉴스 + + 오디오북
- 44. 완벽하진 않지만 50+시간 데이터 총 5명의 목소리체감상 90% 정확도
- 45. 손석희 : 15+시간13,000 문장 박근혜 : 5+ 시간6,000문장 문재인 : 2+ 시간2,000 문장
- 46. 손석희 : 15+시간13,000 문장 박근혜 : 5+ 시간6,000문장 문재인 : 2+ 시간2,000 문장
- 47. 손석희 : 15+시간13,000 문장 박근혜 : 5+ 시간6,000문장 문재인 : 2+ 시간2,000 문장
- 48. 손석희 : 15+시간13,000 문장 박근혜 : 5+ 시간6,000문장 문재인 : 2+ 시간2,000 문장
- 49. 1. 데이터 2. 모델 3. 결과
- 50. 딥러닝
- 51. 총 2가지 모델
- 52. 1. Tacotron 2. Deep Voice 2
- 53. 1. Tacotron
- 54. 7달 전
- 55. 핵심은
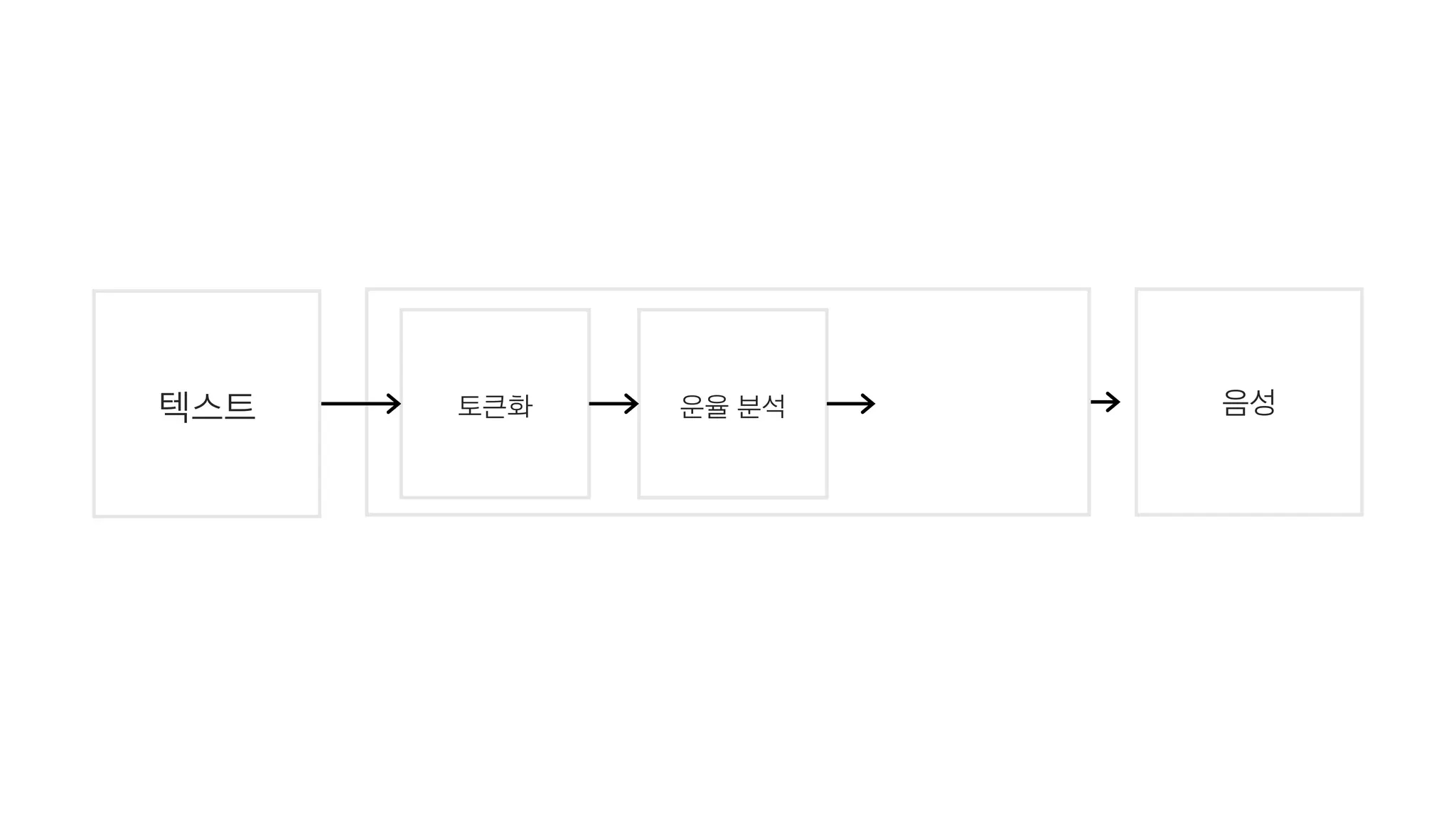
- 56. 텍스트 음성
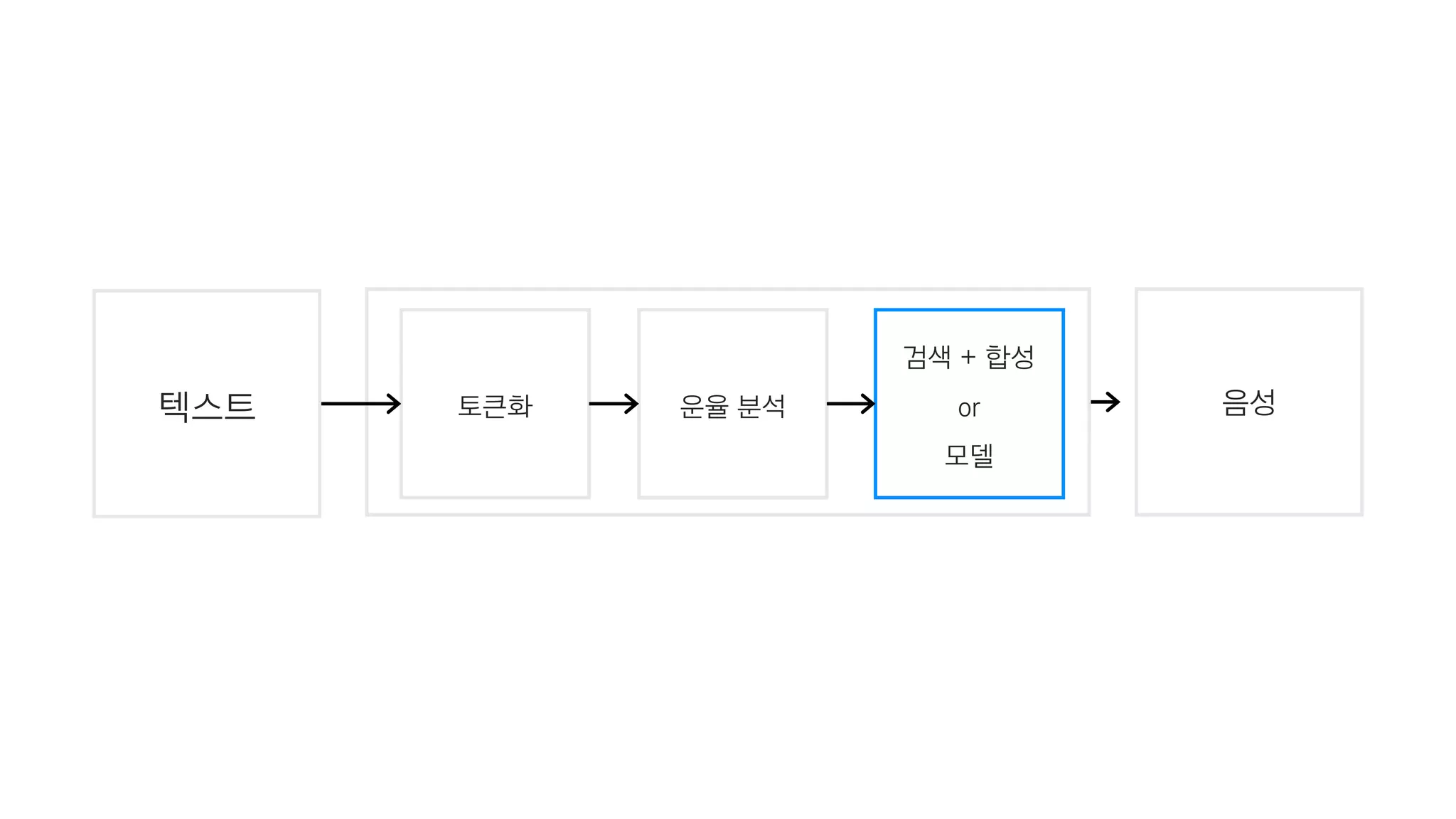
- 57. 음성토큰화 운율 분석텍스트
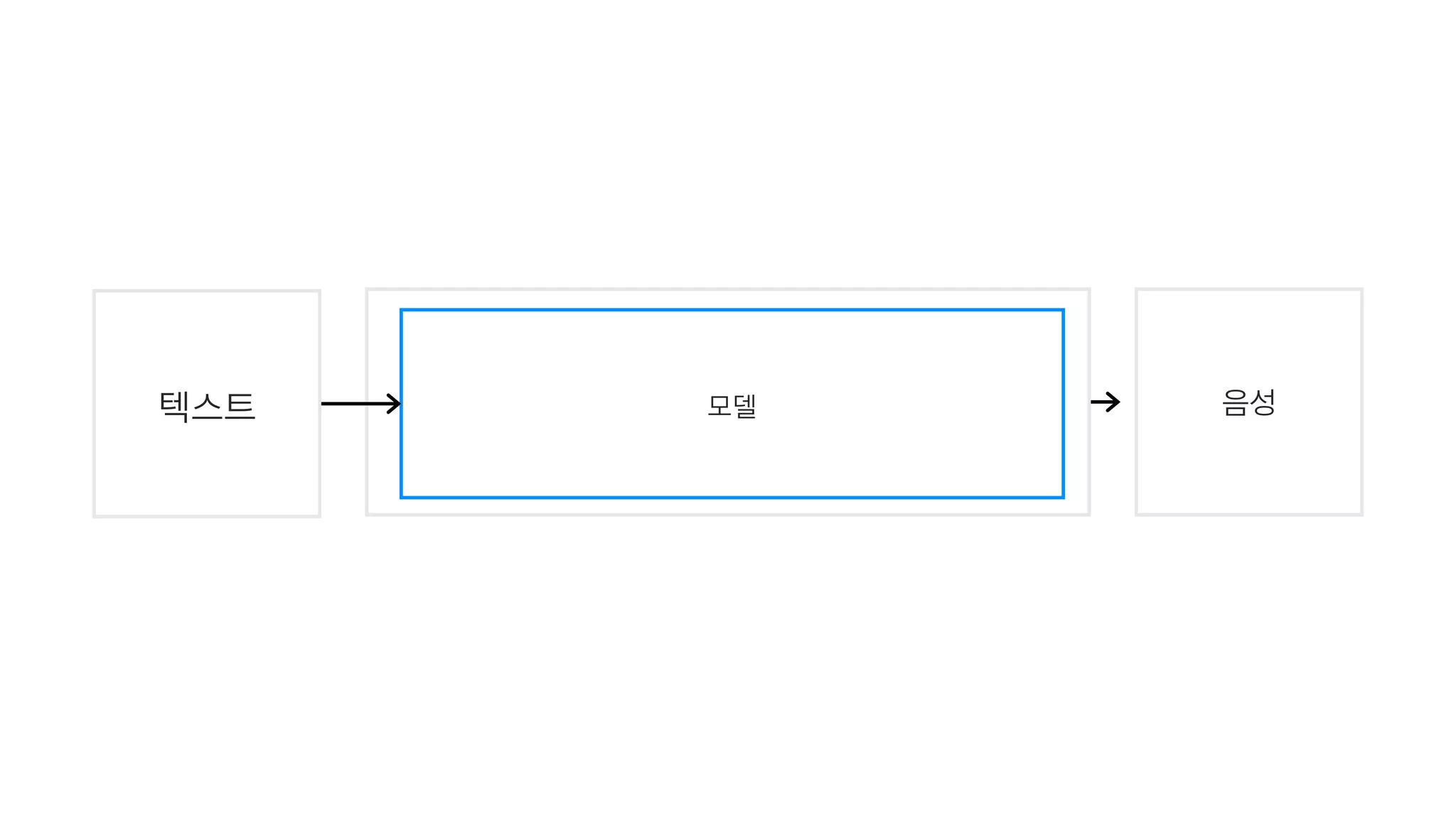
- 58. 음성토큰화 검색 + 합성 or 모델 운율 분석텍스트
- 59. 음성모델텍스트
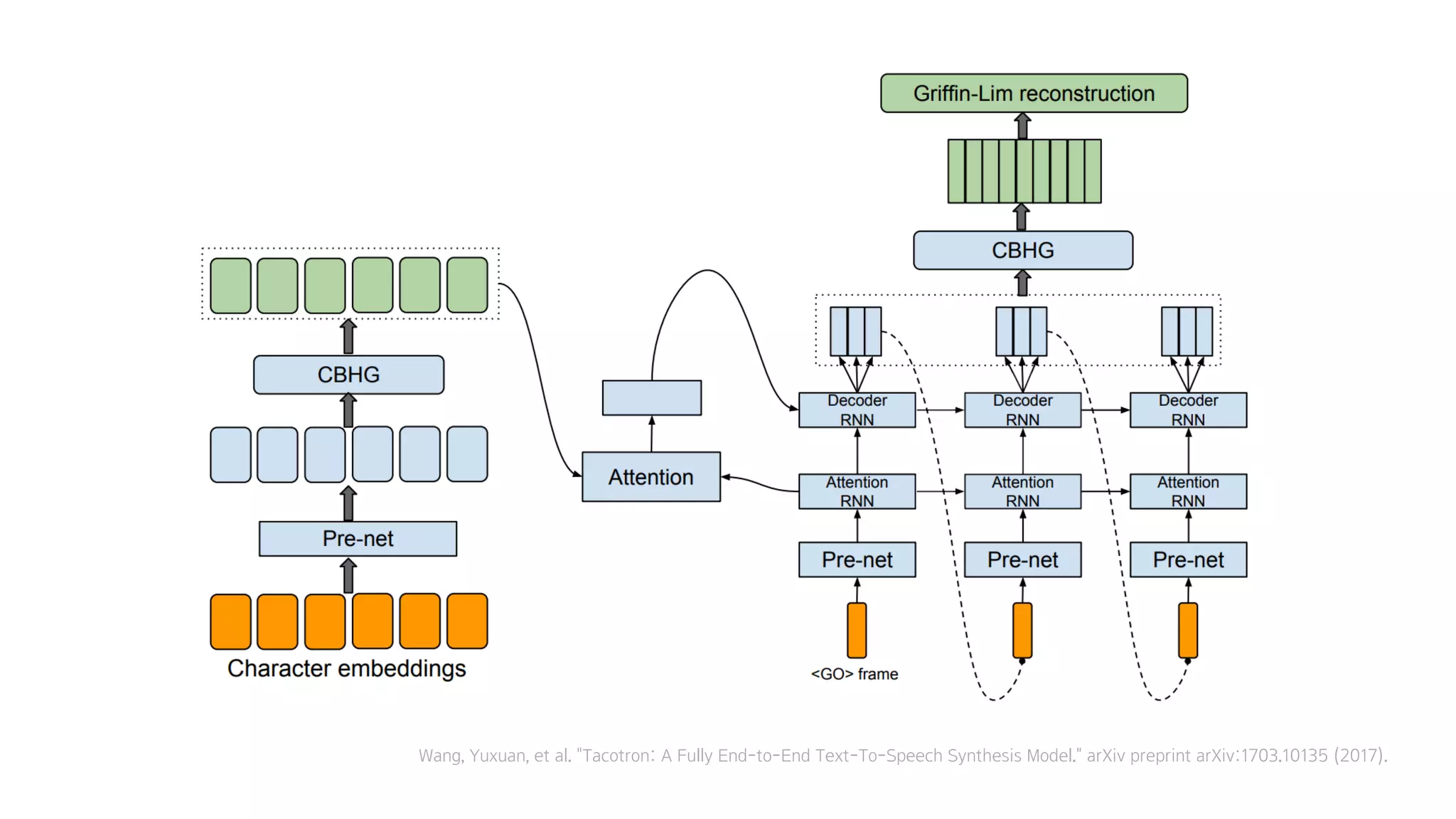
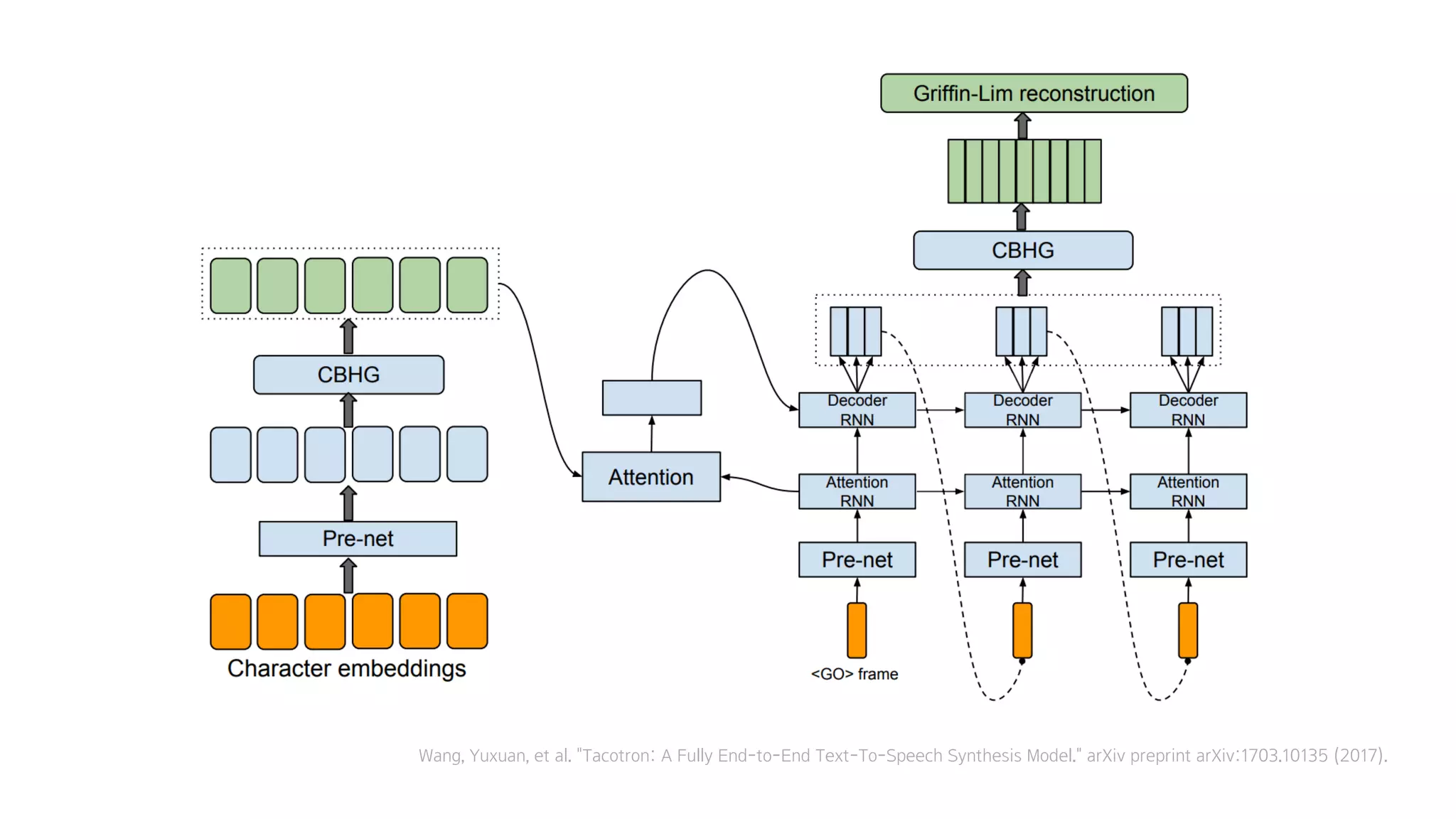
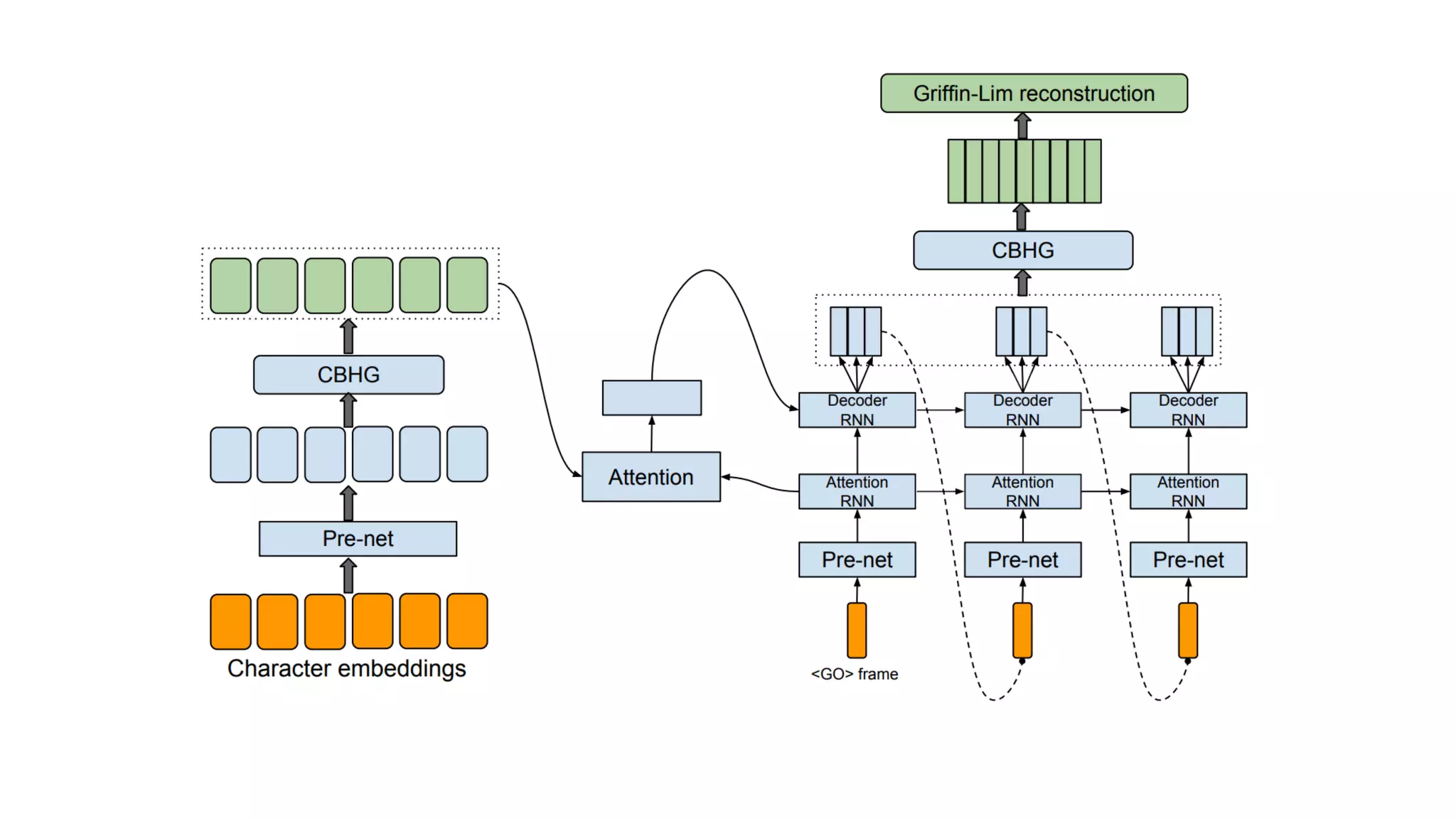
- 60. Tacotron
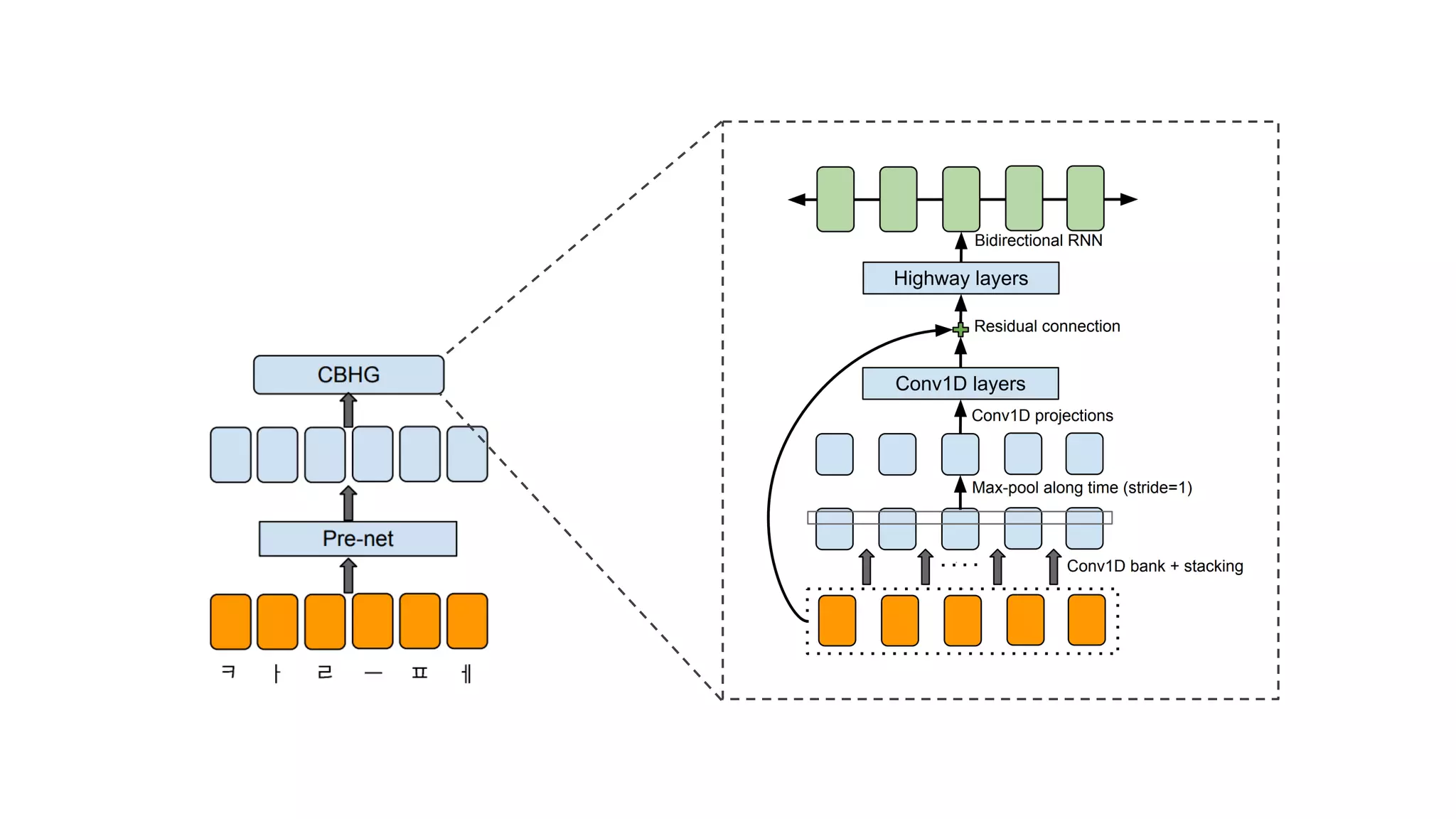
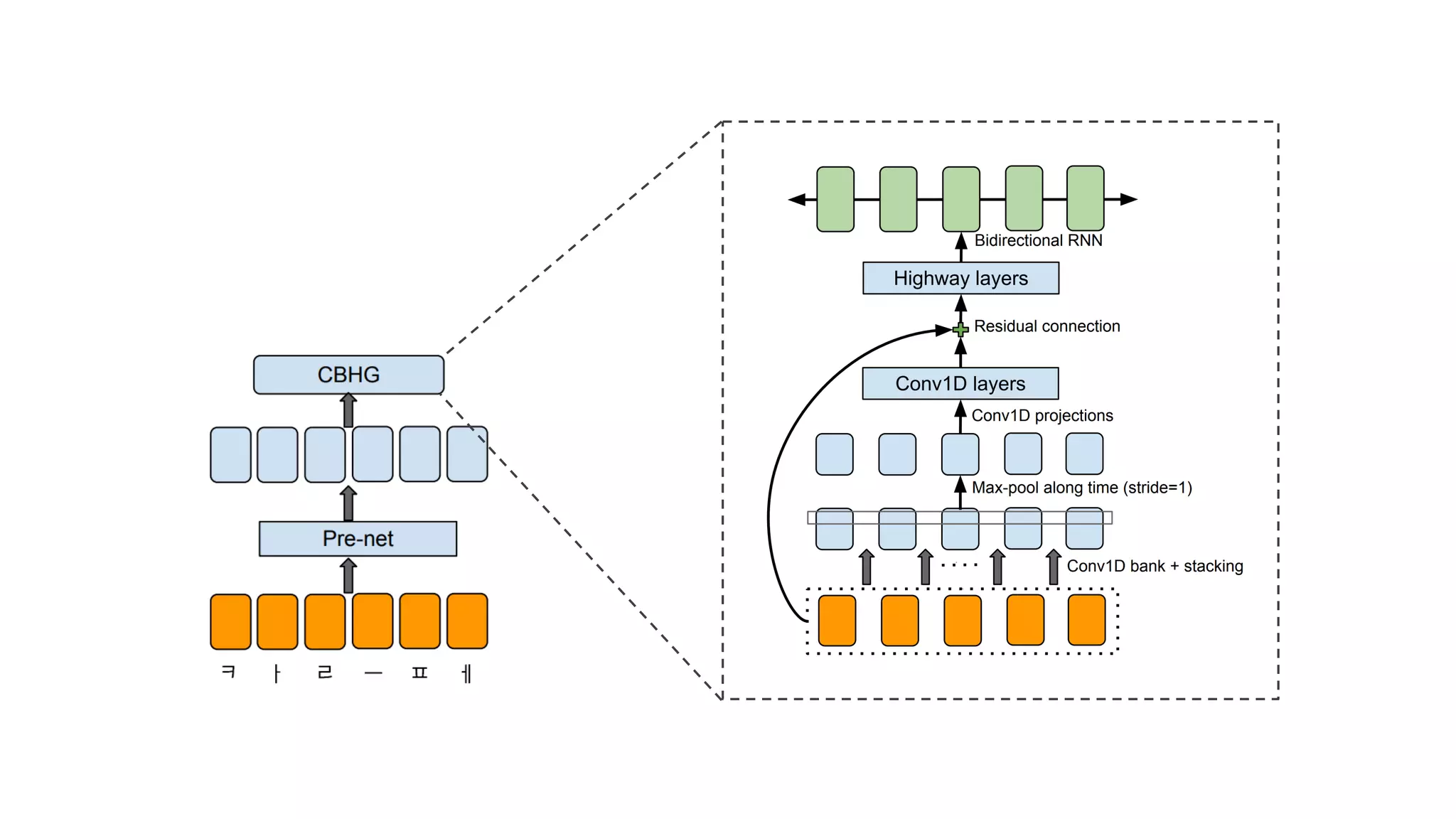
- 61. Wang, Yuxuan, et al. "Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model." arXiv preprint arXiv:1703.10135 (2017).
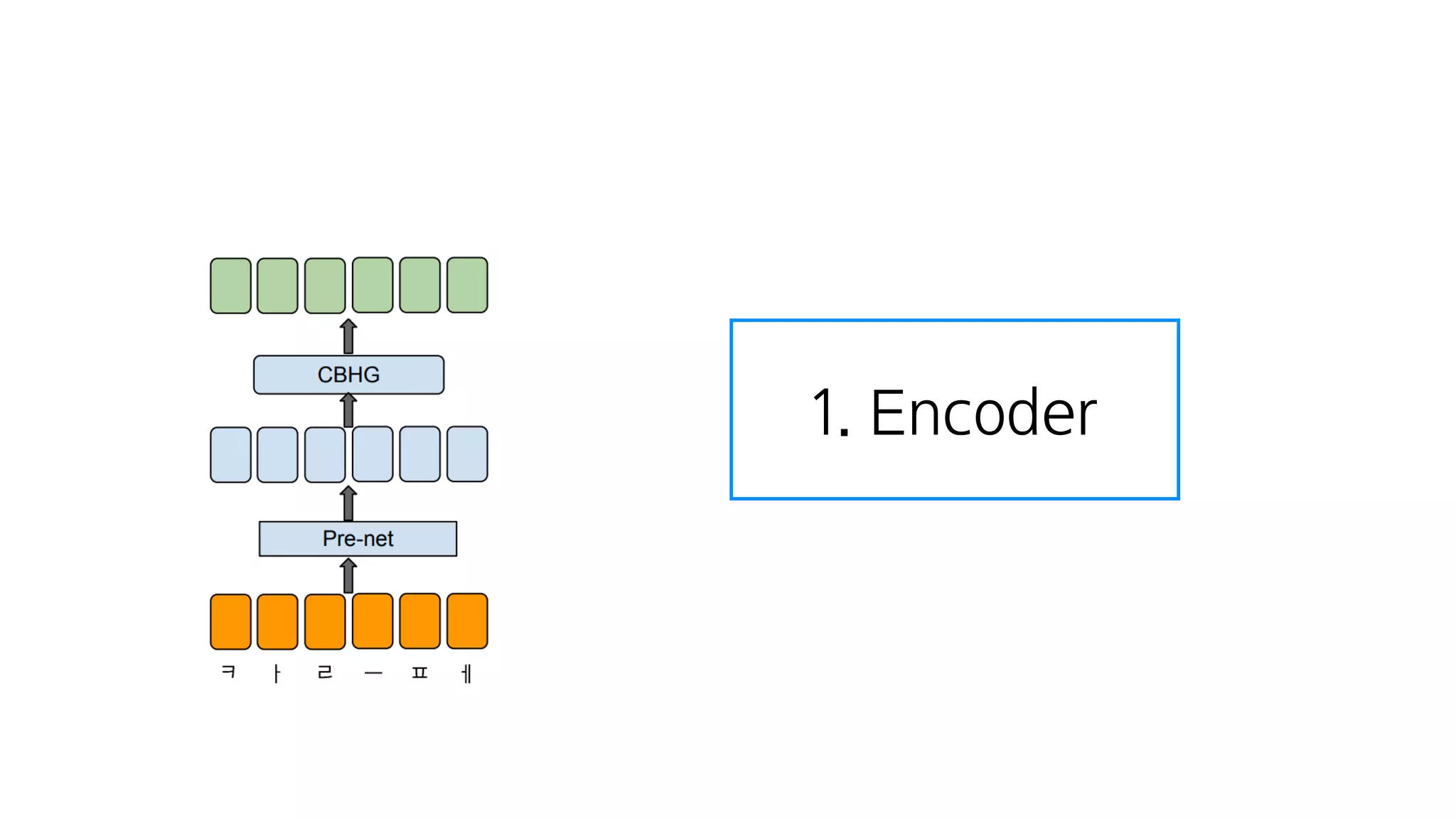
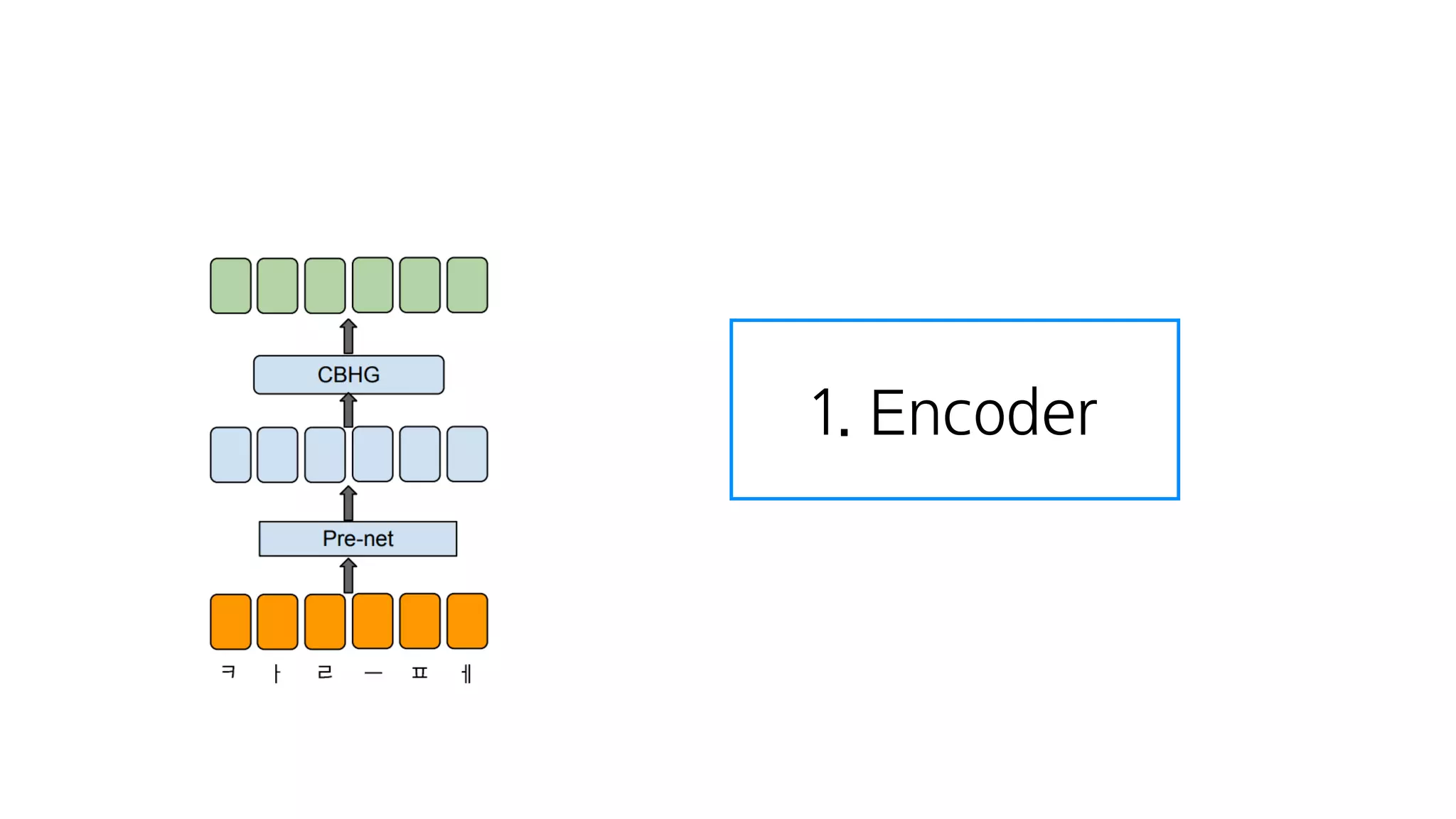
- 62. 크게 4가지 모듈로 구성
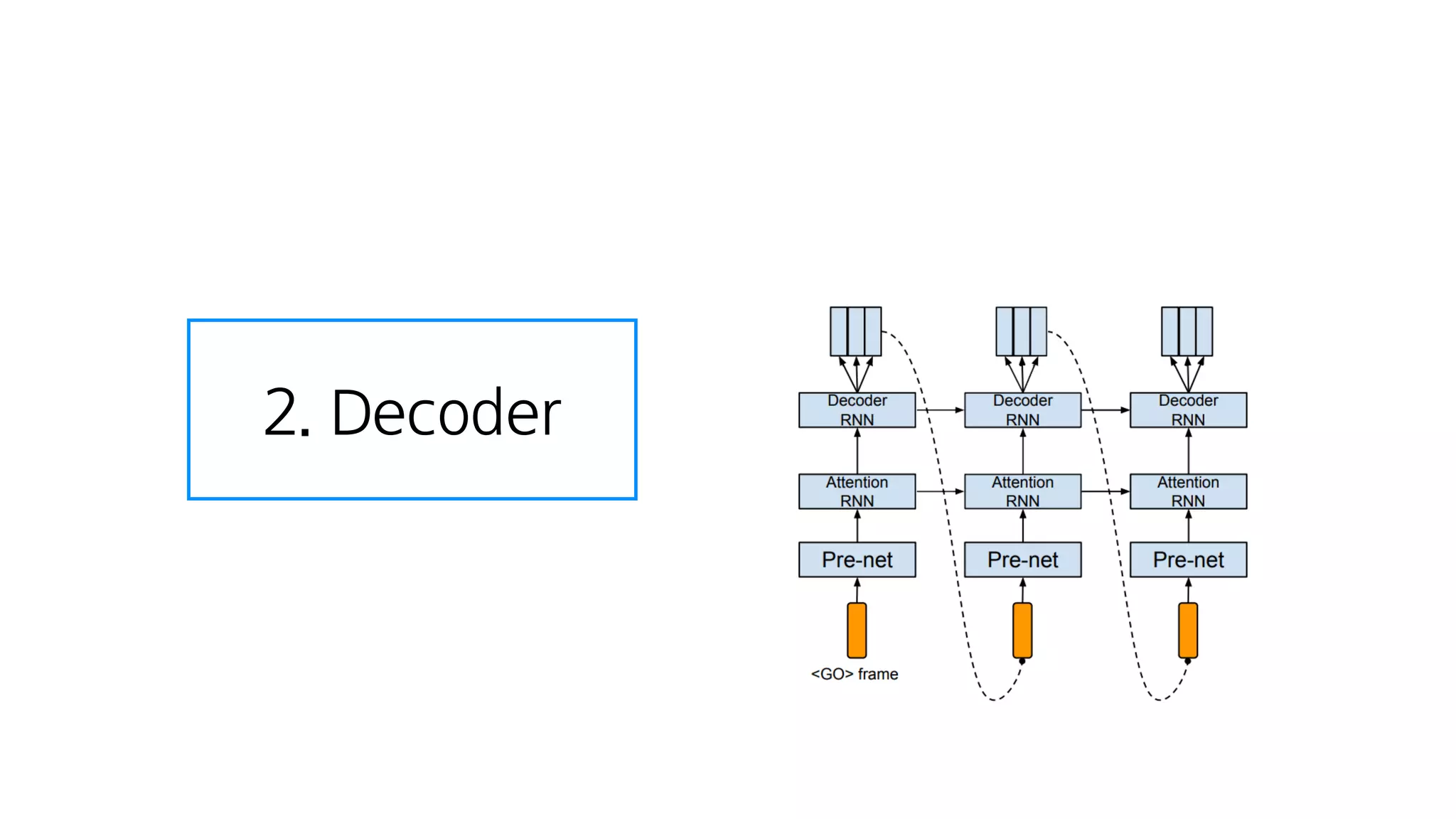
- 63. 1. Encoder
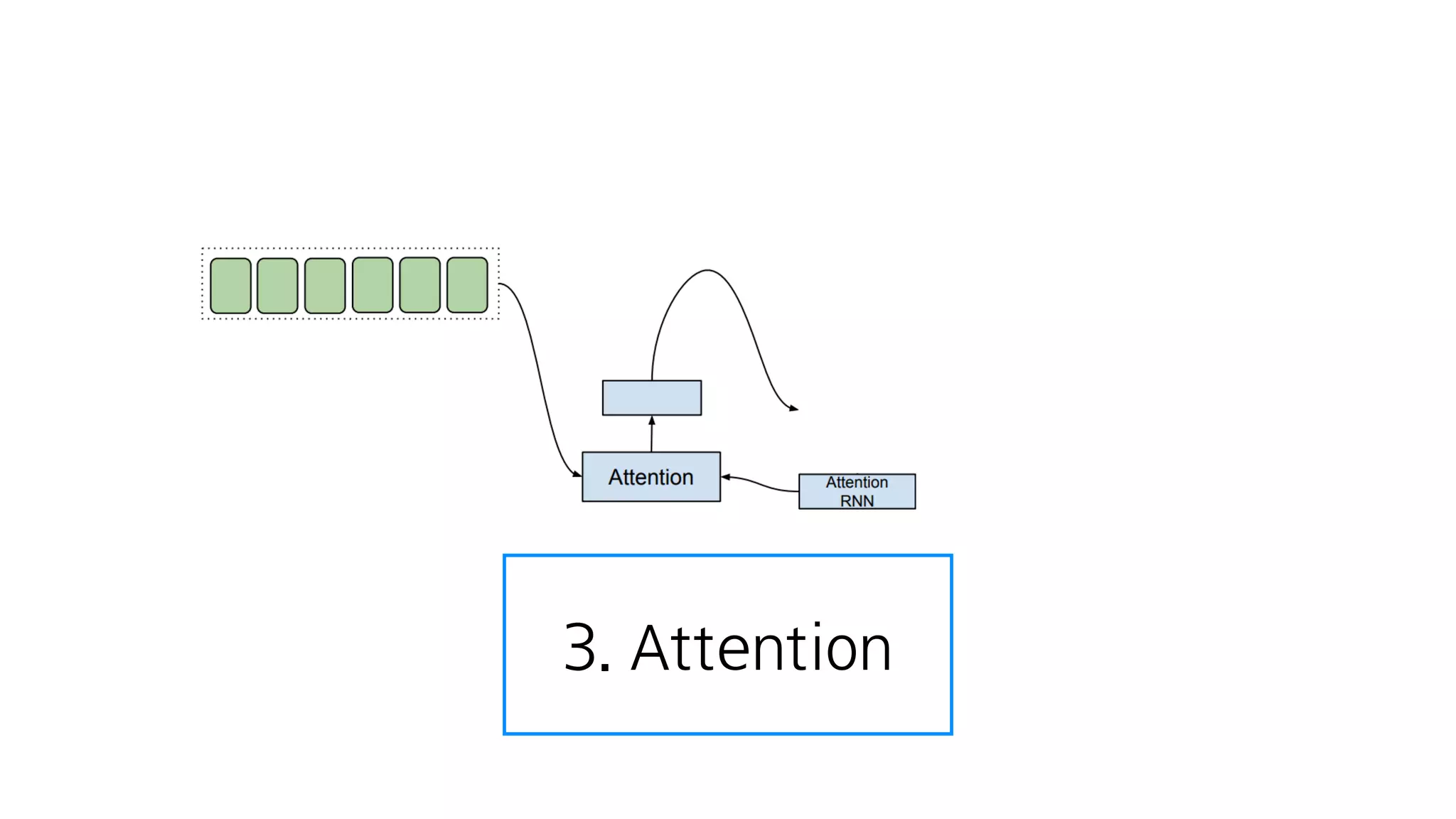
- 64. 2. Decoder
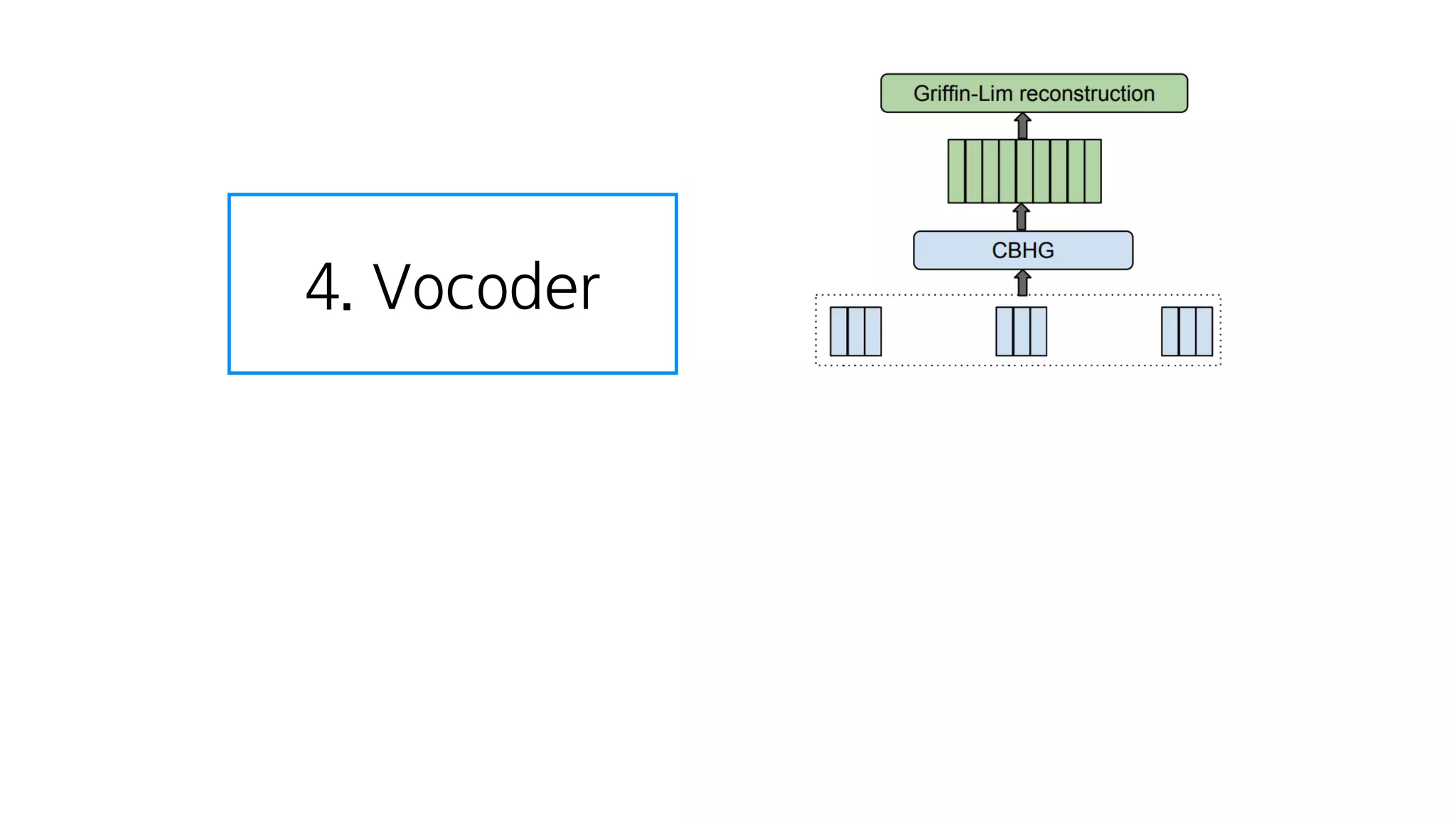
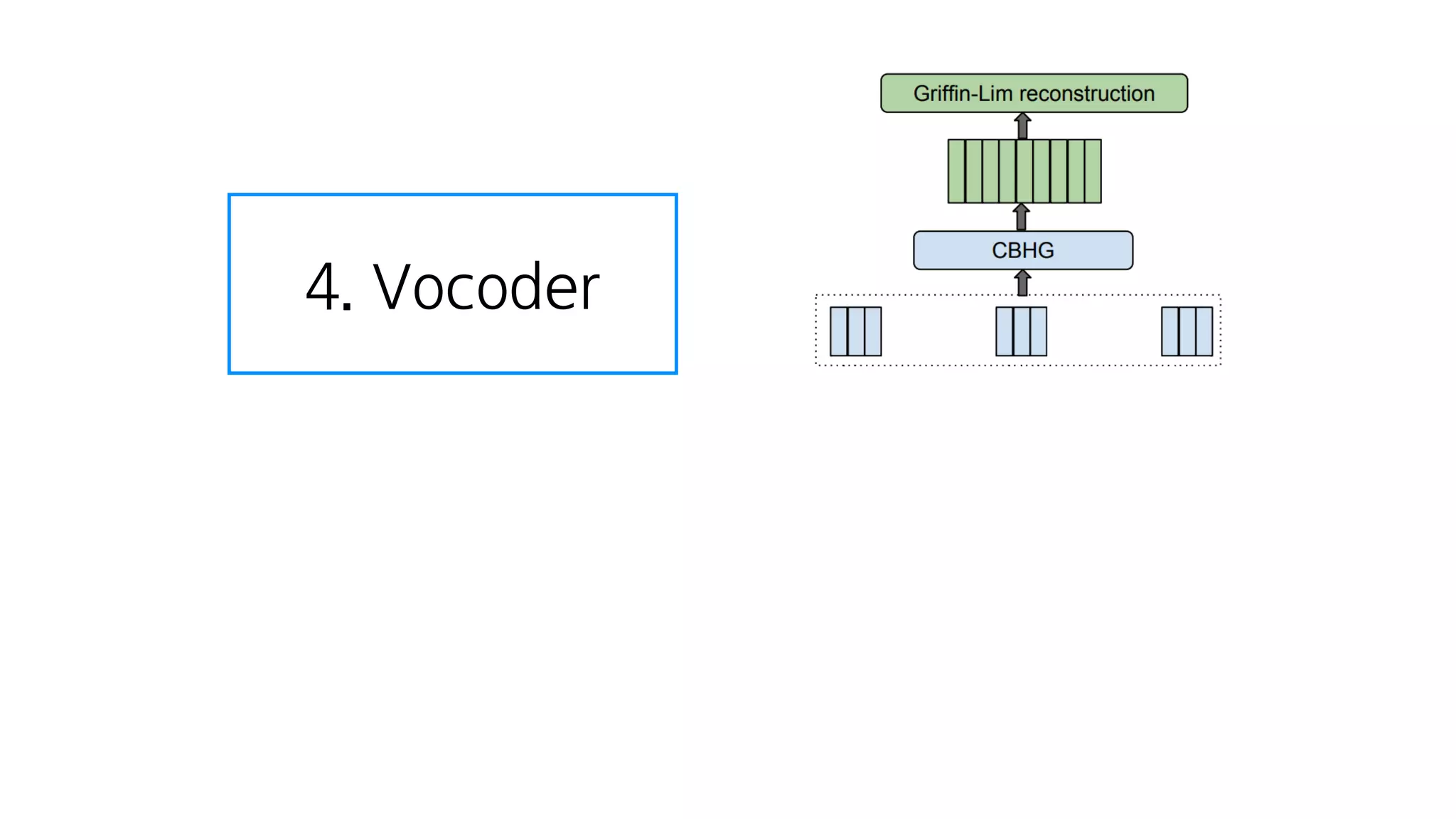
- 65. 3. Attention
- 66. 4. Vocoder
- 67. 하나씩 설명해 보겠습니다
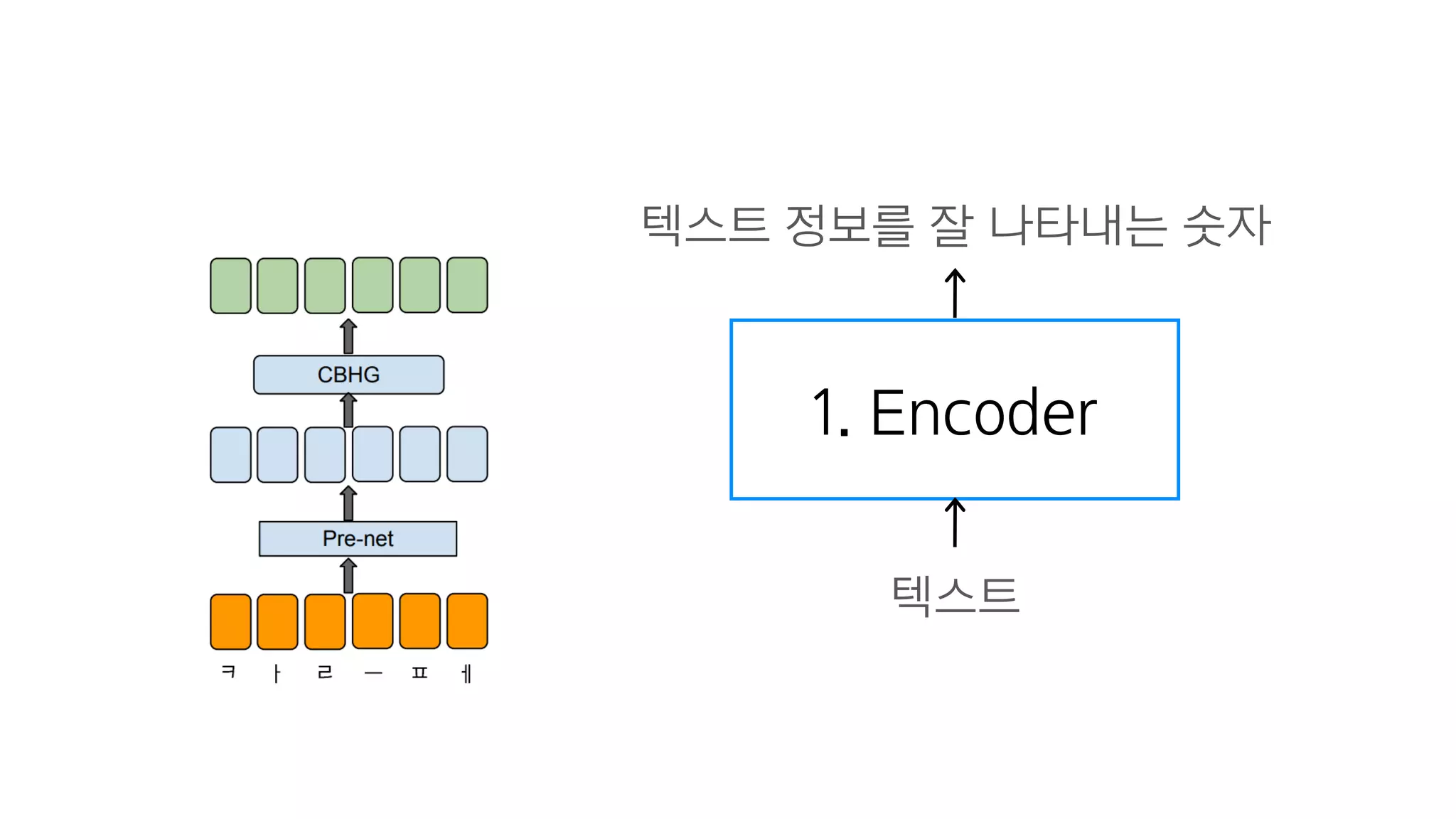
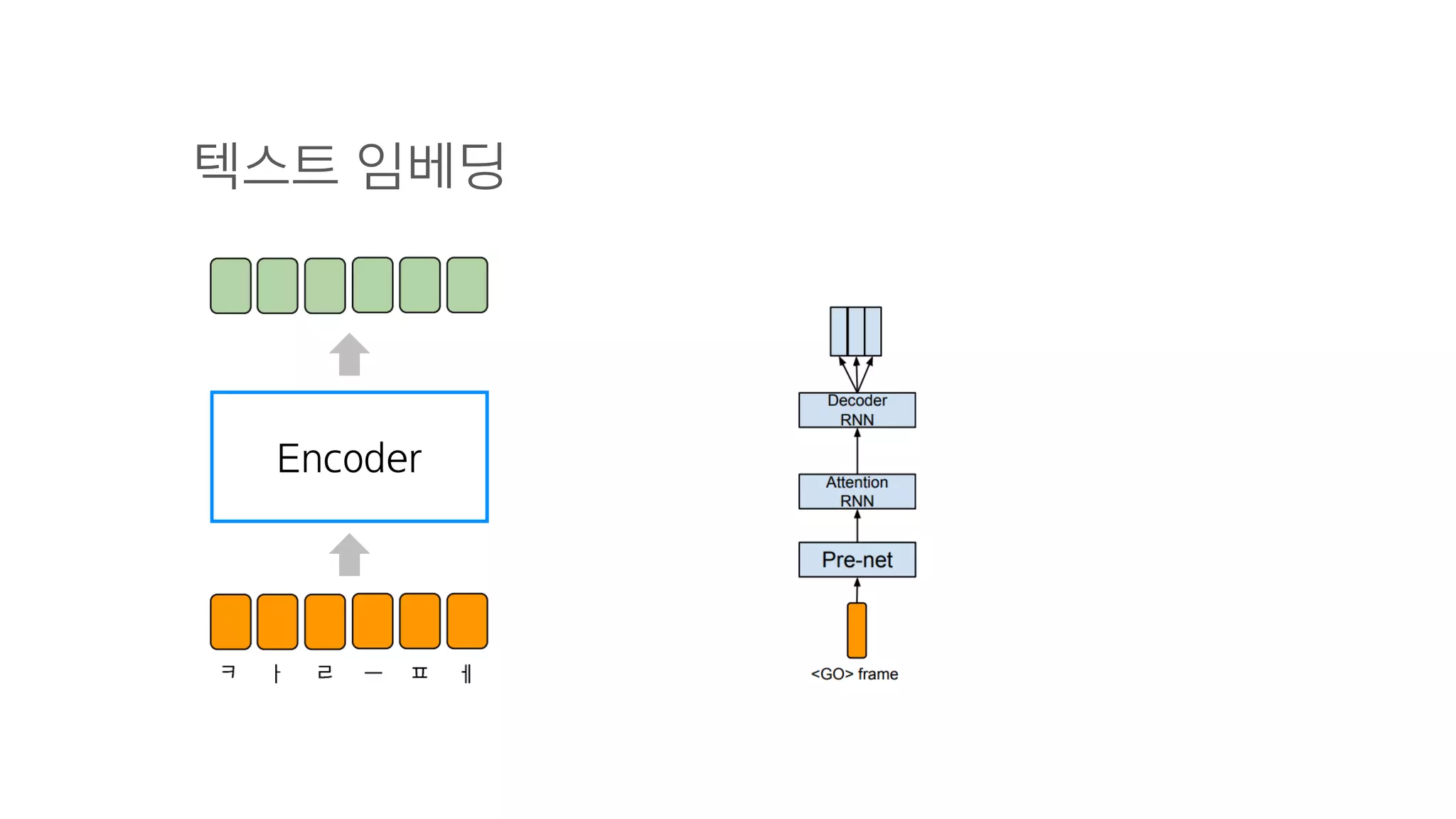
- 68. 1. Encoder
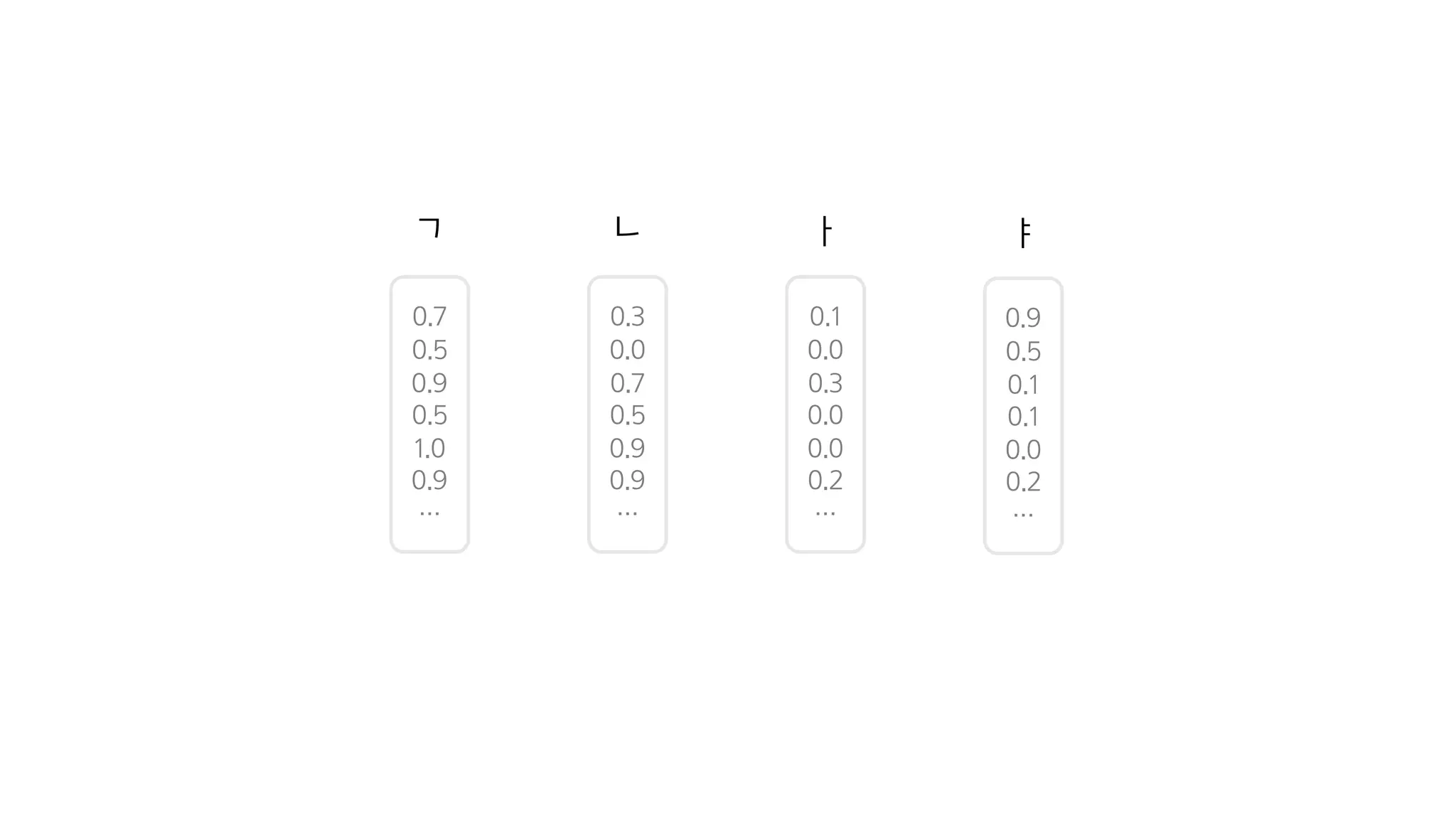
- 69. 1. Encoder 텍스트 텍스트 정보를 잘 나타내는 숫자
- 70. Character Embedding이란?
- 71. 글자 →숫자 ㄱ, ㄴ, ㅏ, ㅑ
- 72. 글자 →숫자 0.1, 0.3
- 73. 글자 →숫자 딥러닝 모델이 계산을하기 위해
- 74. 0.7 0.5 0.9 0.5 1.0 0.9 … 0.3 0.0 0.7 0.5 0.9 0.9 … ㄱ ㄴ 0.1 0.0 0.3 0.0 0.0 0.2 … ㅏ 0.9 0.5 0.1 0.1 0.0 0.2 … ㅑ
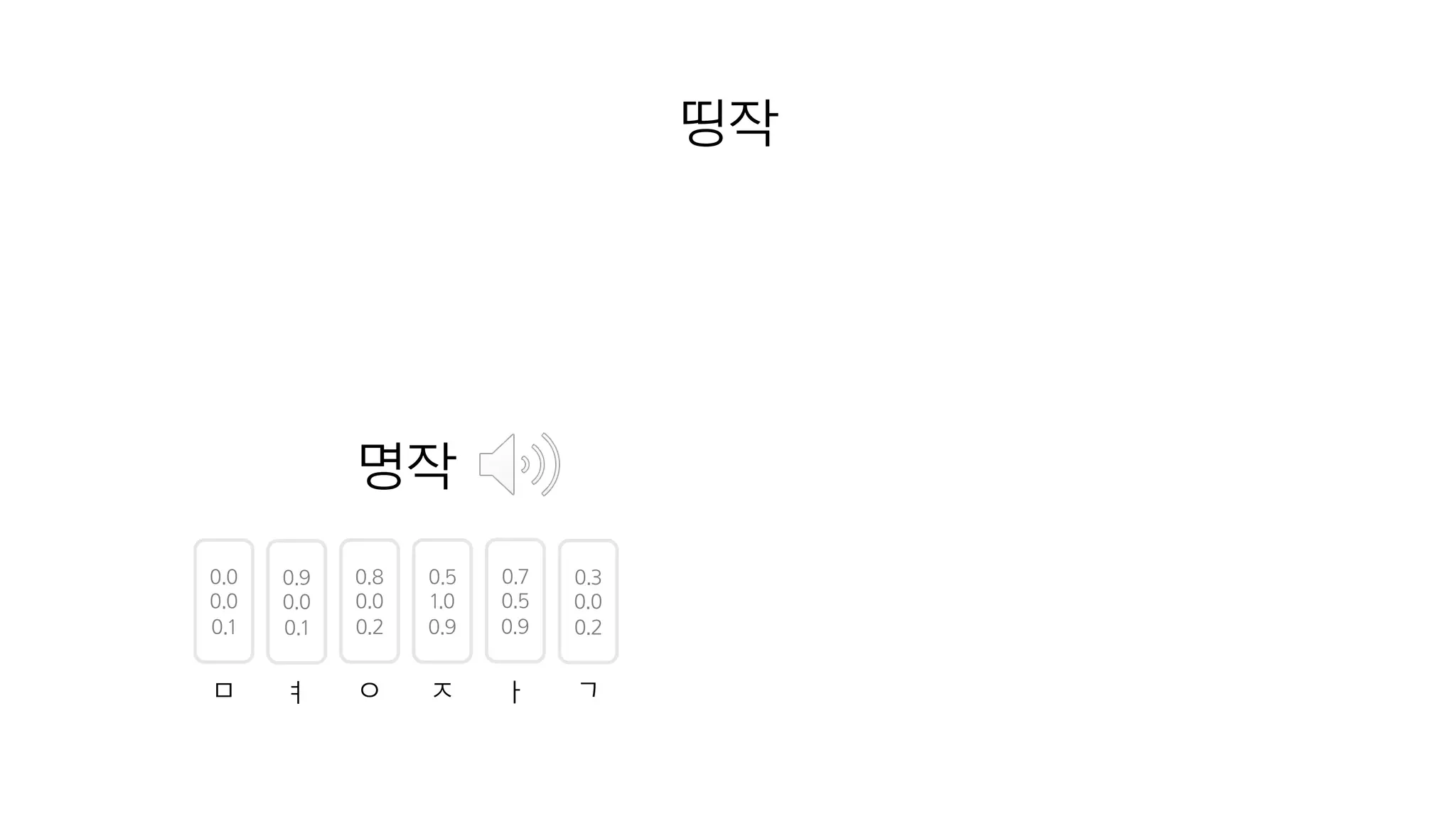
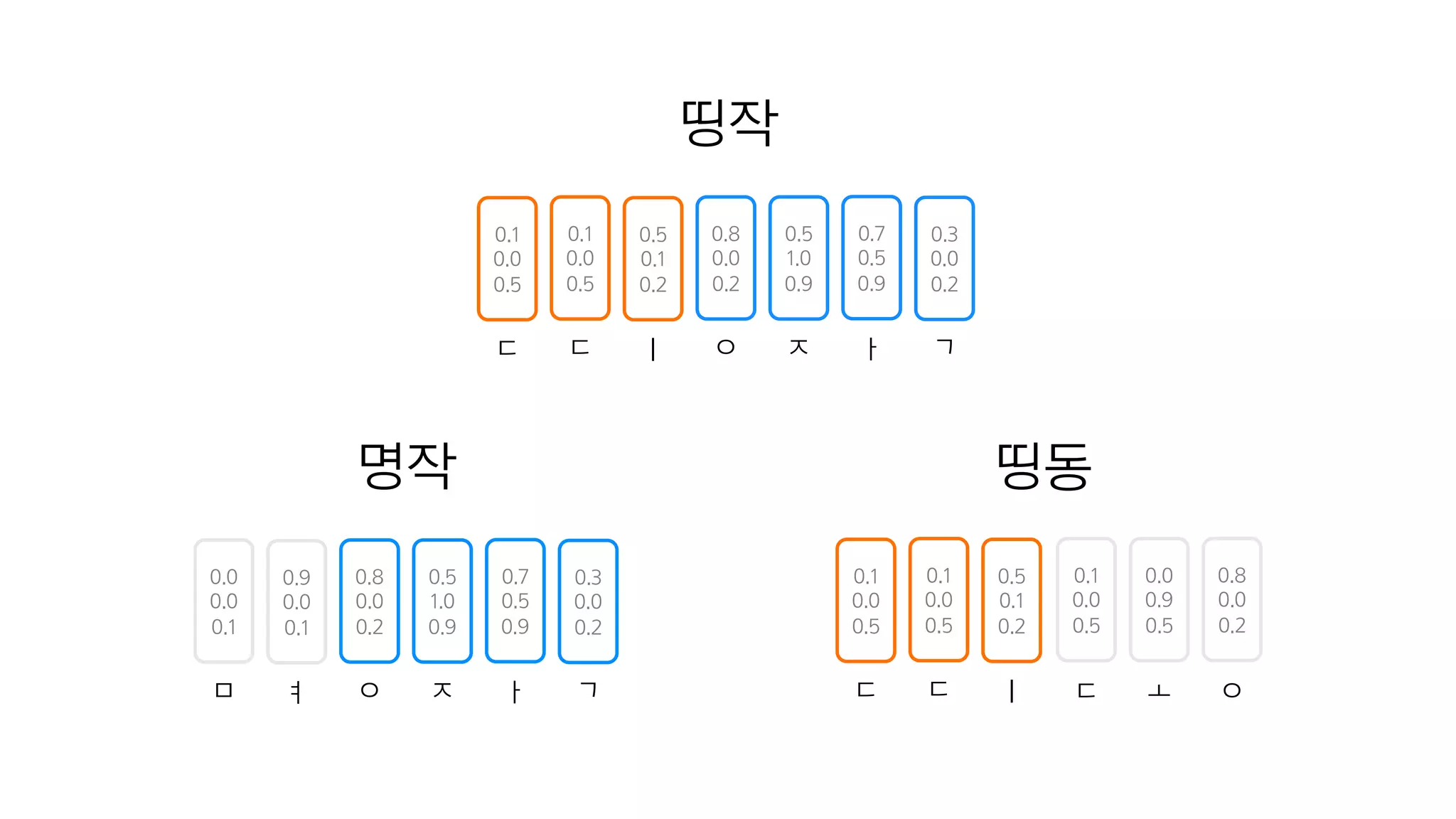
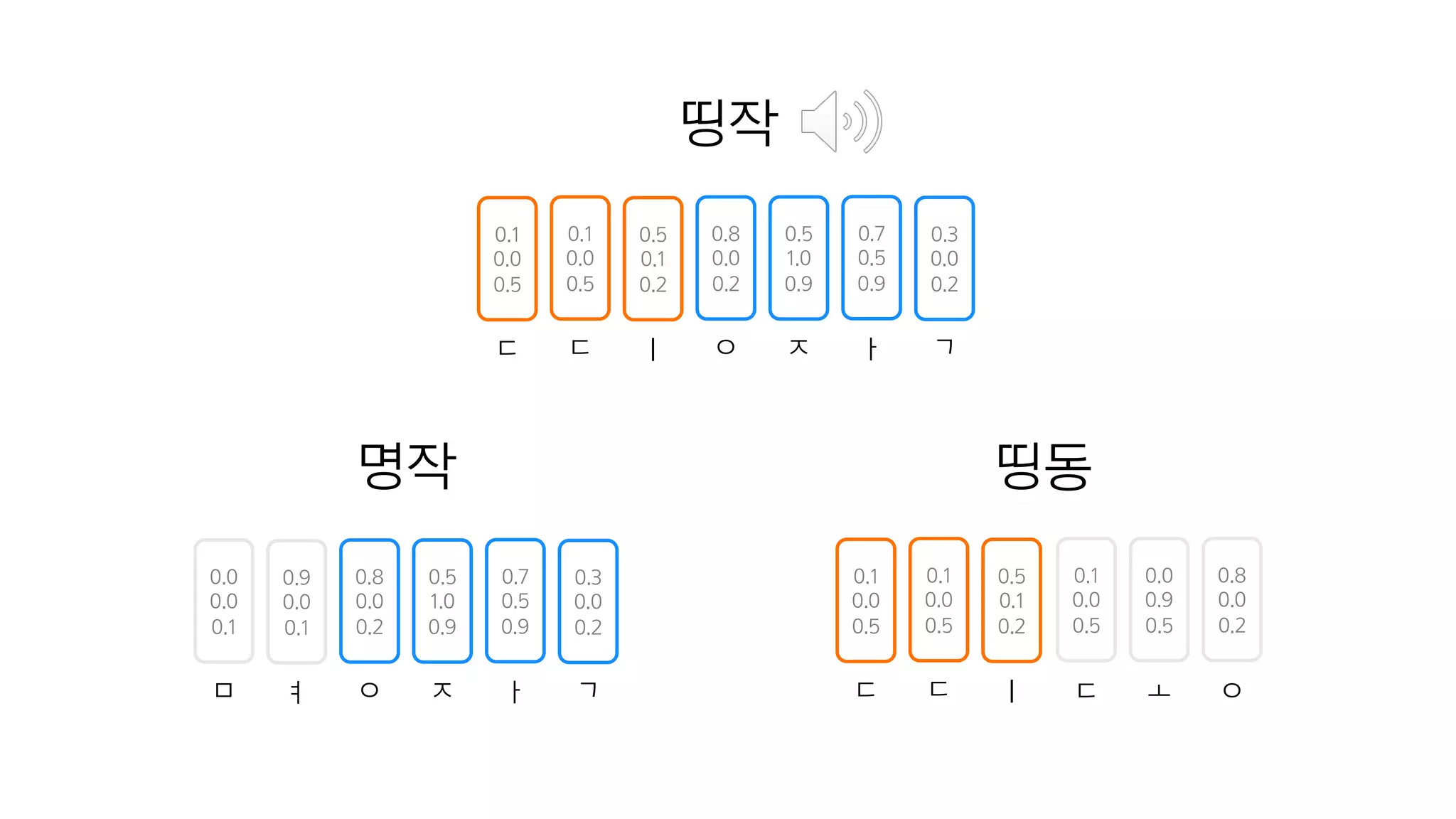
- 75. Character Embedding의 장점
- 76. 띵작
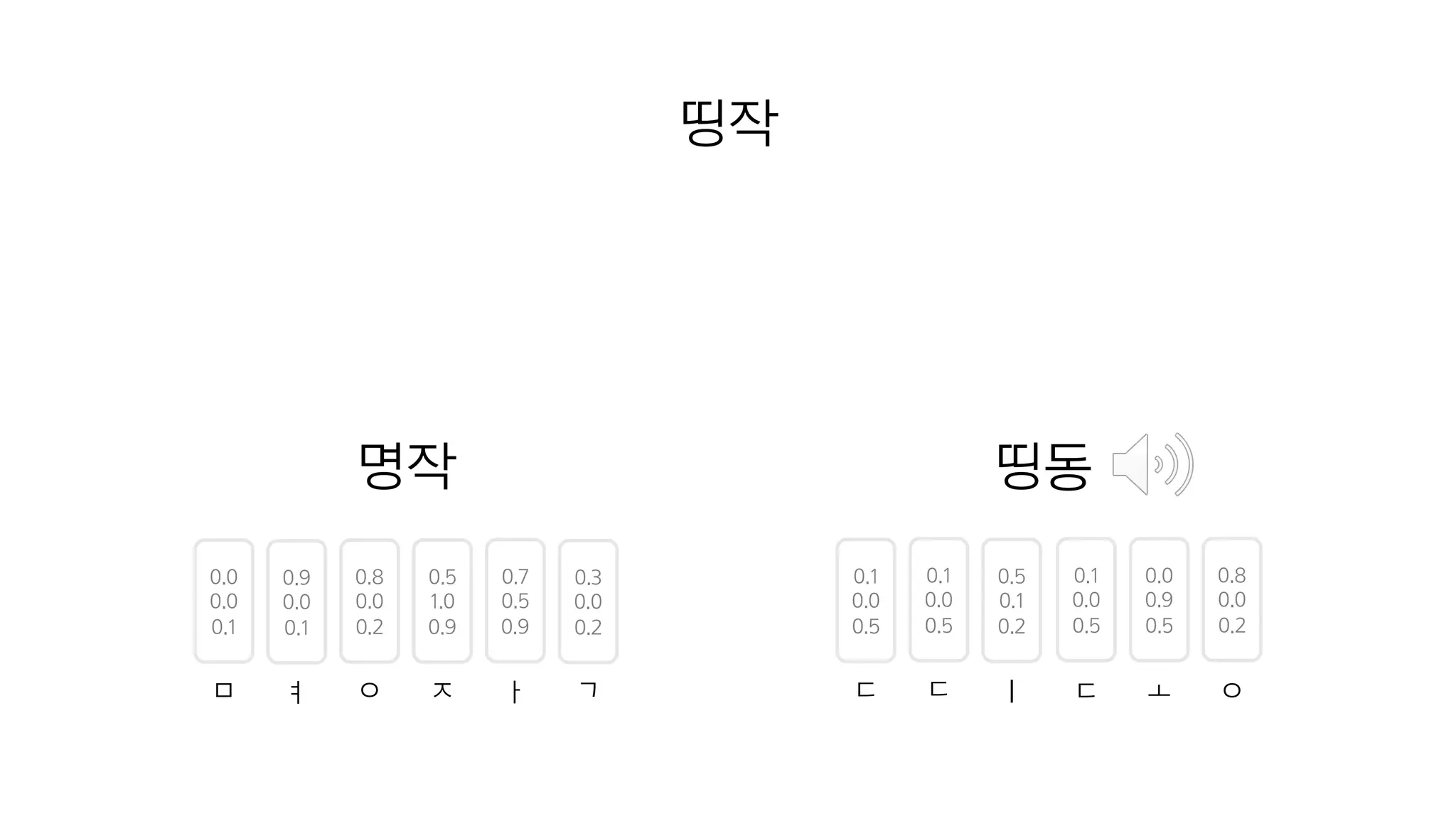
- 77. 0.0 0.0 0.1 0.9 0.0 0.1 ㅁ ㅕ 0.8 0.0 0.2 0.5 1.0 0.9 0.7 0.5 0.9 0.3 0.0 0.2 ㅇ ㅈ ㅏ ㄱ 명작 띵작
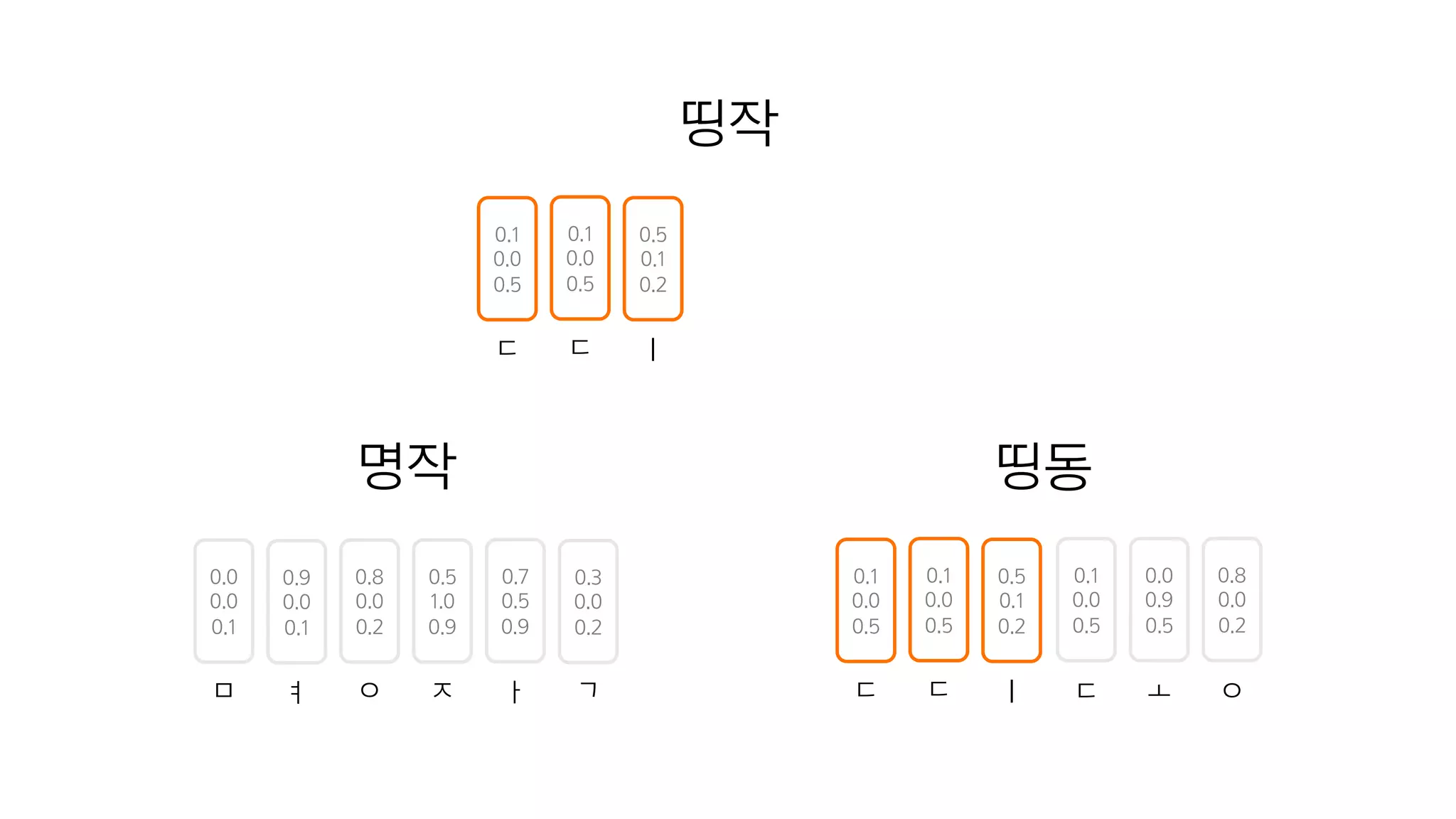
- 78. 0.0 0.0 0.1 0.9 0.0 0.1 ㅁ ㅕ 0.8 0.0 0.2 0.5 1.0 0.9 0.7 0.5 0.9 0.3 0.0 0.2 ㅇ ㅈ ㅏ ㄱ 명작 띵동 0.1 0.0 0.5 0.0 0.9 0.5 0.8 0.0 0.2 ㄷ ㅗ ㅇ 0.1 0.0 0.5 0.5 0.1 0.2 ㄷ ㅣ 0.1 0.0 0.5 ㄷ 띵작
- 79. 띵작 0.1 0.0 0.5 0.5 0.1 0.2 ㄷ ㅣ 0.1 0.0 0.5 ㄷ 0.0 0.0 0.1 0.9 0.0 0.1 0.8 0.0 0.2 0.5 1.0 0.9 0.7 0.5 0.9 0.3 0.0 0.2 ㅁ ㅕ ㅇ ㅈ ㅏ ㄱ 명작 띵동 0.1 0.0 0.5 0.0 0.9 0.5 0.8 0.0 0.2 ㄷ ㅗ ㅇ 0.1 0.0 0.5 0.5 0.1 0.2 ㄷ ㅣ 0.1 0.0 0.5 ㄷ
- 80. 0.8 0.0 0.2 0.5 1.0 0.9 0.7 0.5 0.9 0.3 0.0 0.2 ㅇ ㅈ ㅏ ㄱ 띵작 0.1 0.0 0.5 0.5 0.1 0.2 ㄷ ㅣ 0.1 0.0 0.5 ㄷ 0.0 0.0 0.1 0.9 0.0 0.1 0.8 0.0 0.2 0.5 1.0 0.9 0.7 0.5 0.9 0.3 0.0 0.2 ㅁ ㅕ ㅇ ㅈ ㅏ ㄱ 명작 띵동 0.1 0.0 0.5 0.0 0.9 0.5 0.8 0.0 0.2 ㄷ ㅗ ㅇ 0.1 0.0 0.5 0.5 0.1 0.2 ㄷ ㅣ 0.1 0.0 0.5 ㄷ
- 81. 0.8 0.0 0.2 0.5 1.0 0.9 0.7 0.5 0.9 0.3 0.0 0.2 ㅇ ㅈ ㅏ ㄱ 띵작 0.1 0.0 0.5 0.5 0.1 0.2 ㄷ ㅣ 0.1 0.0 0.5 ㄷ 0.0 0.0 0.1 0.9 0.0 0.1 0.8 0.0 0.2 0.5 1.0 0.9 0.7 0.5 0.9 0.3 0.0 0.2 ㅁ ㅕ ㅇ ㅈ ㅏ ㄱ 명작 띵동 0.1 0.0 0.5 0.0 0.9 0.5 0.8 0.0 0.2 ㄷ ㅗ ㅇ 0.1 0.0 0.5 0.5 0.1 0.2 ㄷ ㅣ 0.1 0.0 0.5 ㄷ
- 82. ᄀ ᄁ ᄂ ᄃ ᄄ ᄅ ᄆ ᄇ ᄈ ᄉ ᄊ ᄋ ᄌ ᄍ ᄎ ᄏ ᄐ ᄑ ᄒ ᅡ ᅢ ᅣ ᅤ ᅥ ᅦ ᅧ ᅨ ᅩ ᅪ ᅫ ᅬ ᅭ ᅮ ᅯ ᅰ ᅱ ᅲ ᅳ ᅴ ᅵ ᆨ ᆩ ᆪ ᆫ ᆬ ᆭ ᆮ ᆯ ᆰ ᆱ ᆲ ᆳ ᆴ ᆵ ᆶ ᆷ ᆸ ᆹ ᆺ ᆻ ᆼ ᆽ ᆾ ᆿ ᇀ ᇁ ᇂ ! ' ( ) , - . : ; ? _ ~
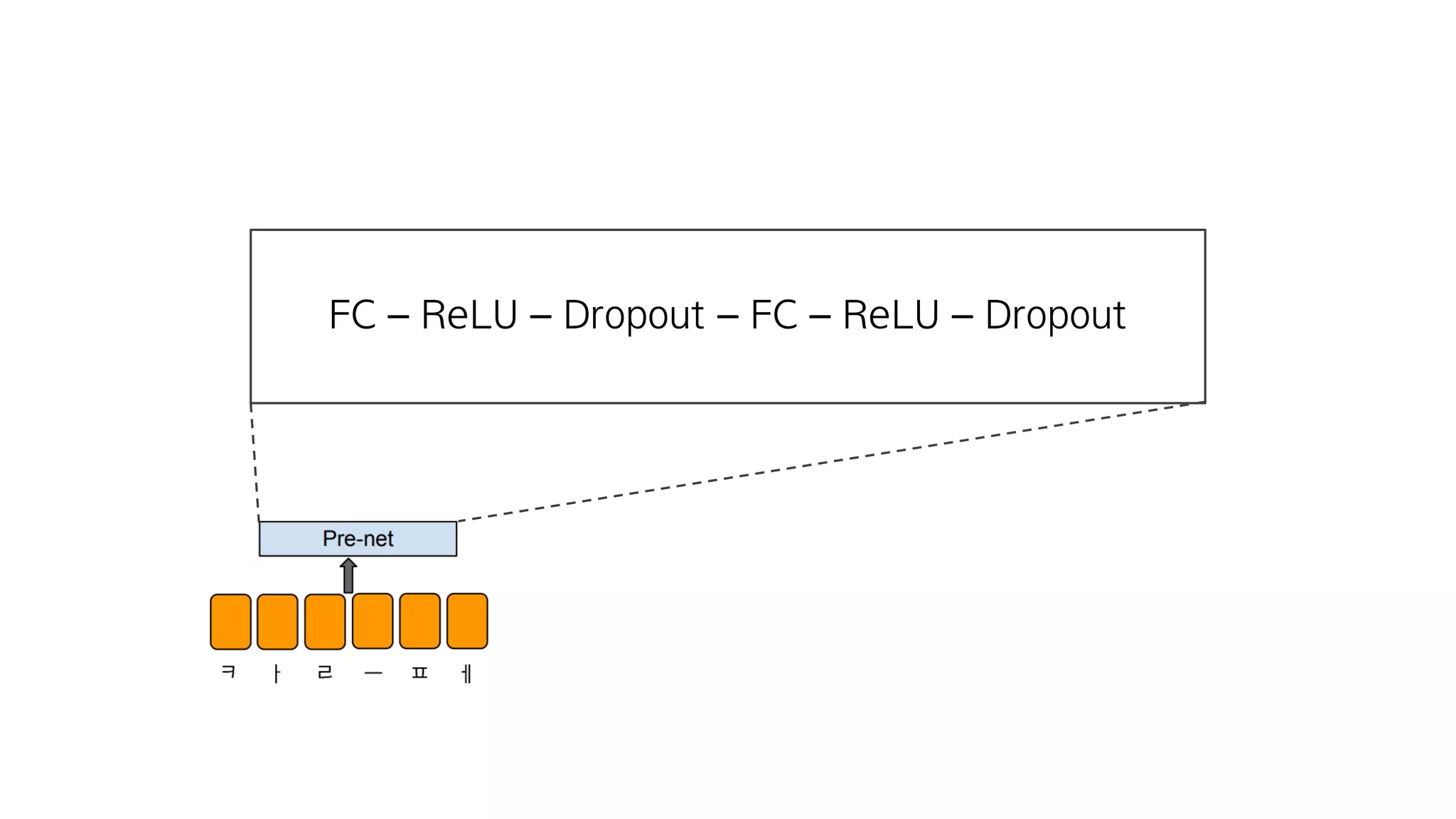
- 83. 총 80개의 Embedding
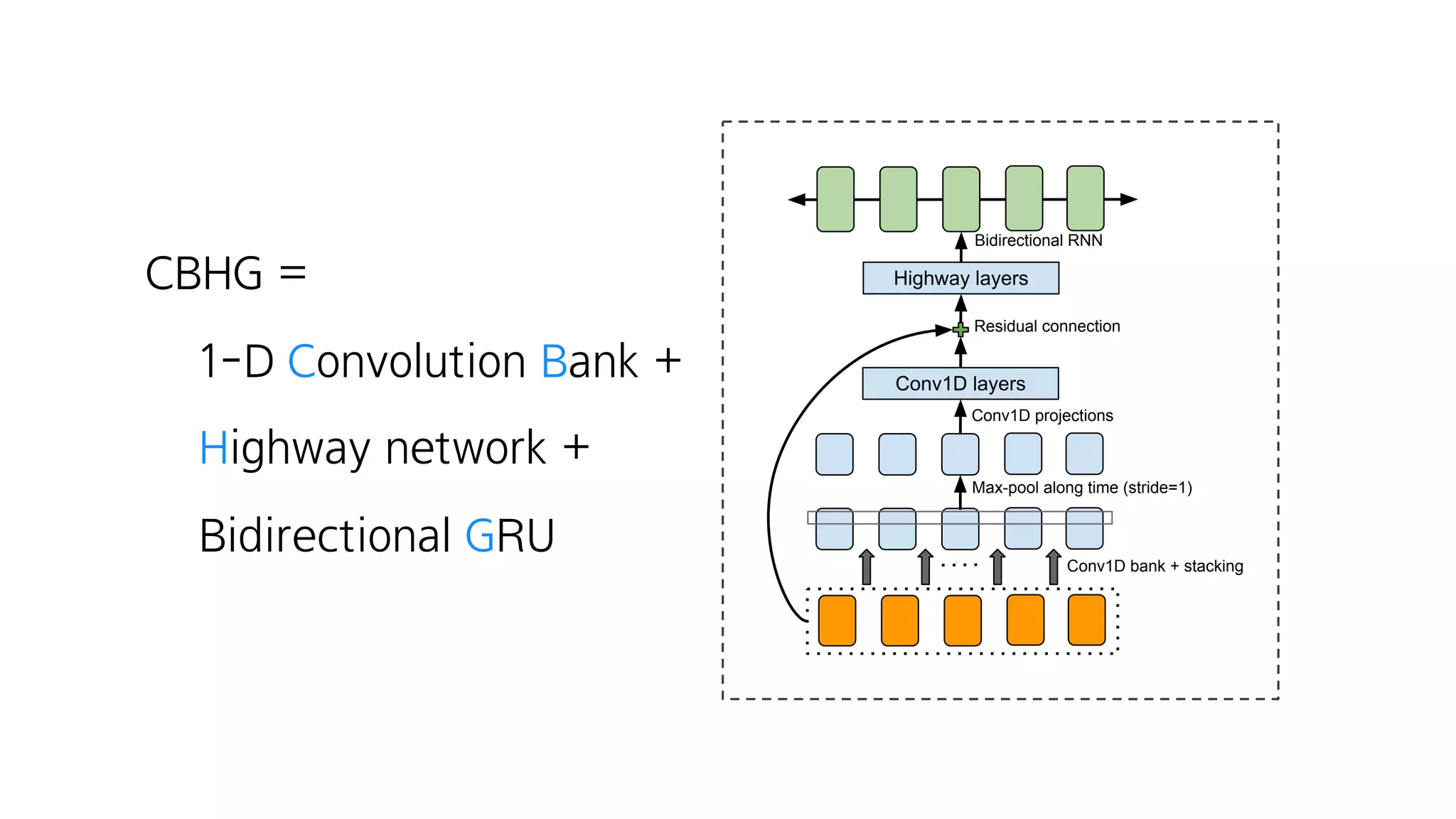
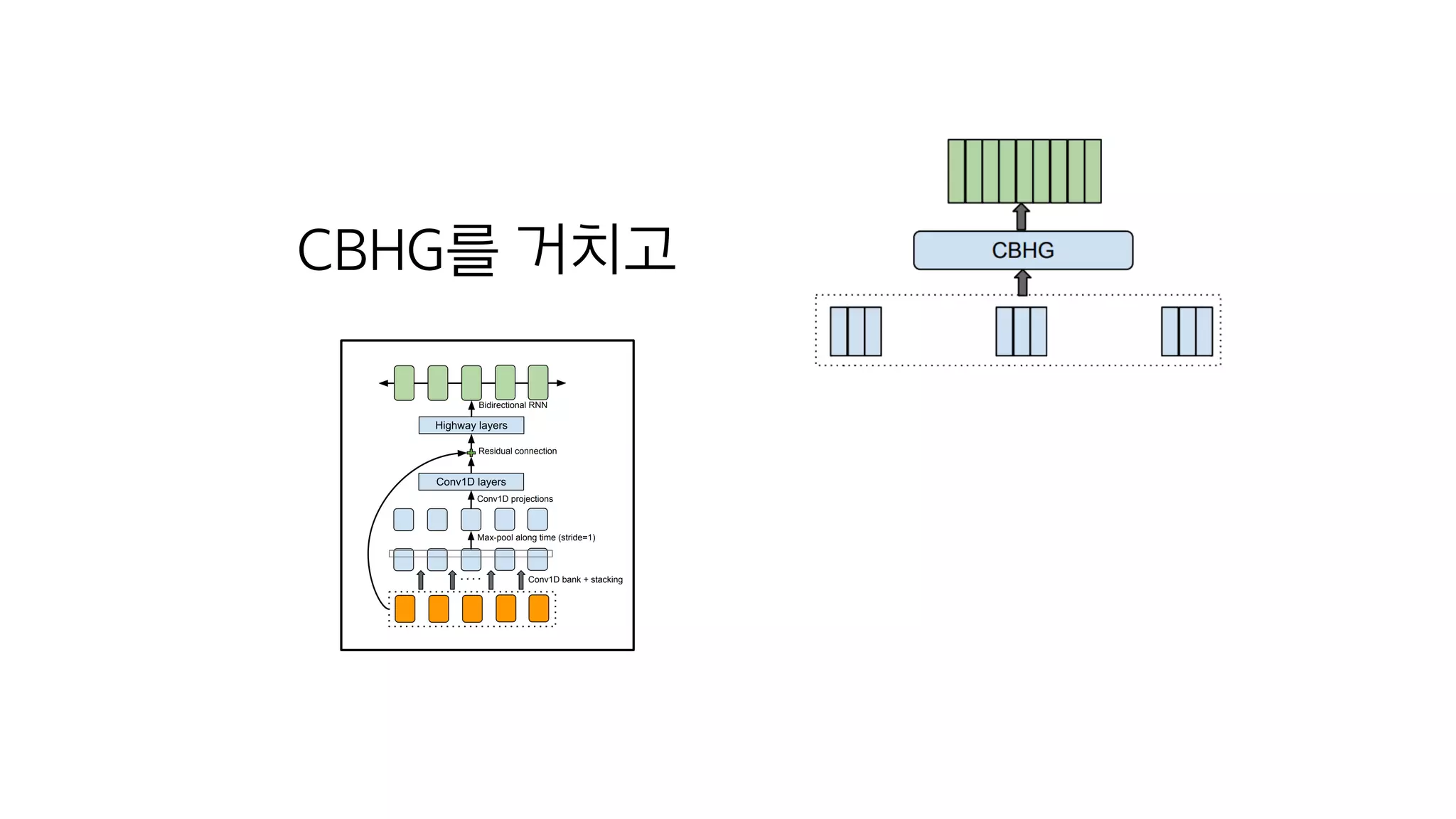
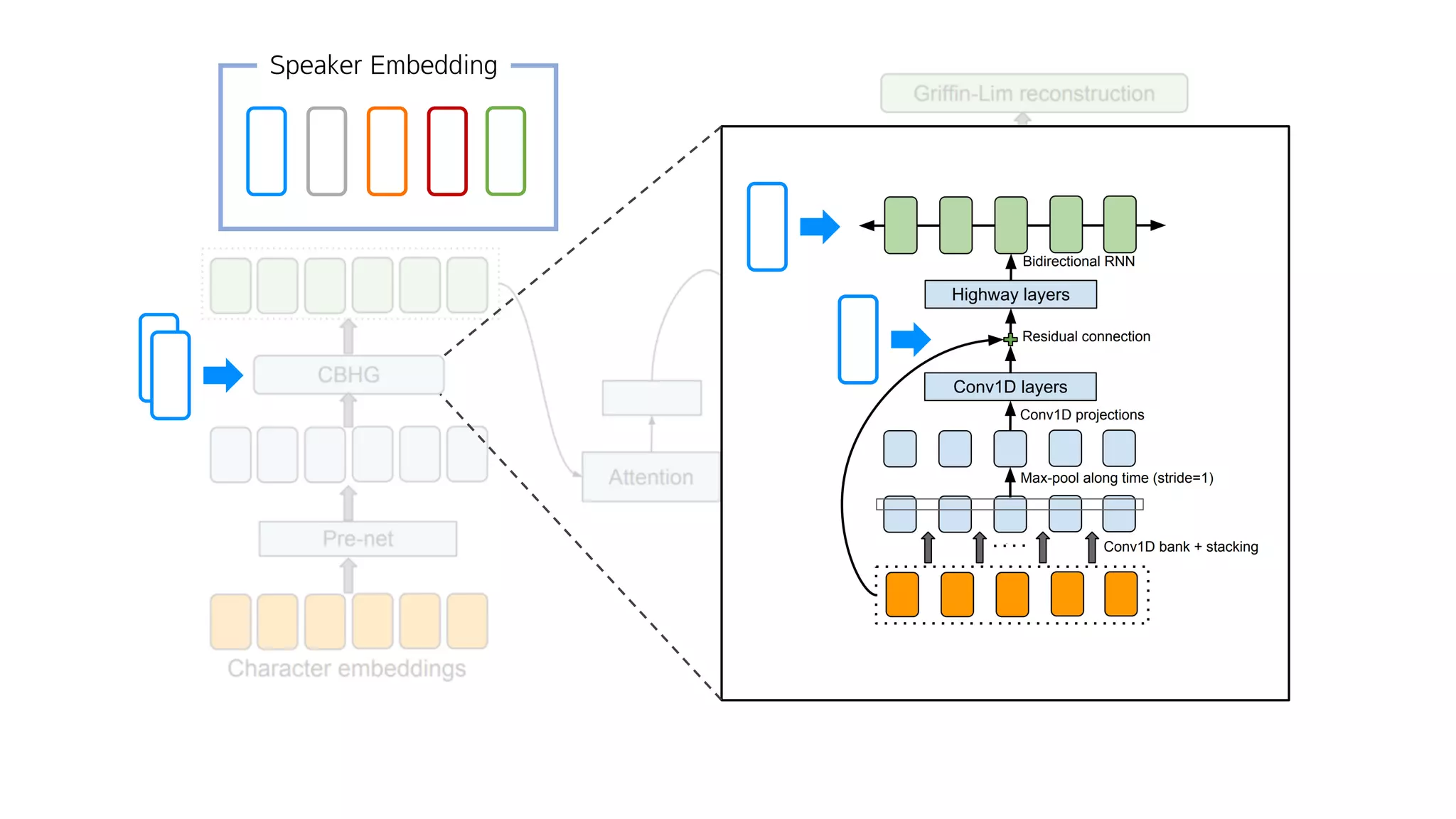
- 84. FC – ReLU – Dropout – FC – ReLU – Dropout
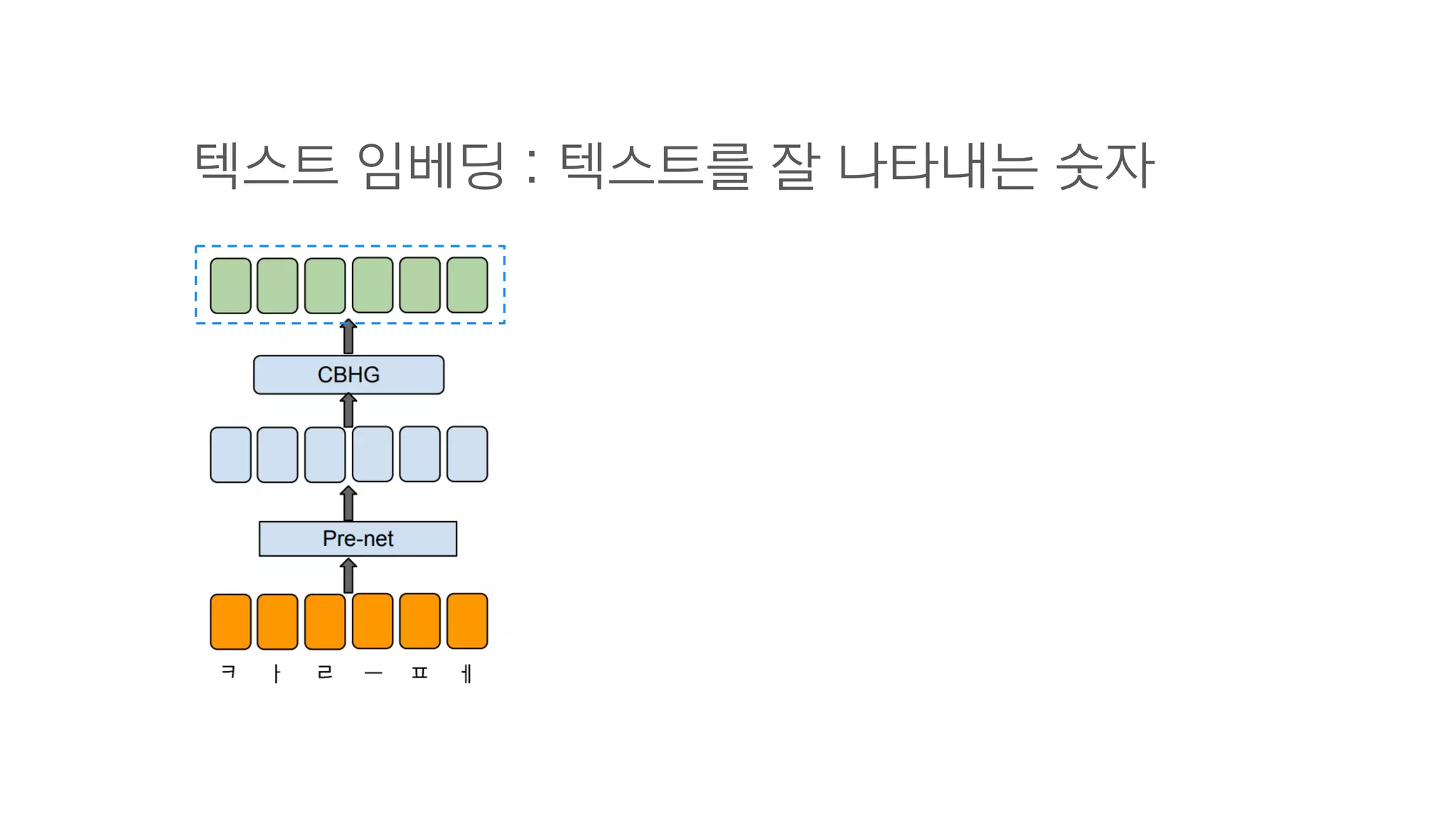
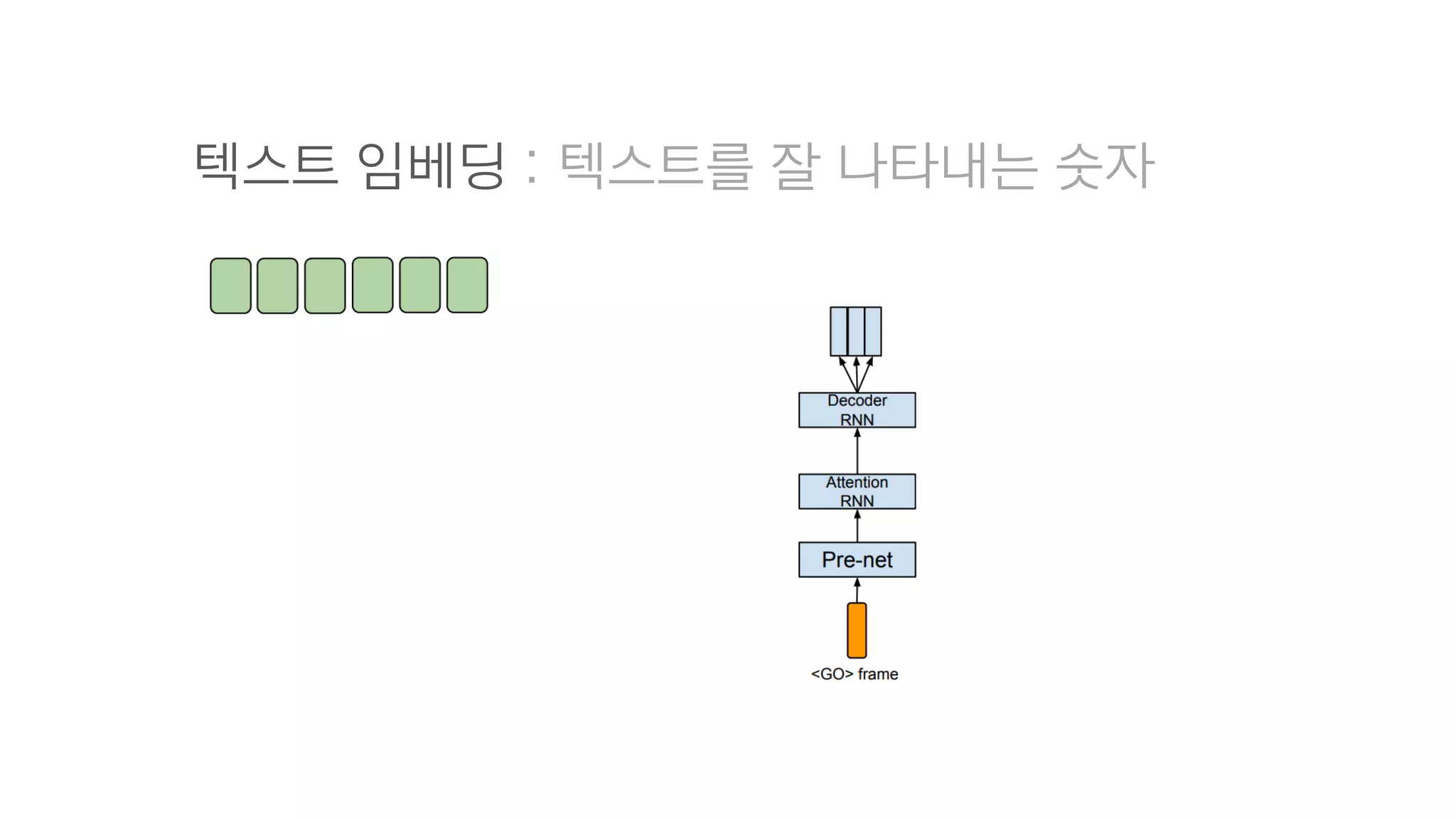
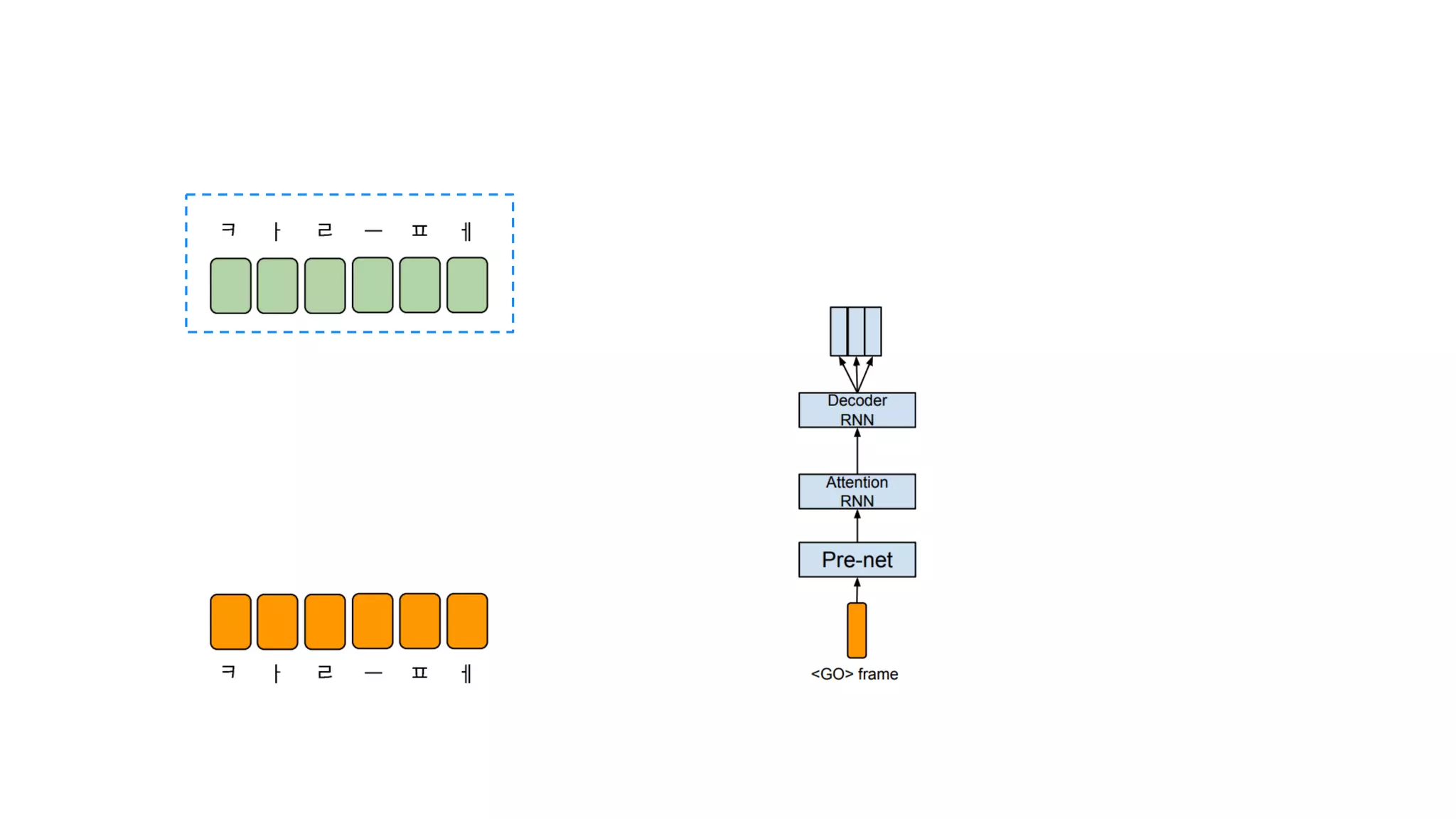
- 85. CBHG = 1-D Convolution Bank + Highway network + Bidirectional GRU
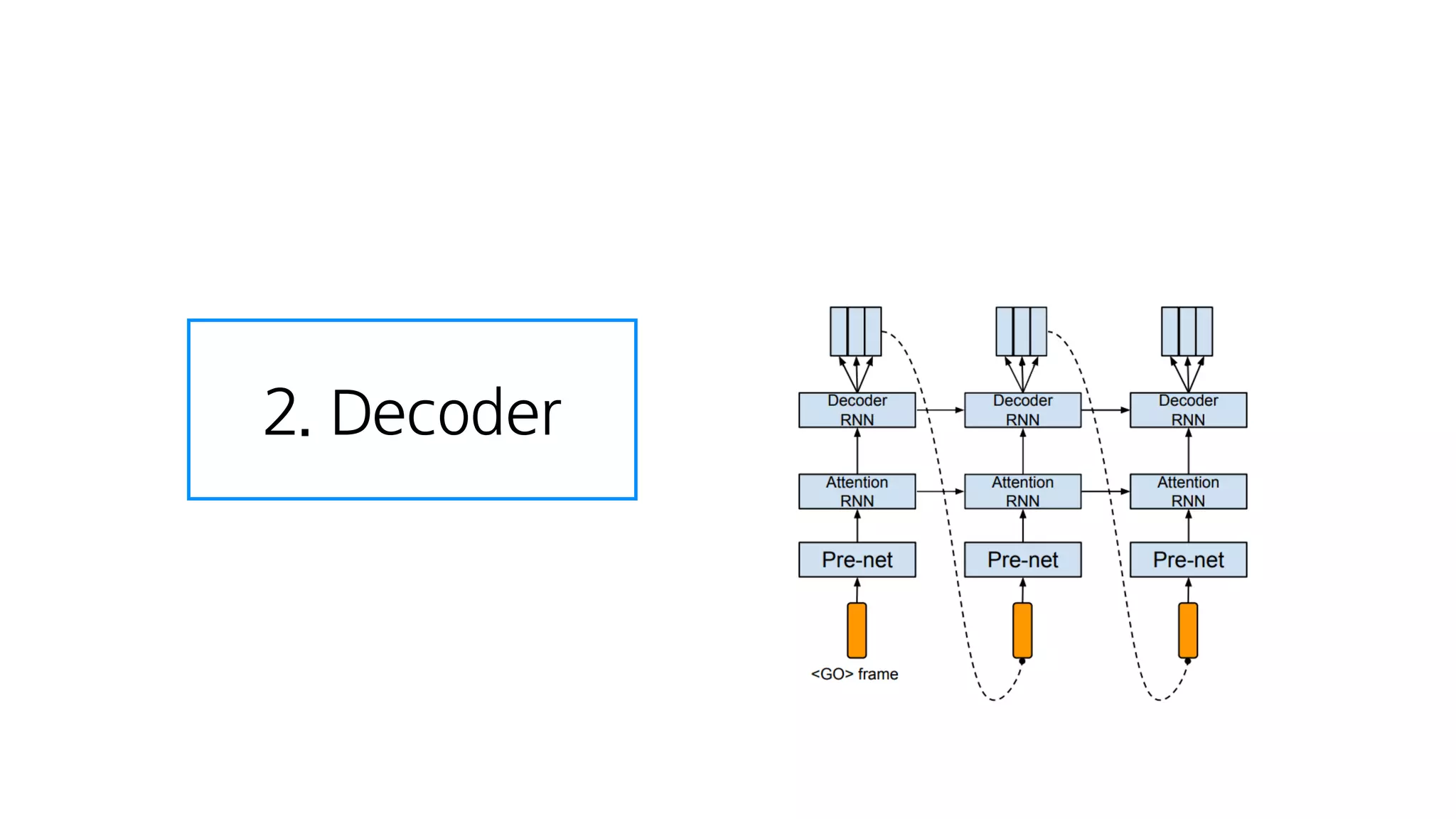
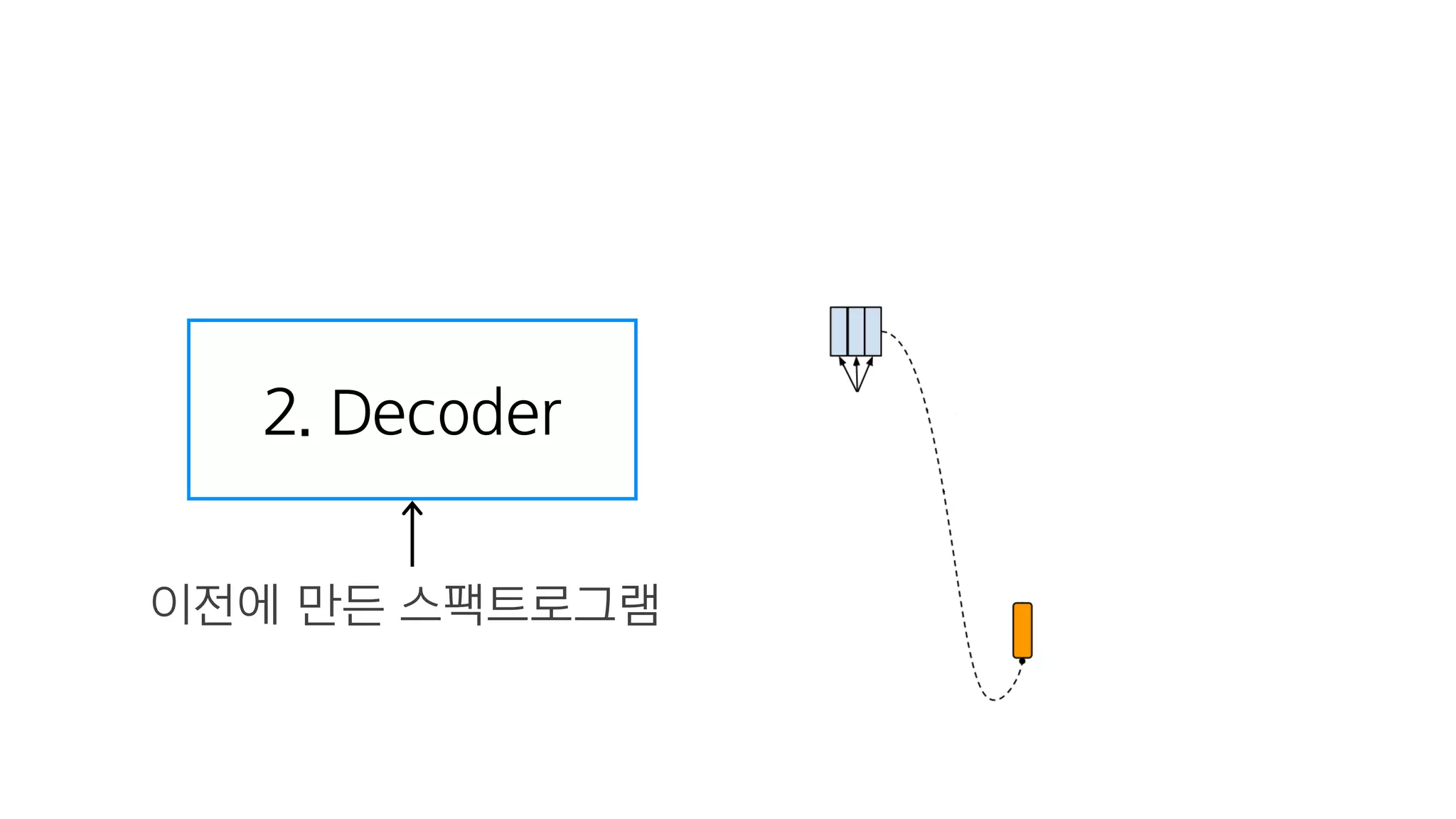
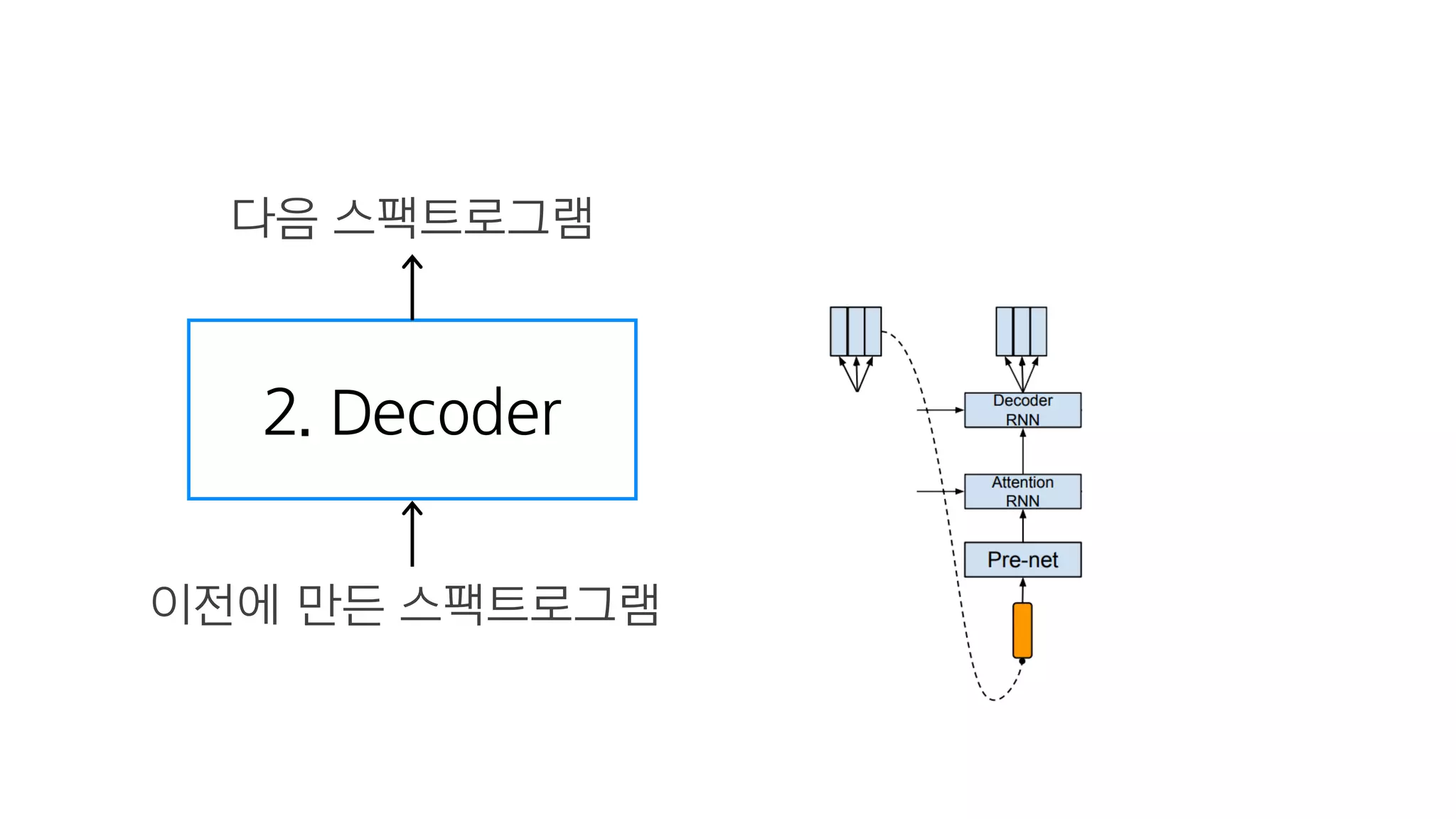
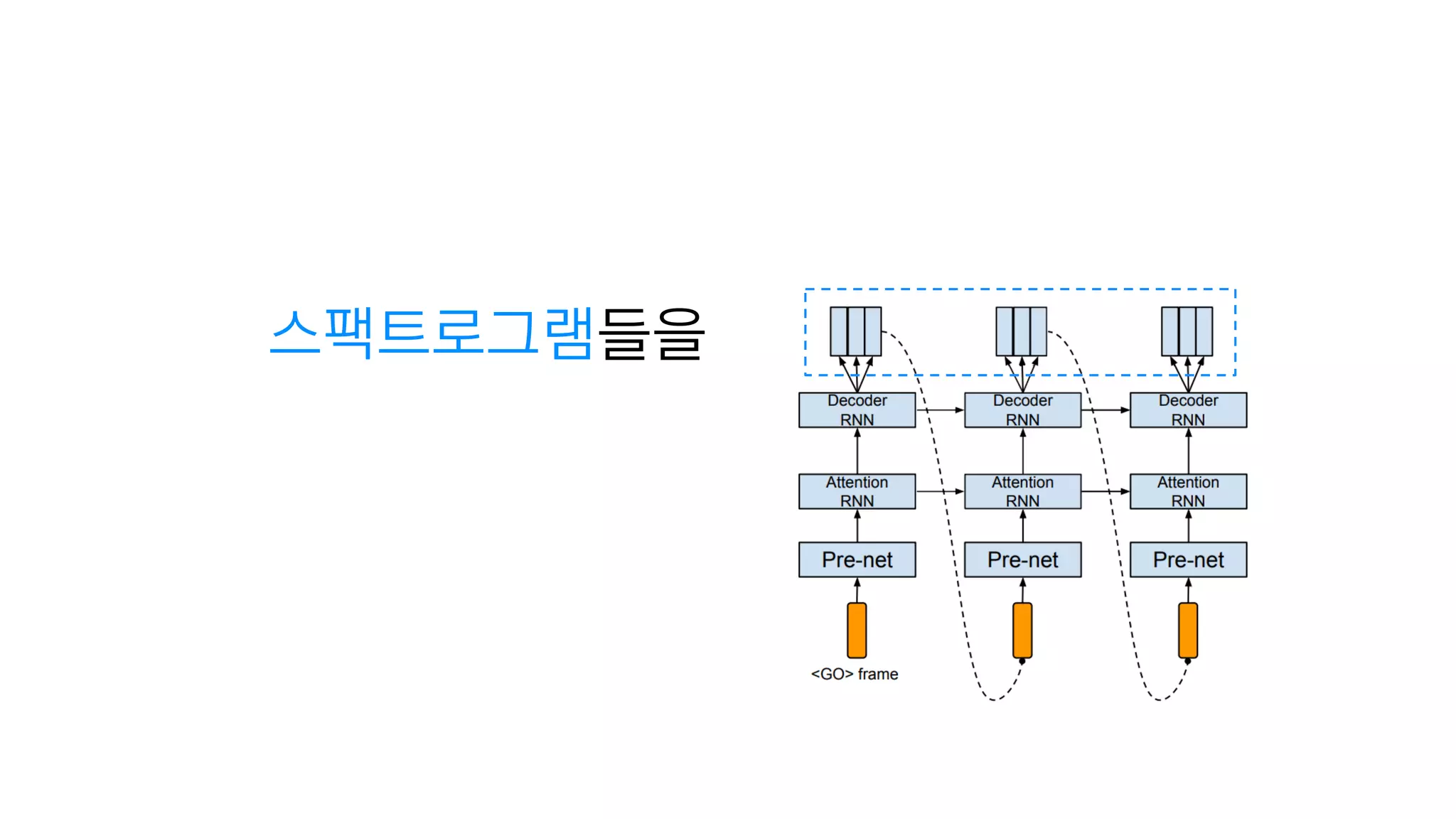
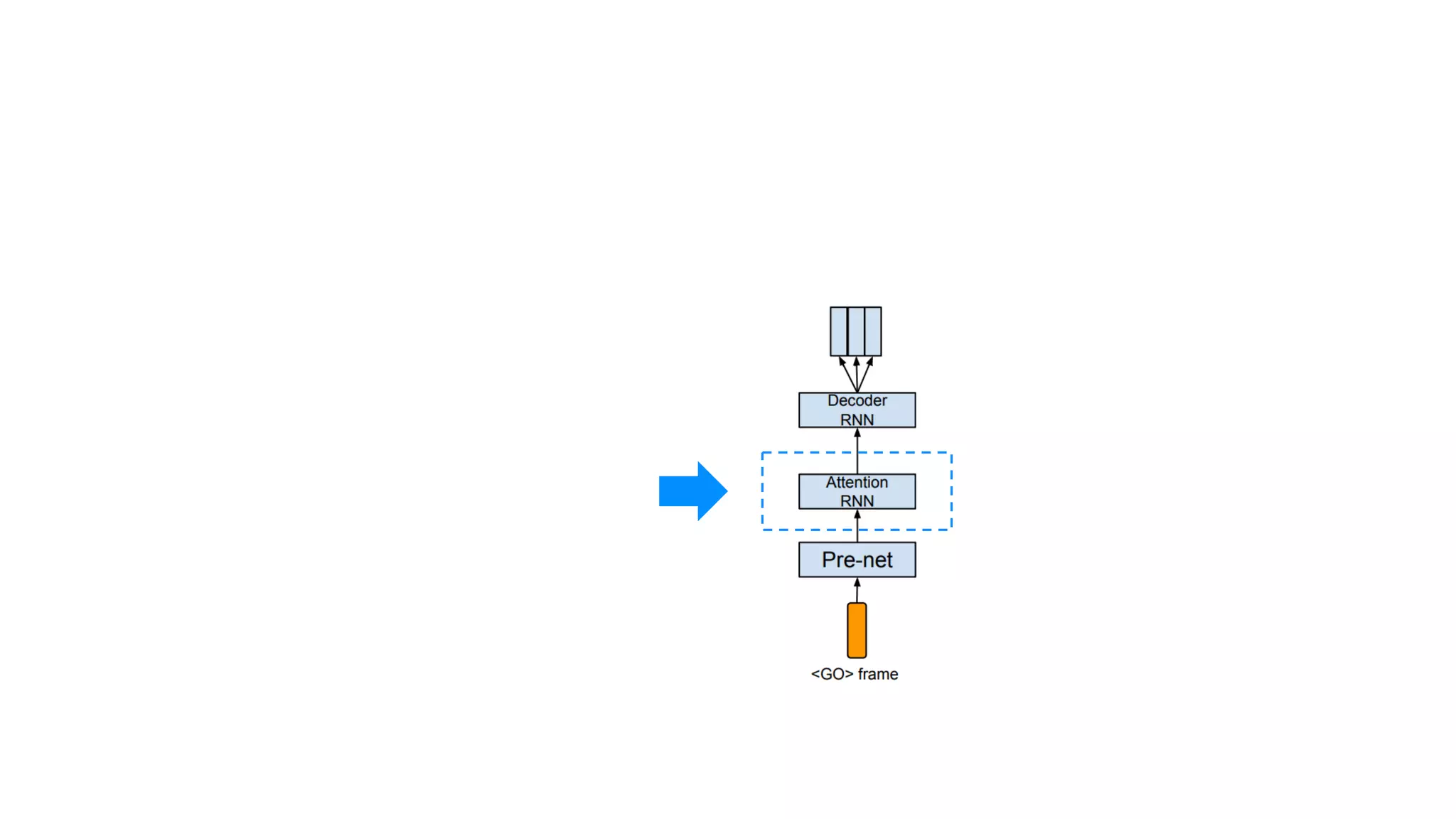
- 86. 텍스트 임베딩 : 텍스트를 잘 나타내는 숫자
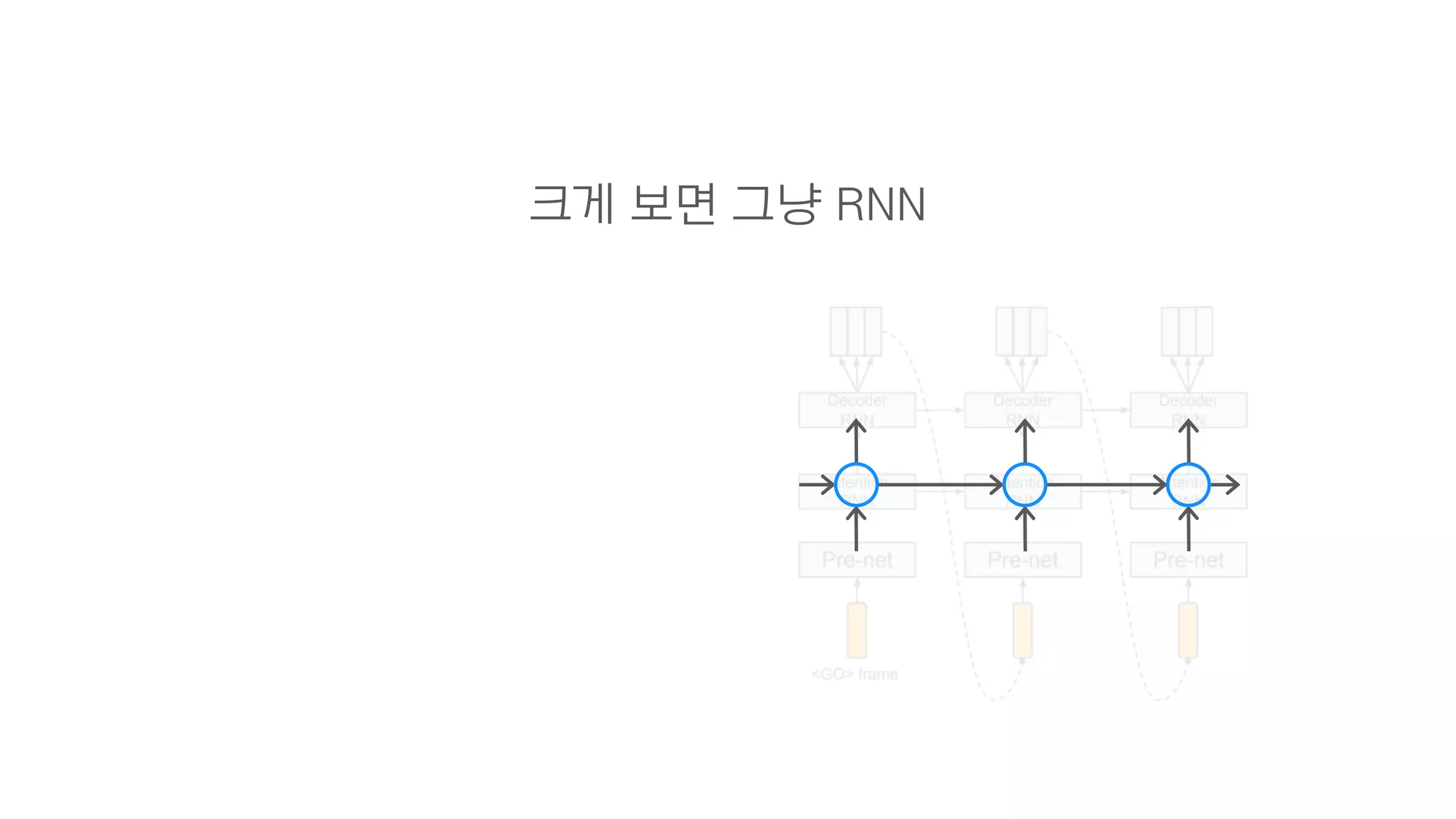
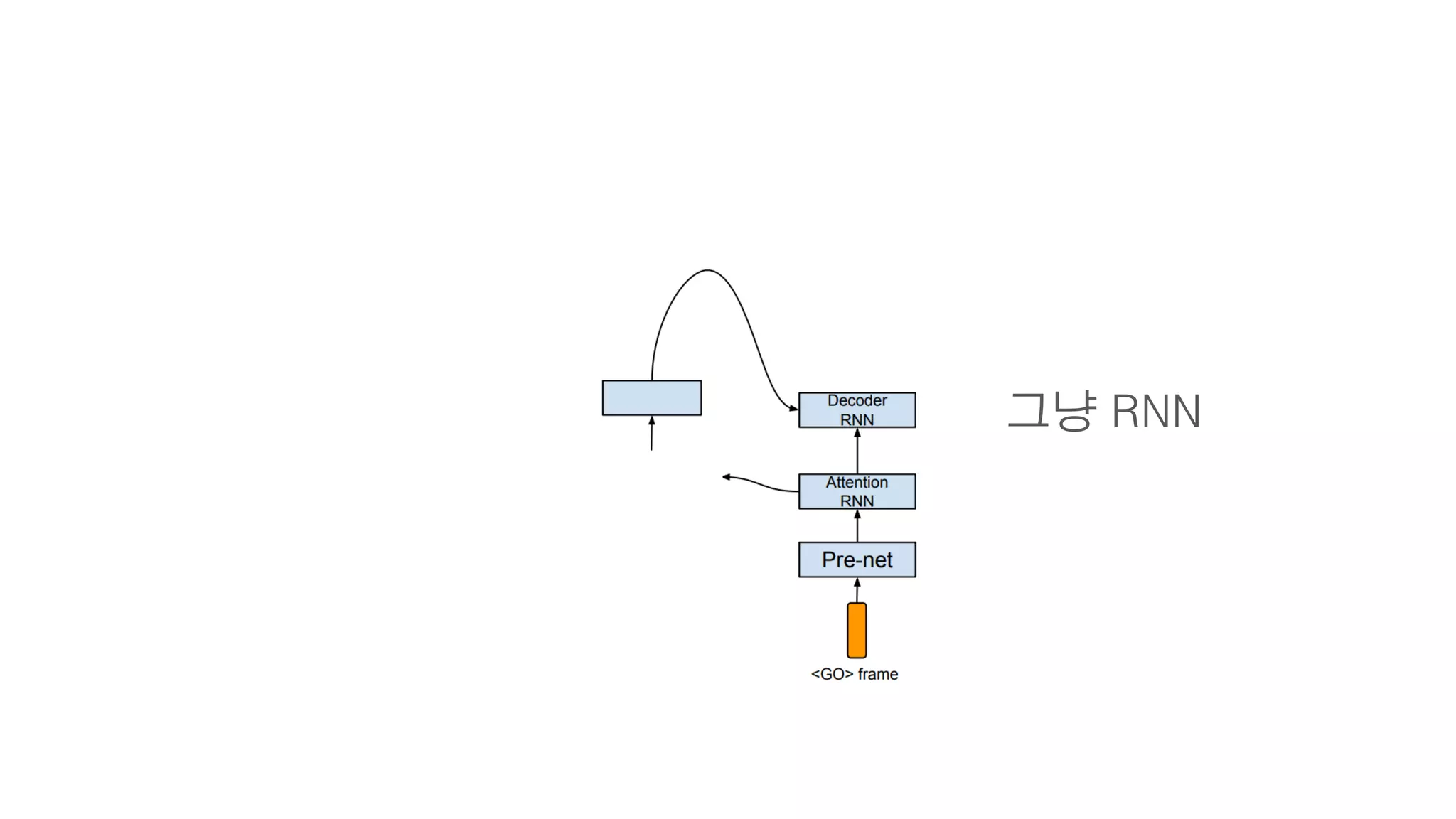
- 87. 2. Decoder
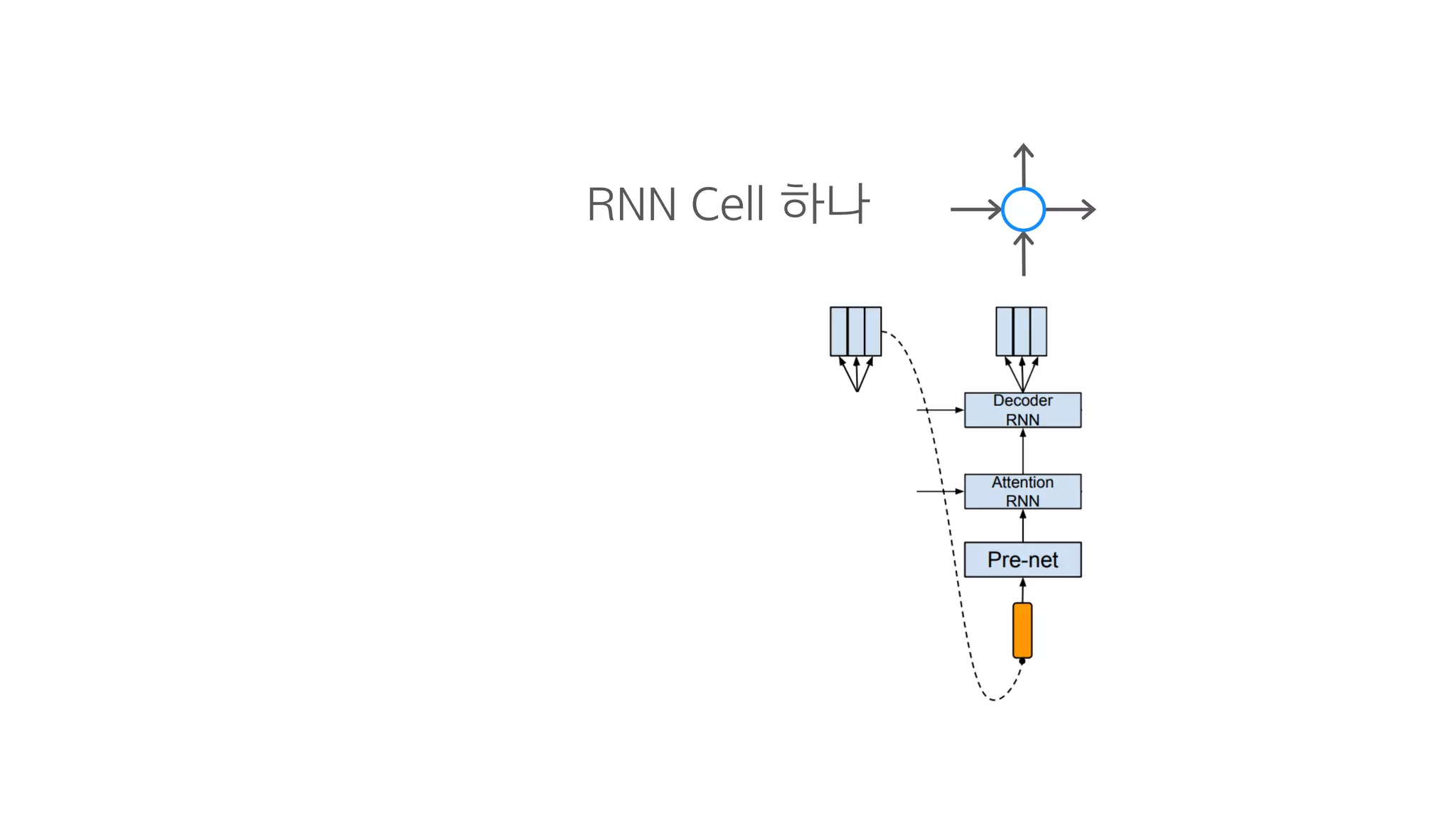
- 88. 크게 보면 그냥 RNN
- 89. RNN Cell 하나
- 90. 2. Decoder 이전에 만든 스팩트로그램
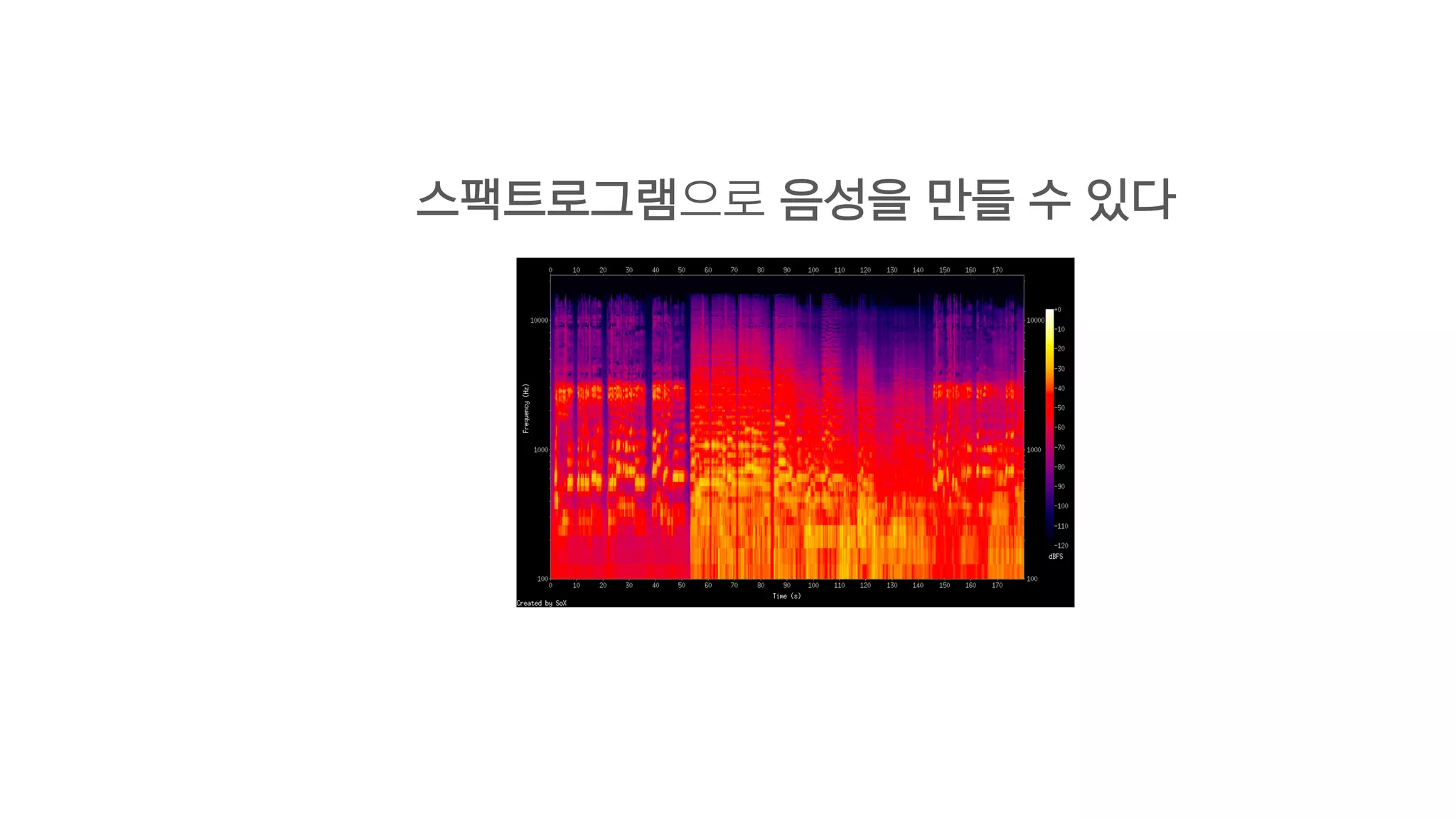
- 91. 2. Decoder 이전에 만든 스팩트로그램 다음 스팩트로그램
- 92. 스팩트로그램으로 음성을 만들 수 있다
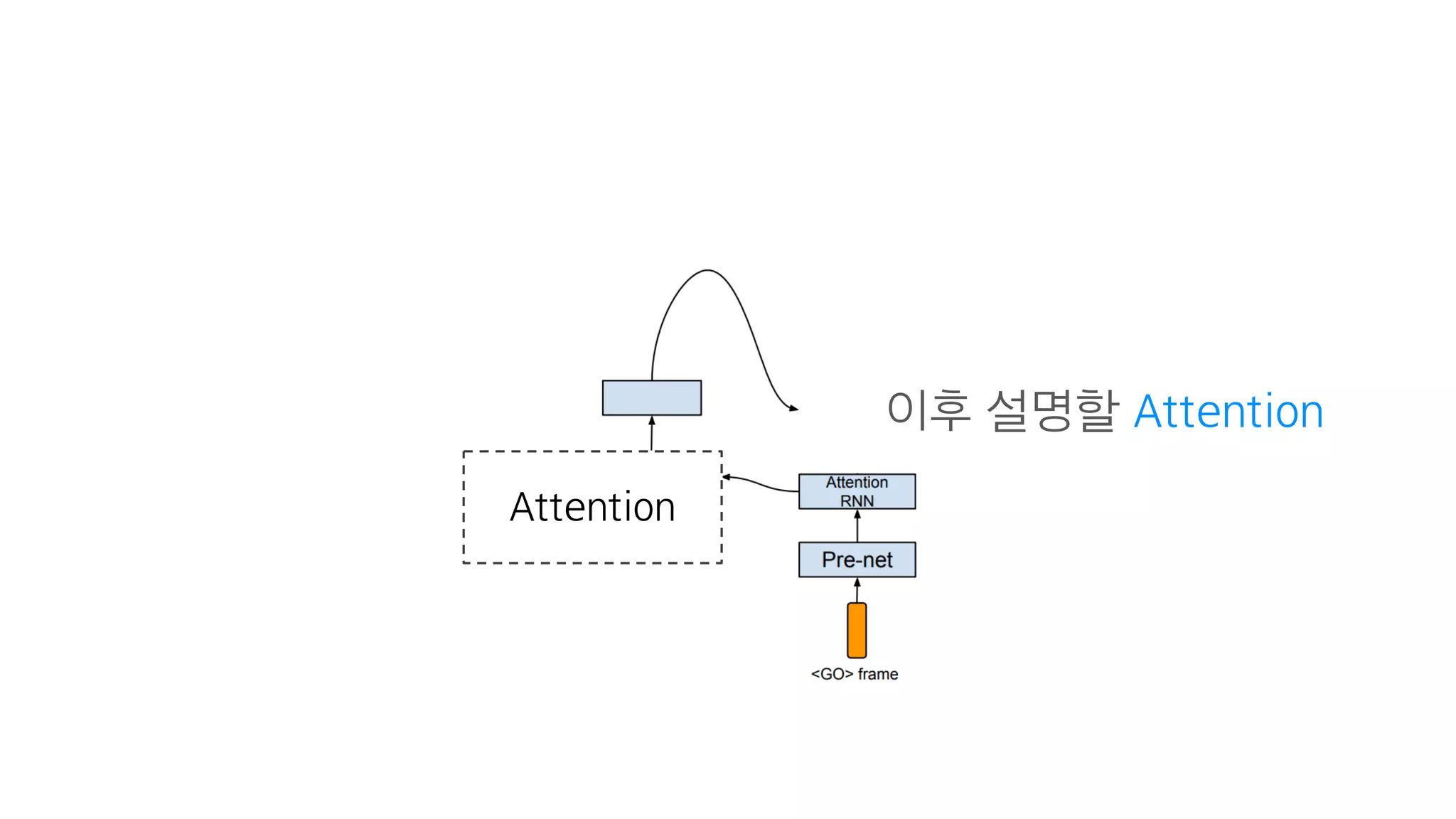
- 93. 문장에 상관없이 항상 같은 값
- 94. 이후 설명할 Attention Attention
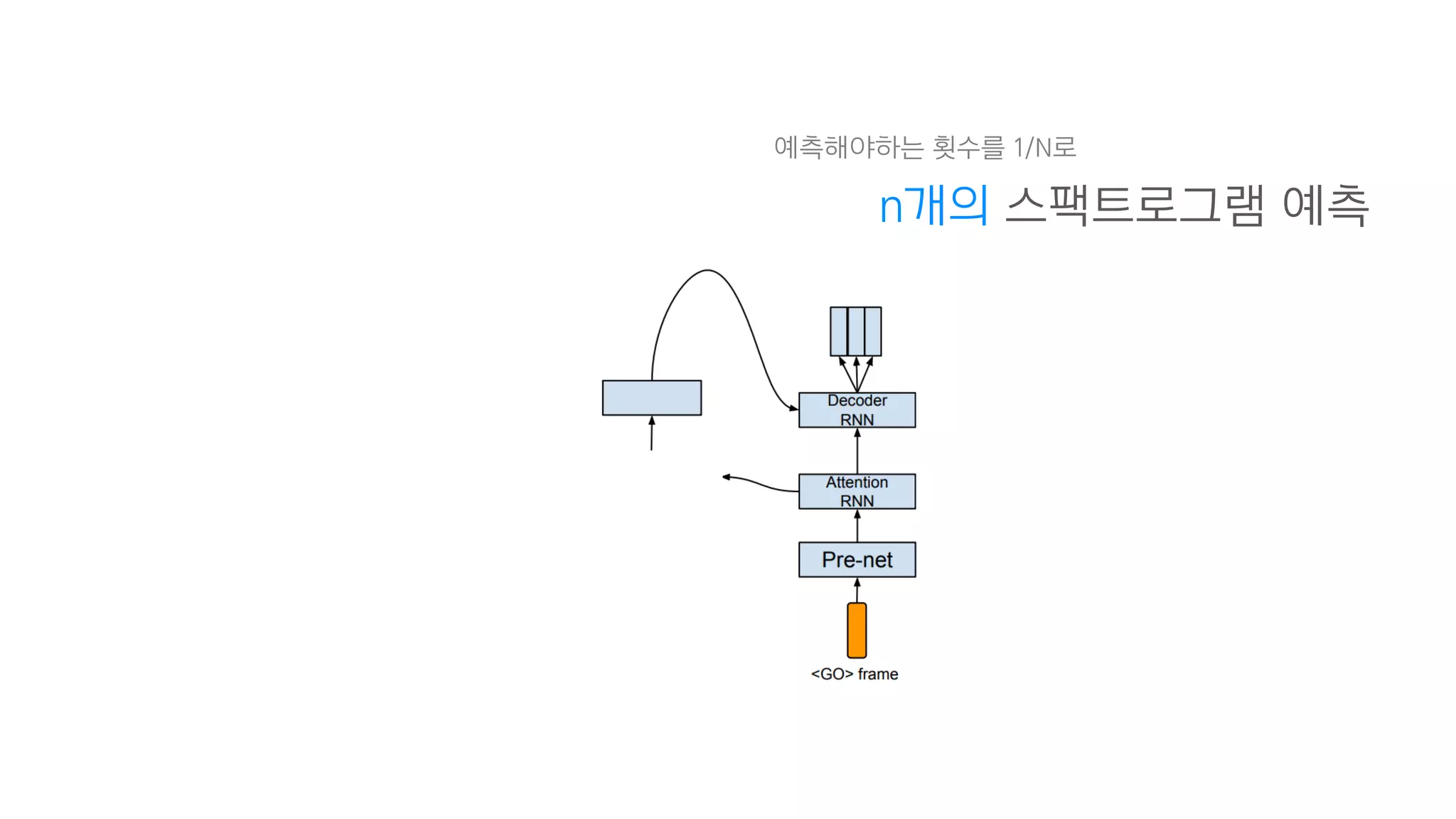
- 95. 그냥 RNN
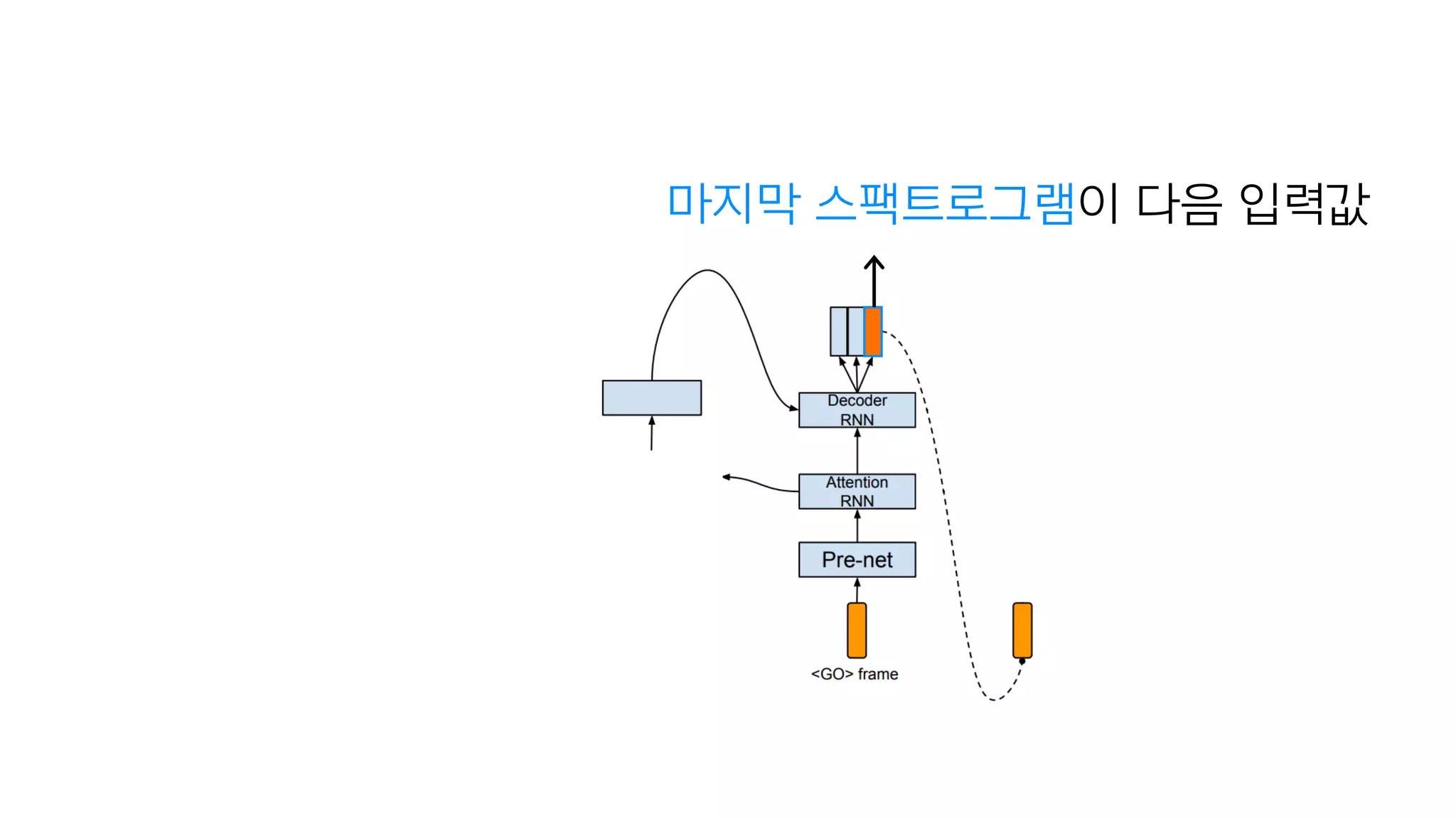
- 96. n개의 스팩트로그램 예측 예측해야하는 횟수를 1/N로
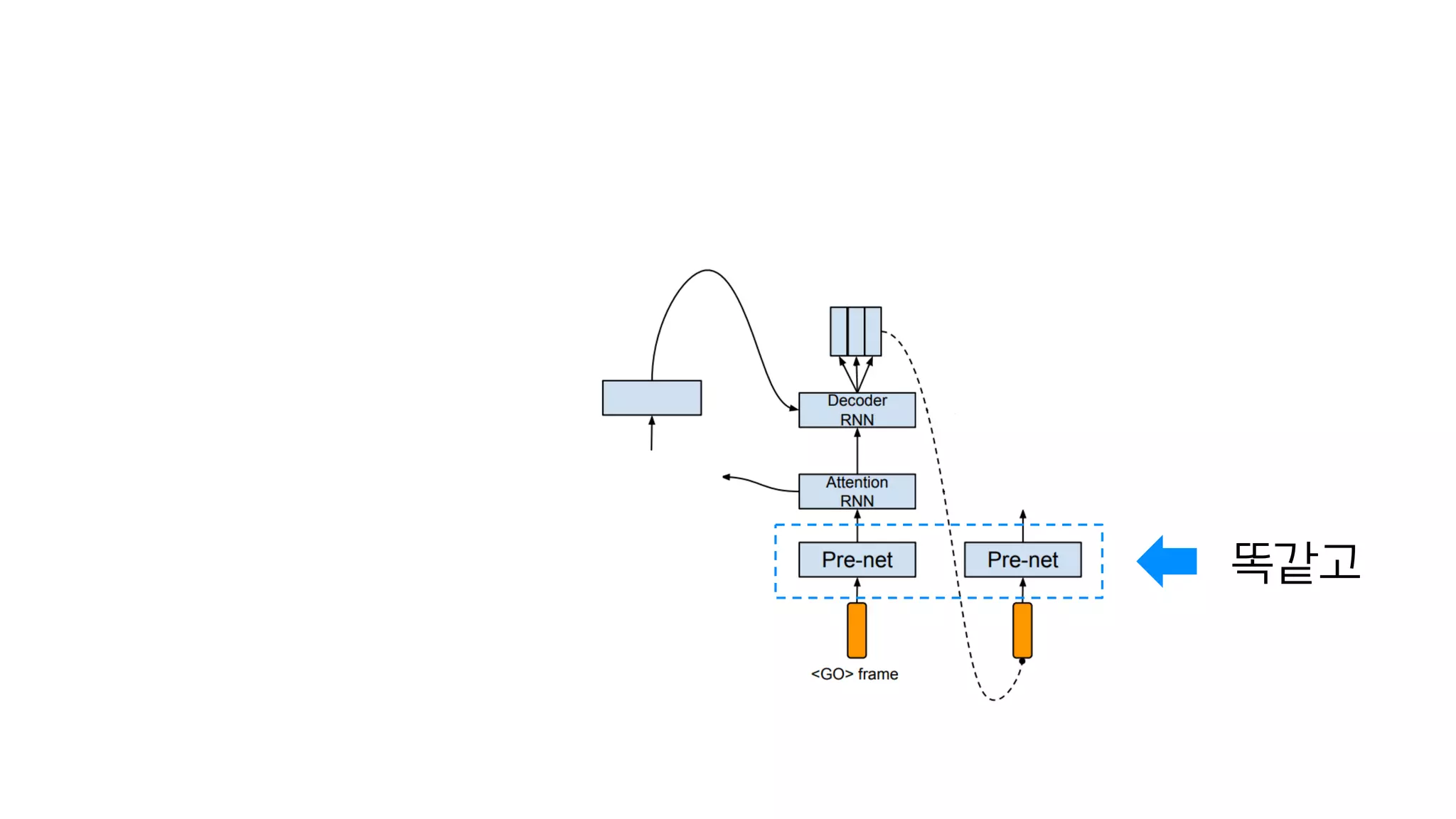
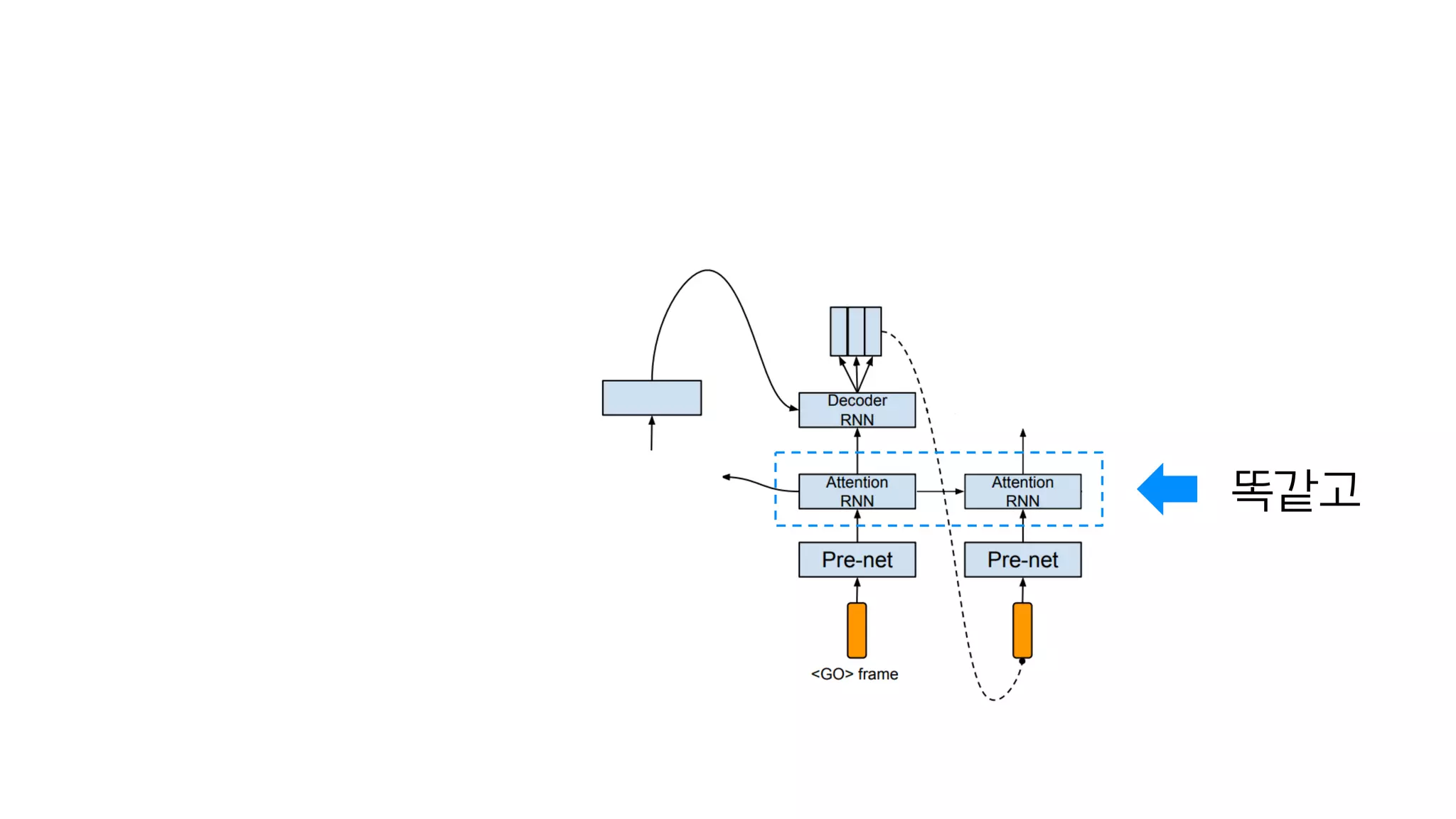
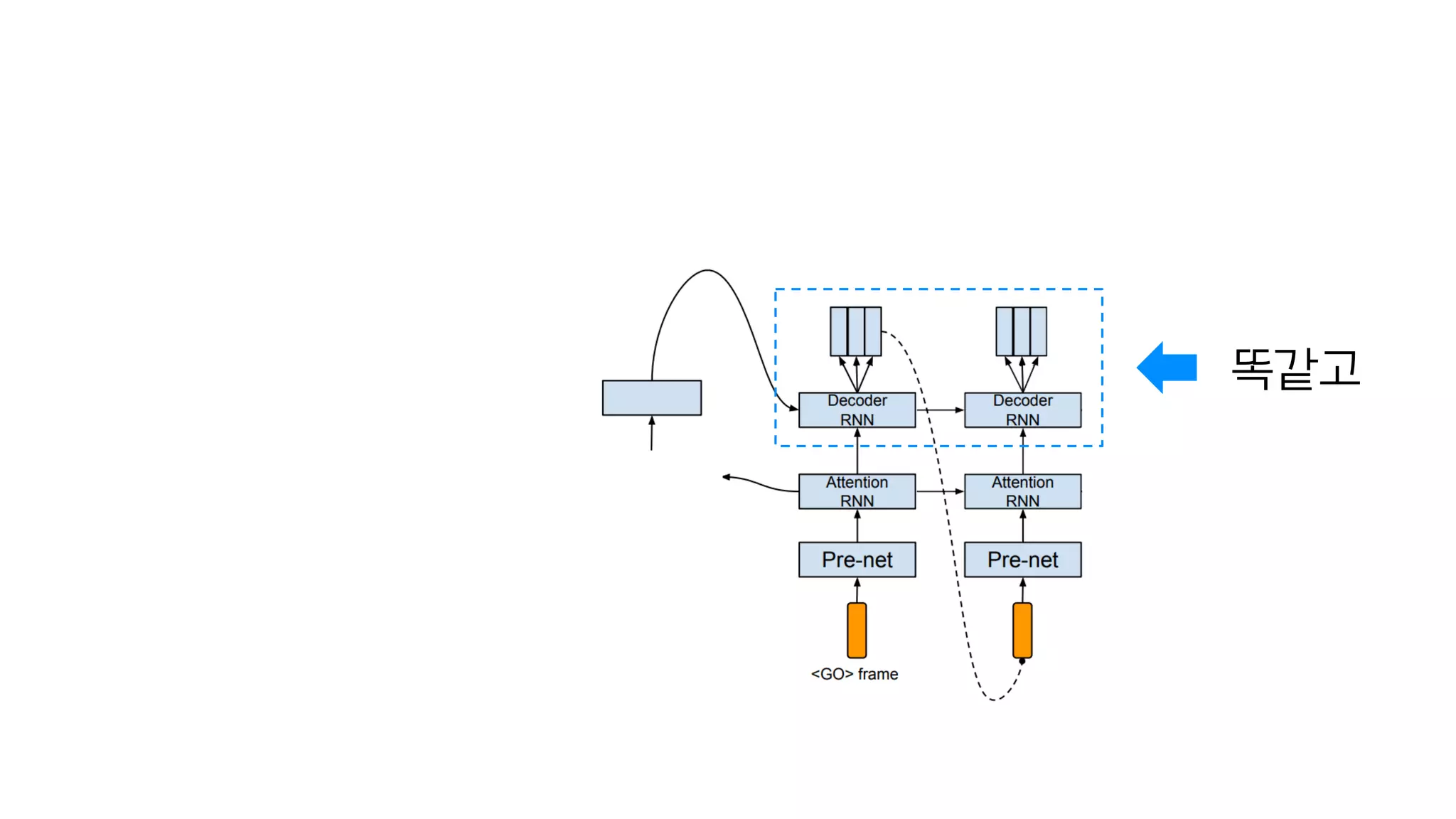
- 97. 마지막 스팩트로그램이 다음 입력값
- 98. 똑같고
- 99. 똑같고
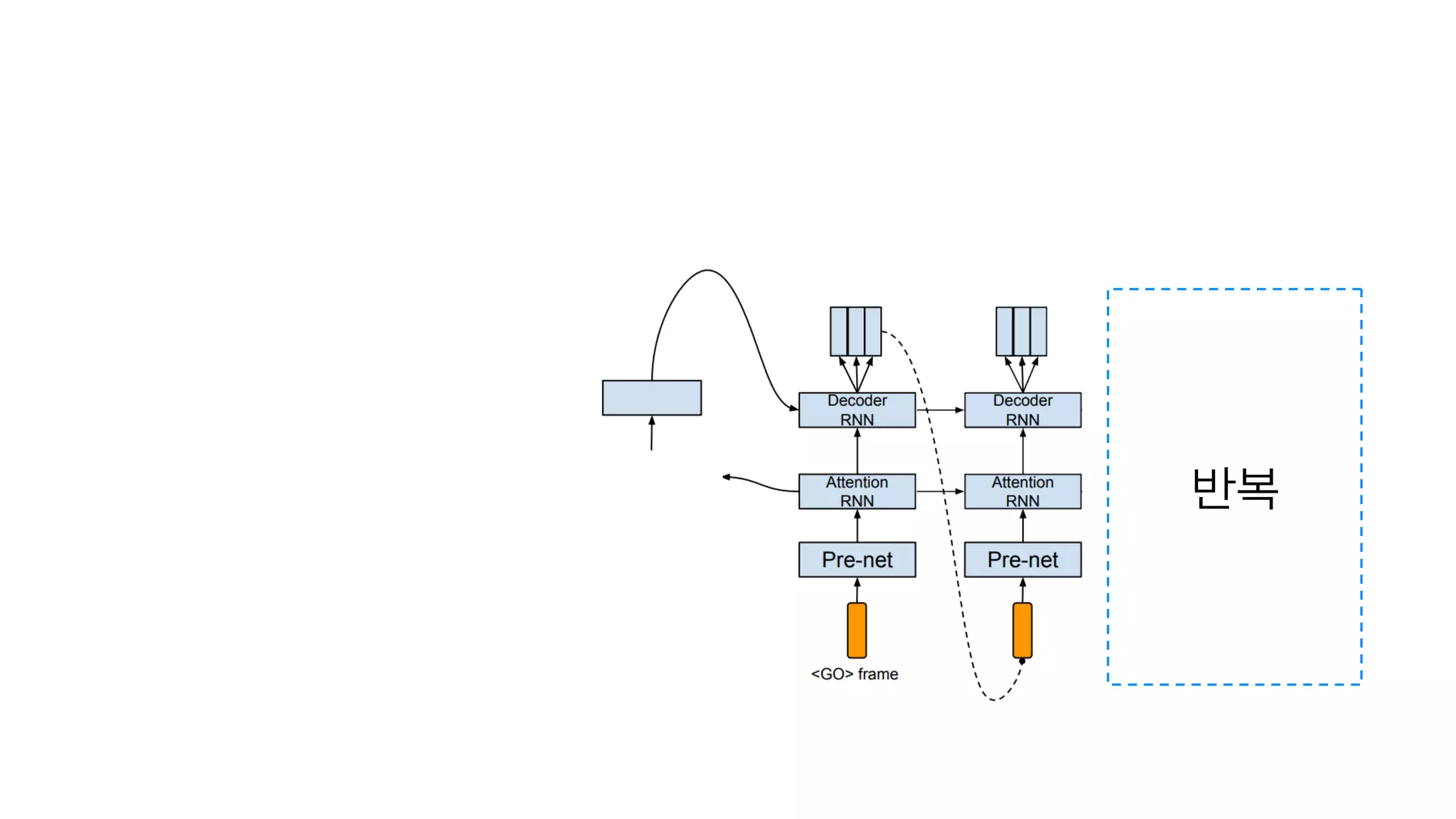
- 100. 똑같고
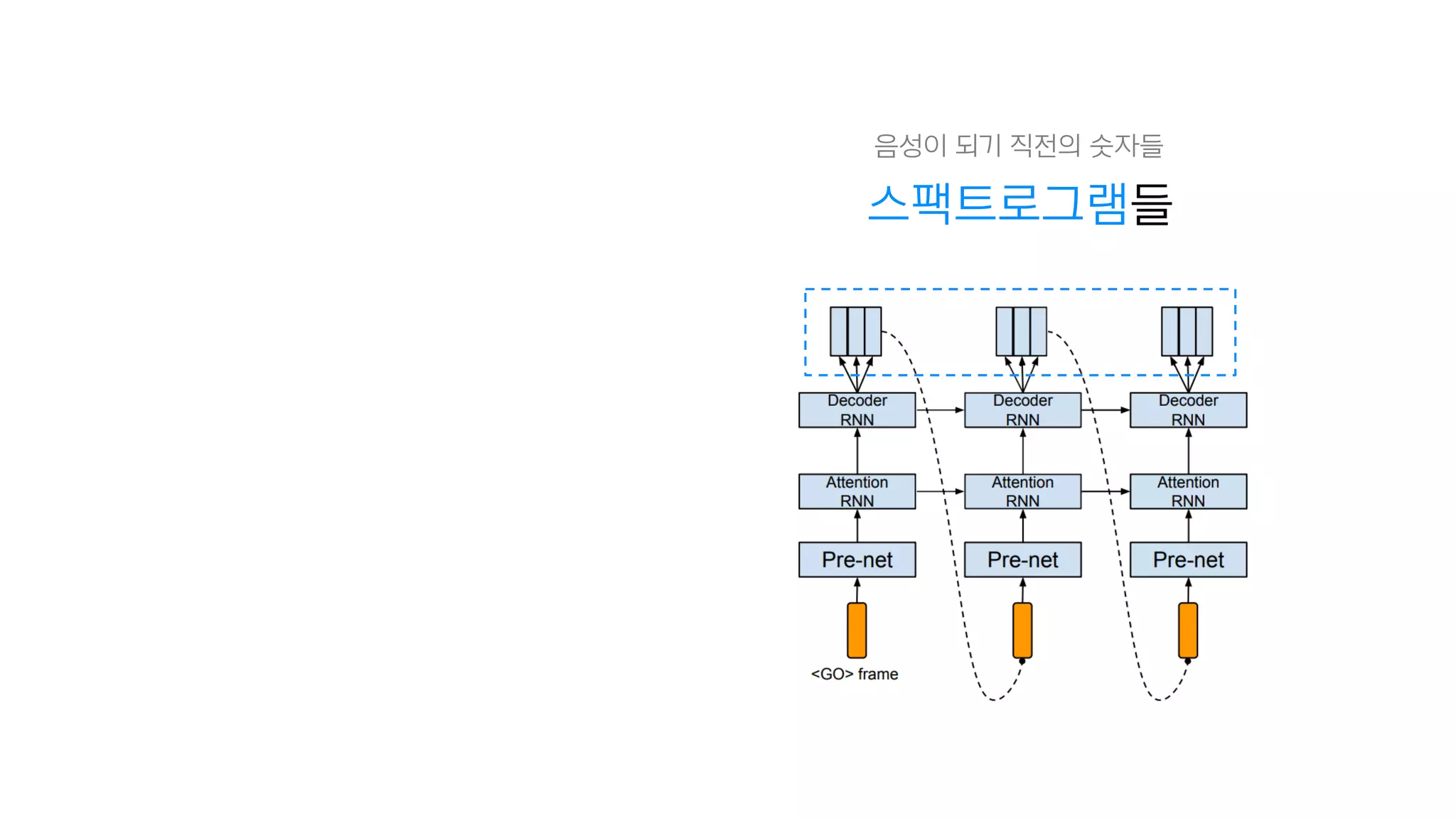
- 101. 반복
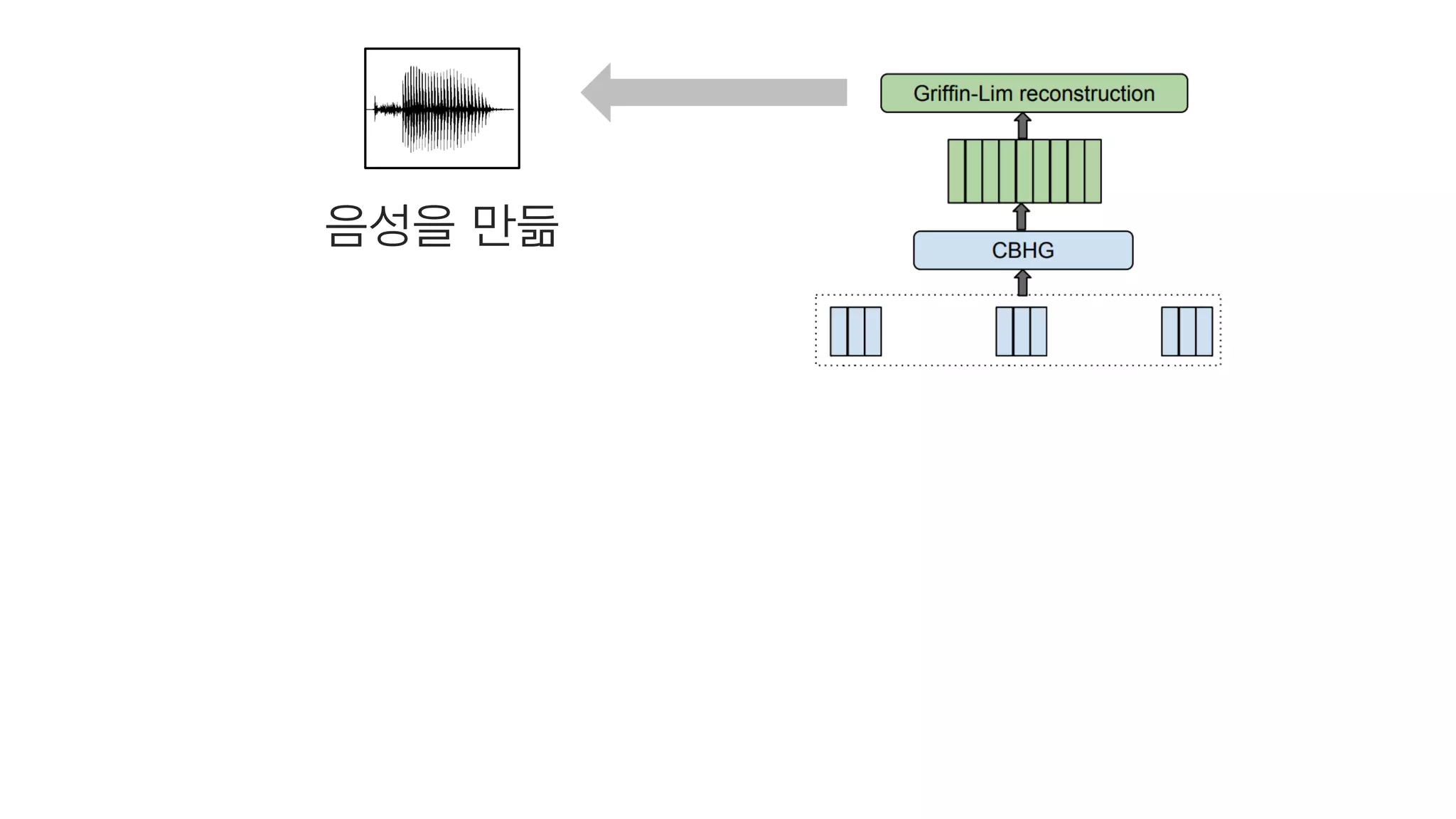
- 102. 스팩트로그램들 음성이 되기 직전의 숫자들
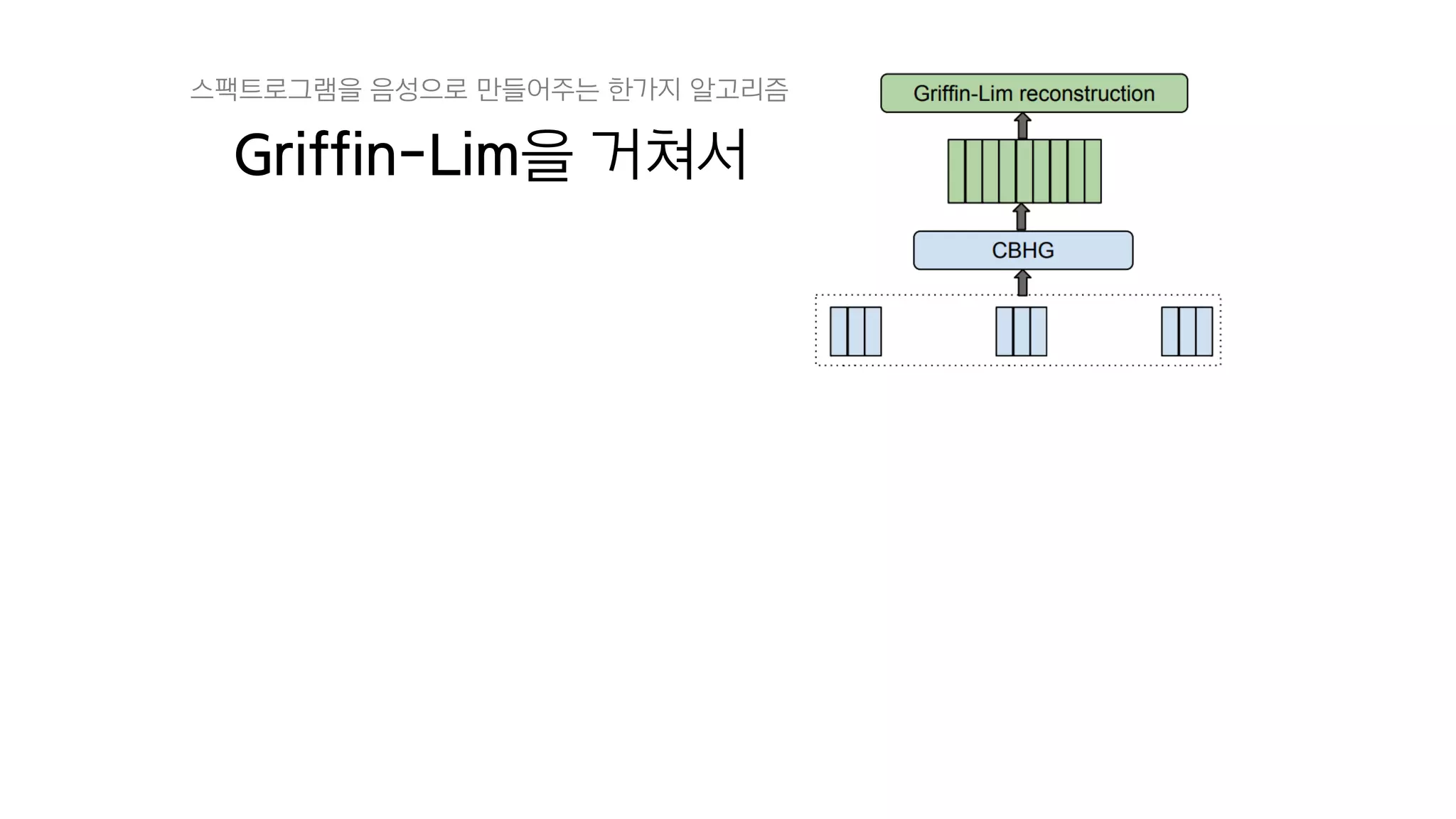
- 103. 4. Vocoder
- 104. 스팩트로그램들을
- 105. CBHG를 거치고
- 106. Griffin-Lim을 거쳐서 스팩트로그램을 음성으로 만들어주는 한가지 알고리즘
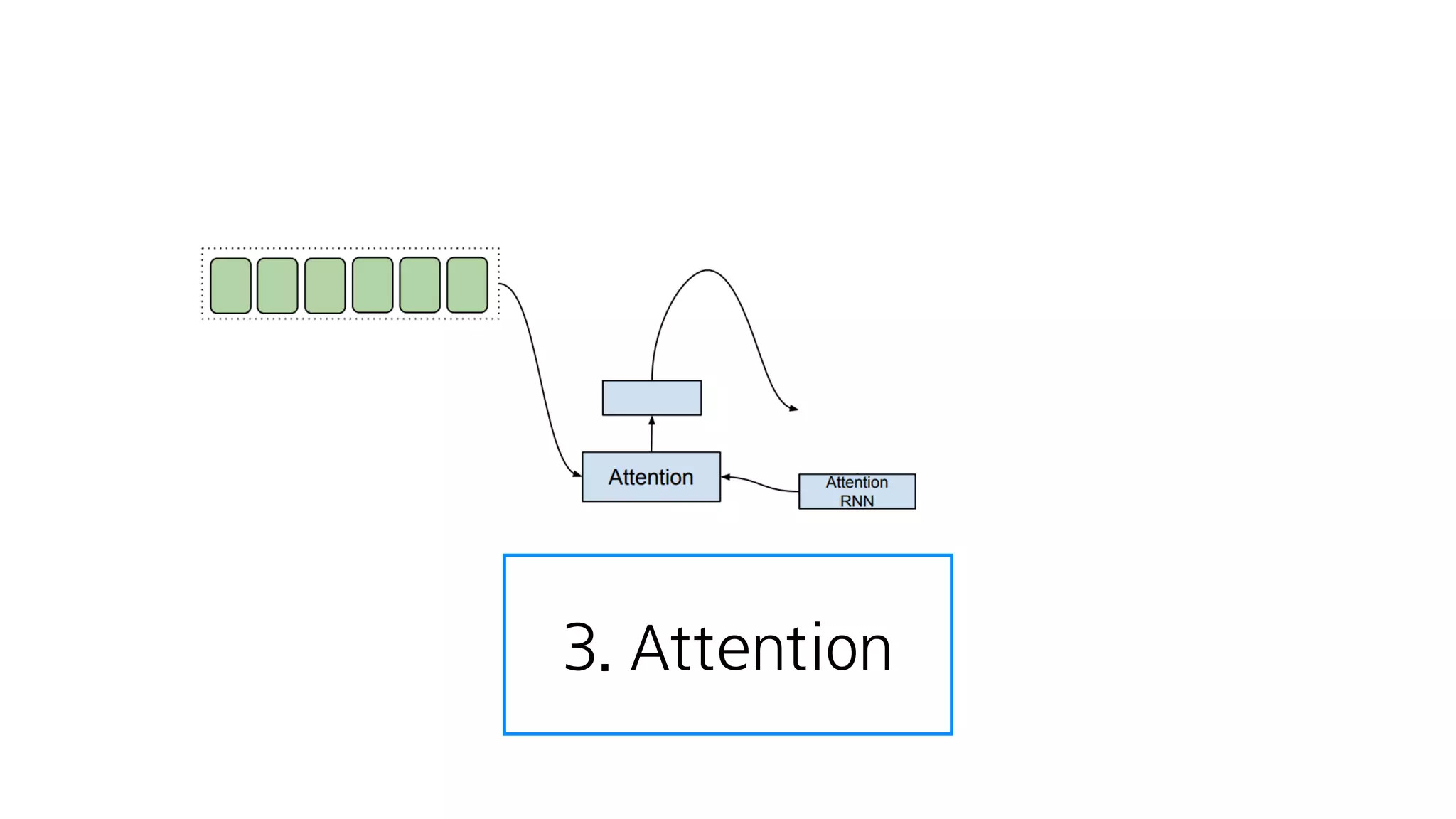
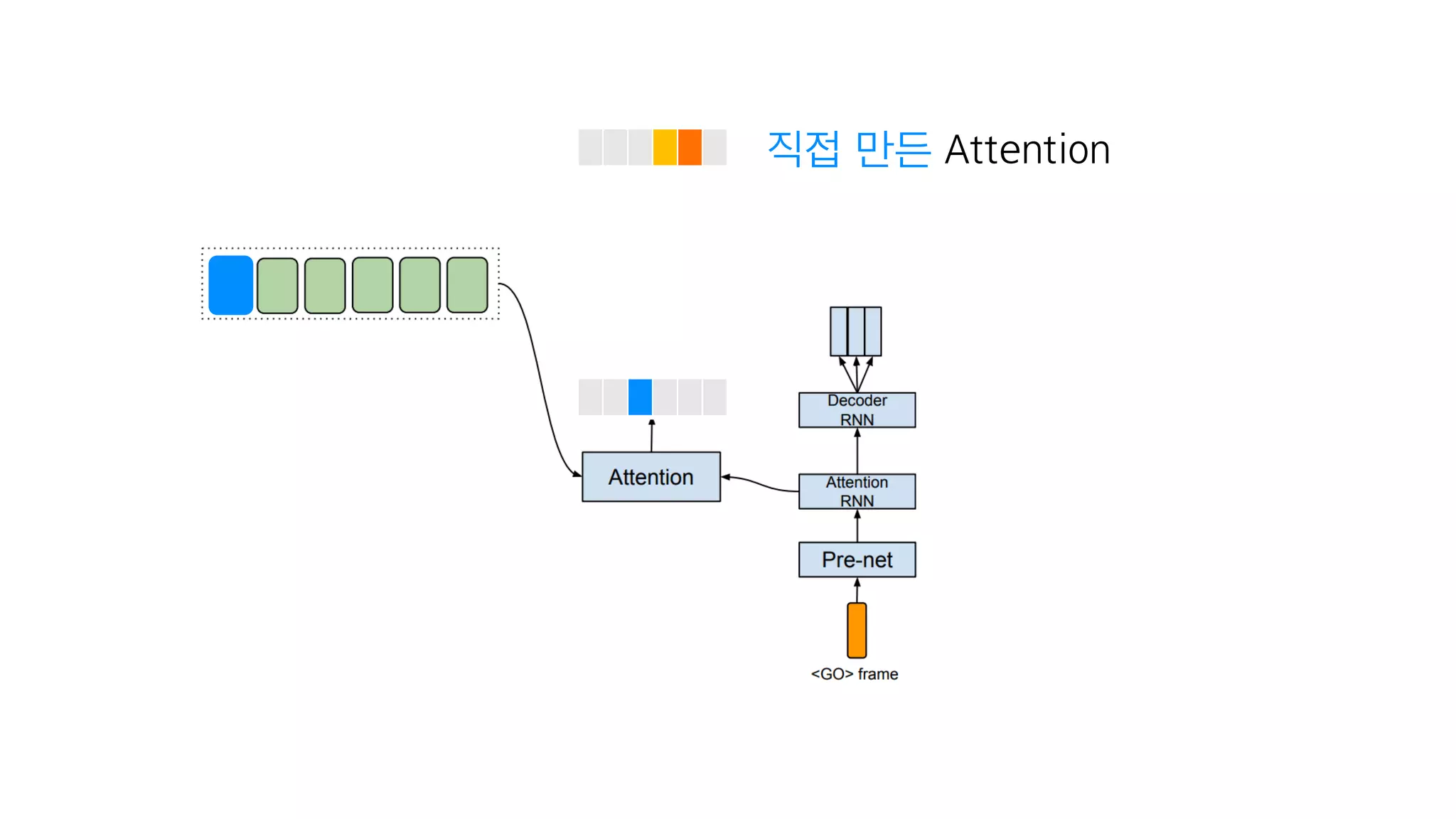
- 107. 음성을 만듦
- 108. 3. Attention
- 109. Attention은 Tacotron에서 가장 중요
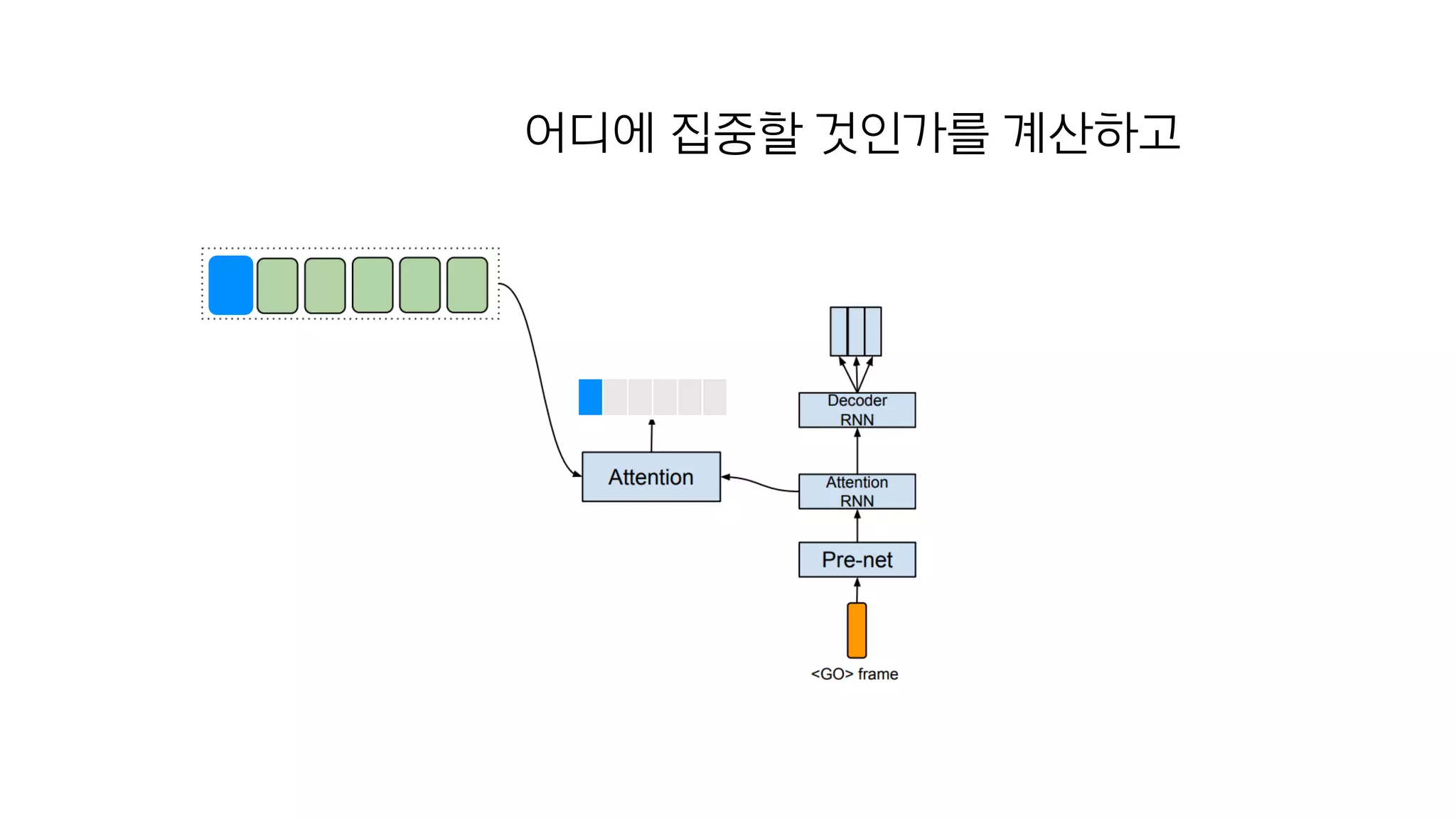
- 110. Attention
- 111. 어디에 집중할 것인가? Attention
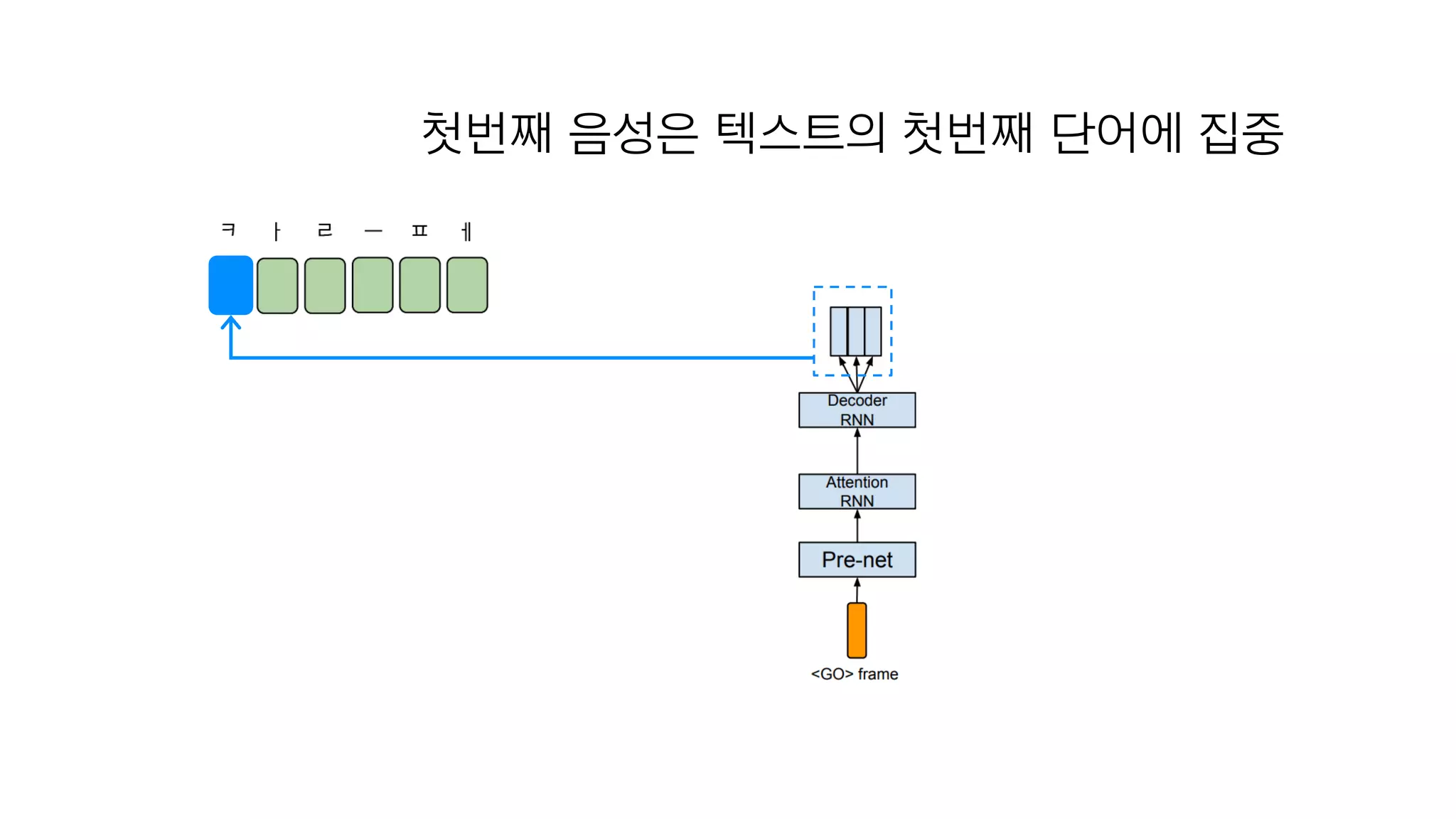
- 112. 텍스트 임베딩 : 텍스트를 잘 나타내는 숫자
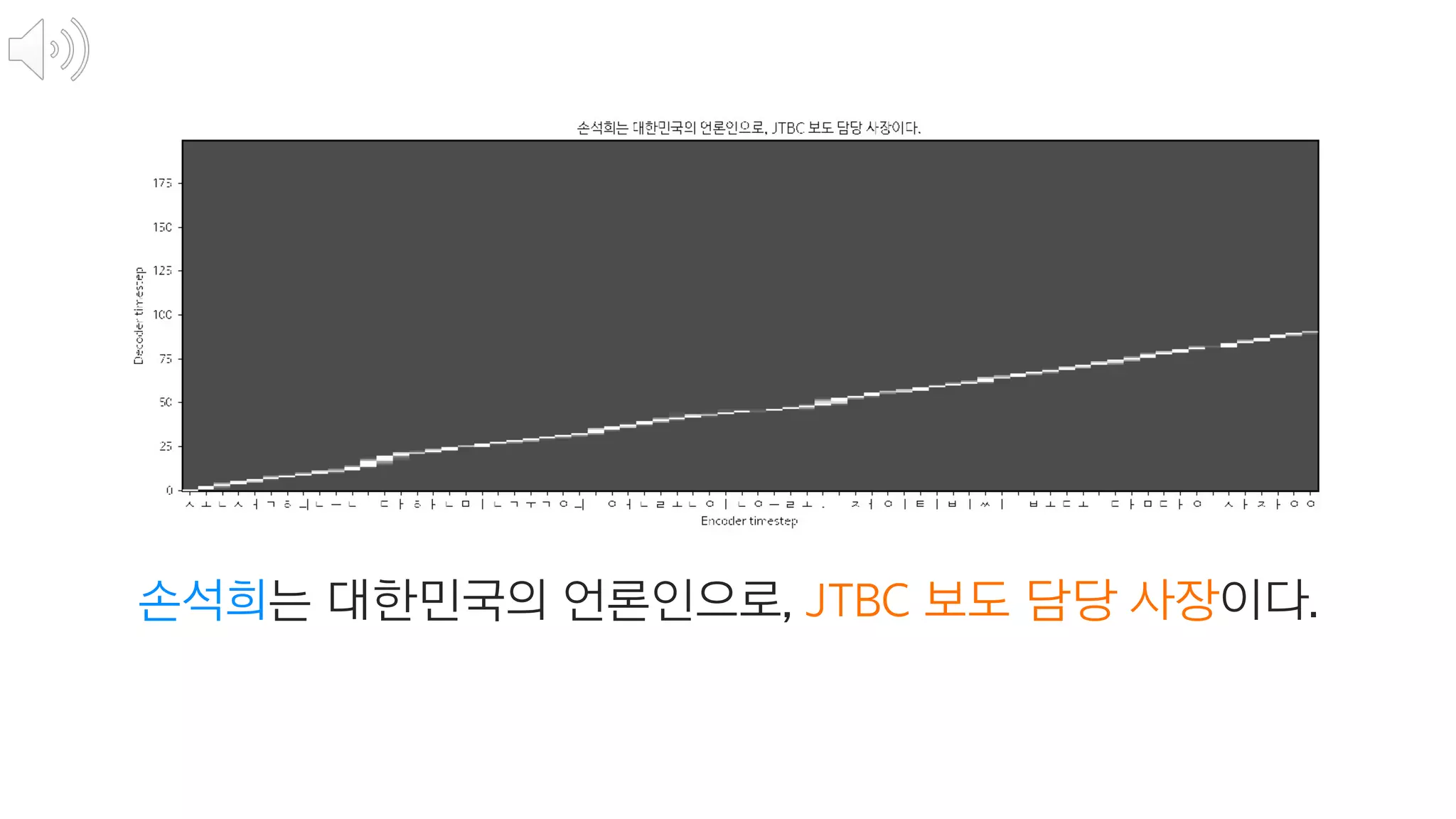
- 113. Encoder 텍스트 임베딩
- 114. 첫번째 음성은 텍스트의 첫번째 단어에 집중
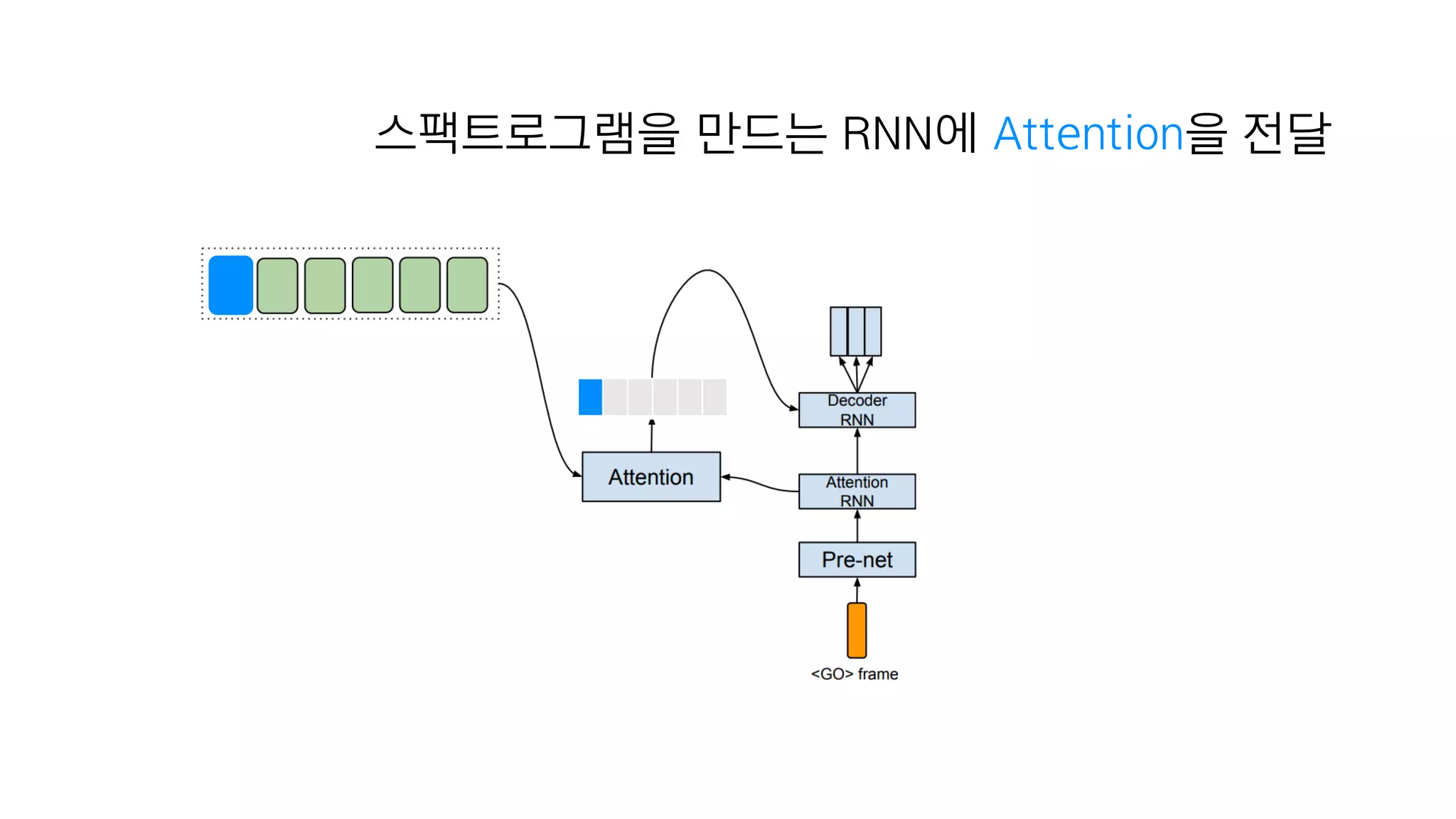
- 115. 어디에 집중할 것인가를 계산하고
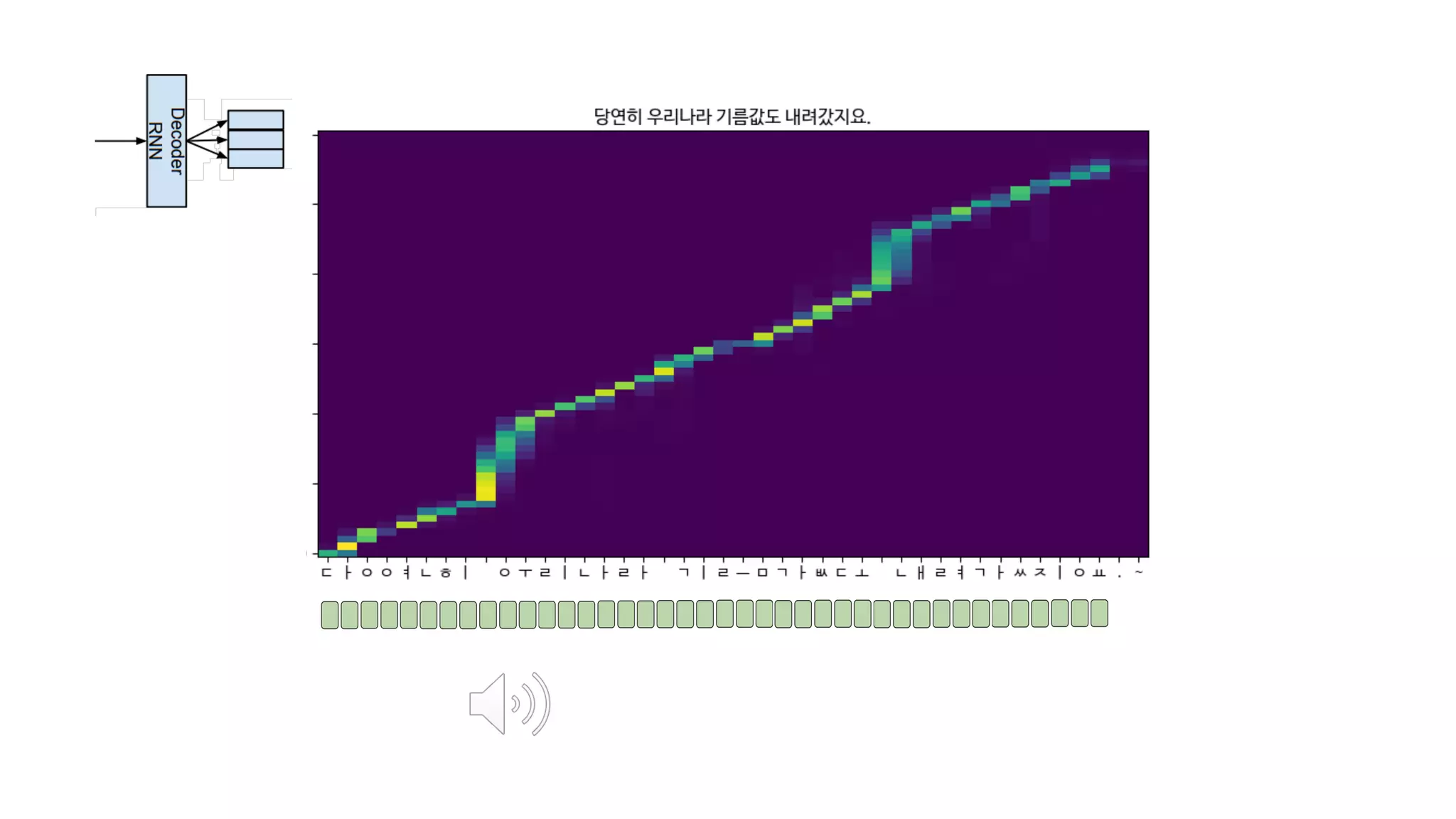
- 116. 스팩트로그램을 만드는 RNN에 Attention을 전달
- 117. 예시를 한번 보죠
- 118. <Go> 첫번째 입력값 텍스트 임베딩
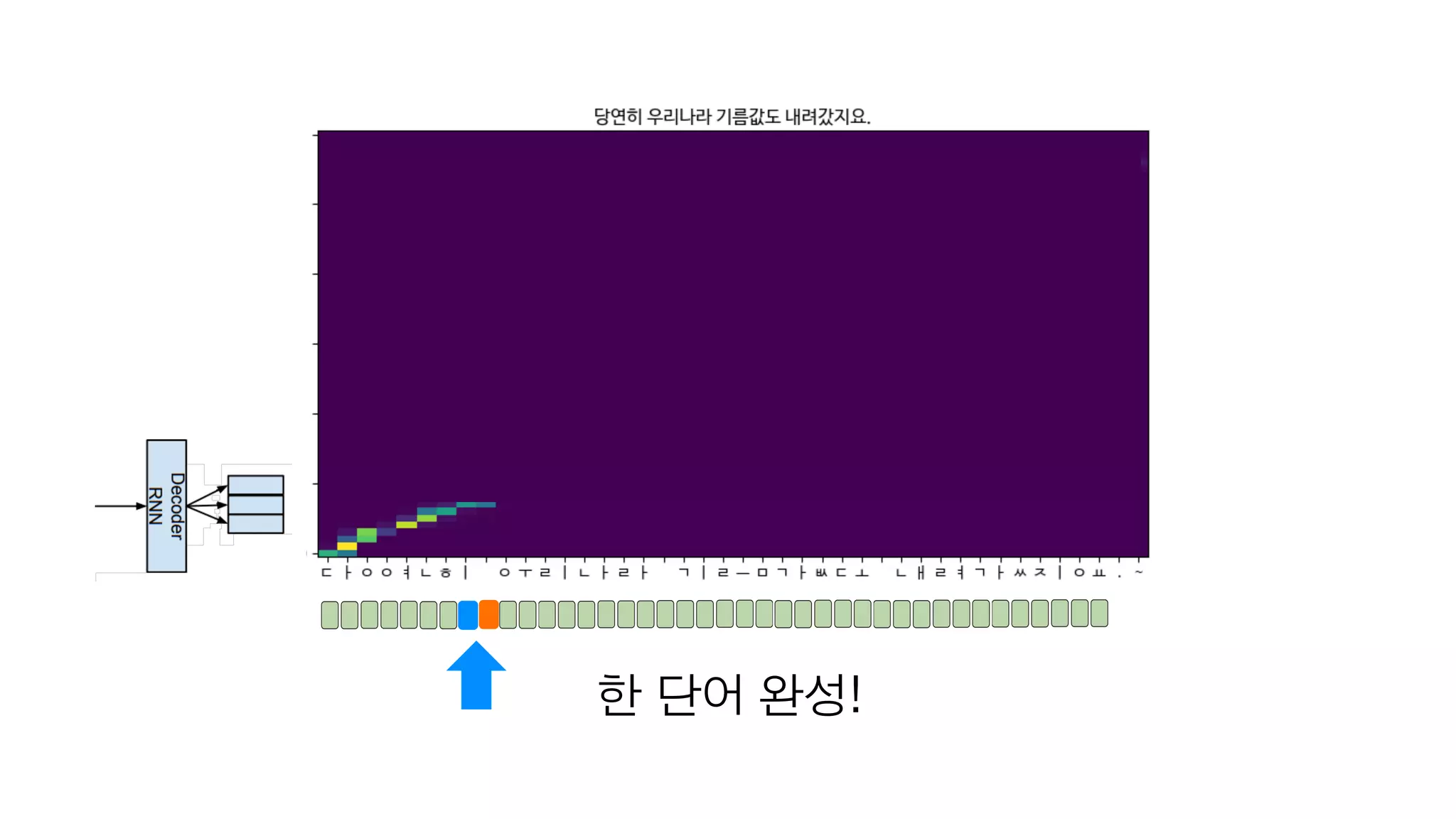
- 119. <Go> 가장 첫번째 단어에 집중
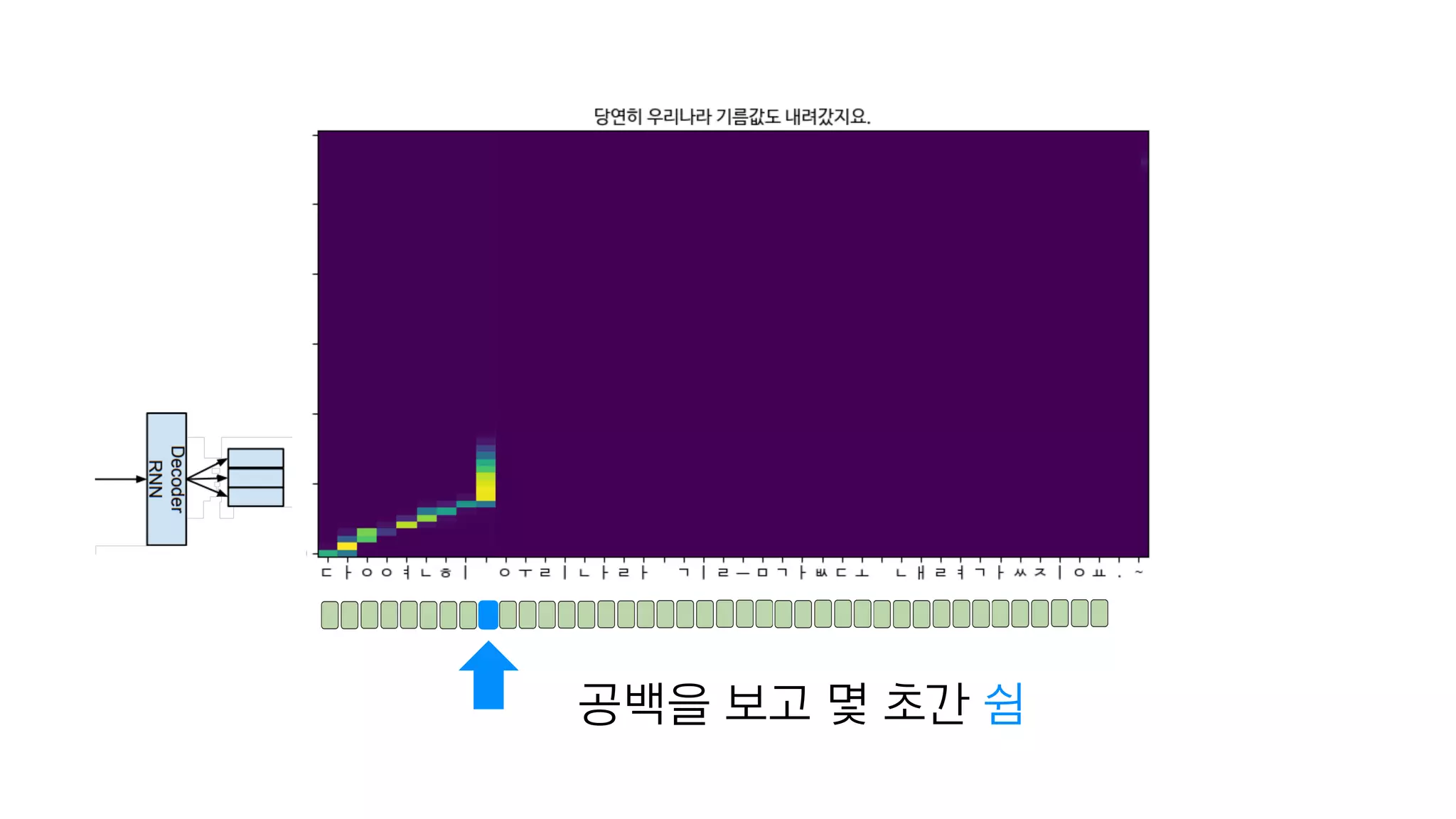
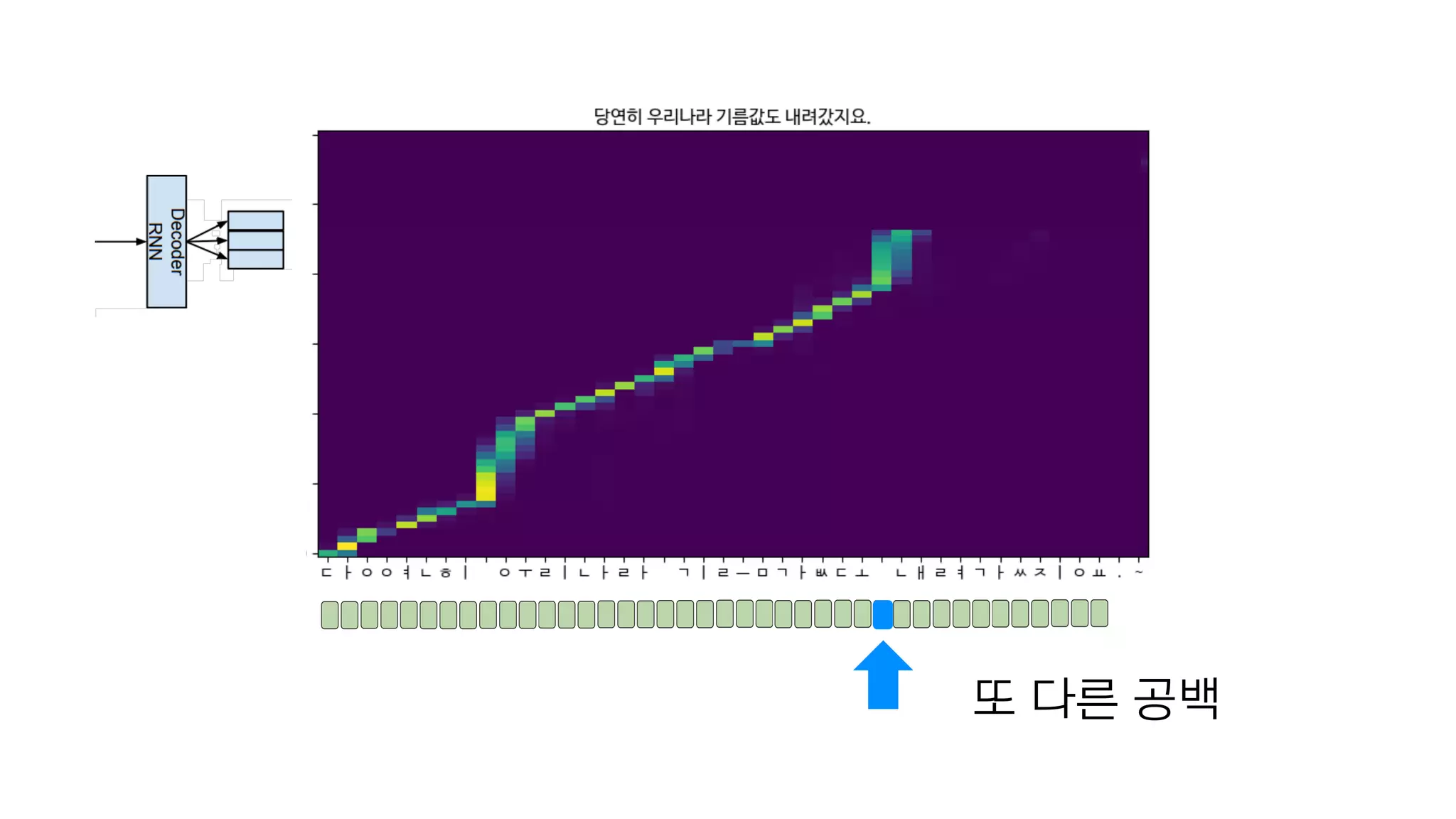
- 120. 한 단어 완성!
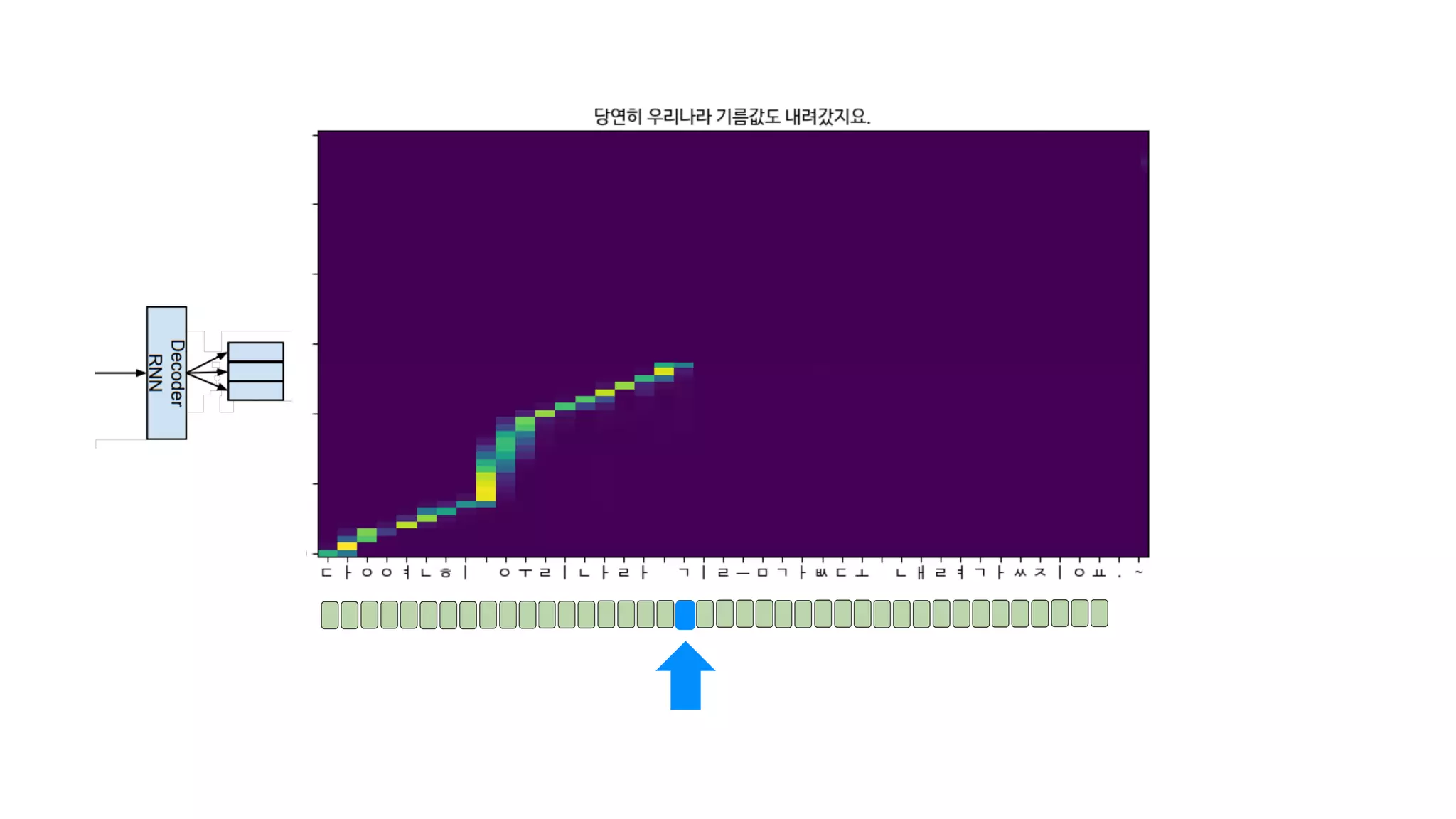
- 121. 공백을 보고 몇 초간 쉼
- 122. 또 다른 공백
- 123. Attention이 중요한 이유?
- 124. 일반화 Generalization
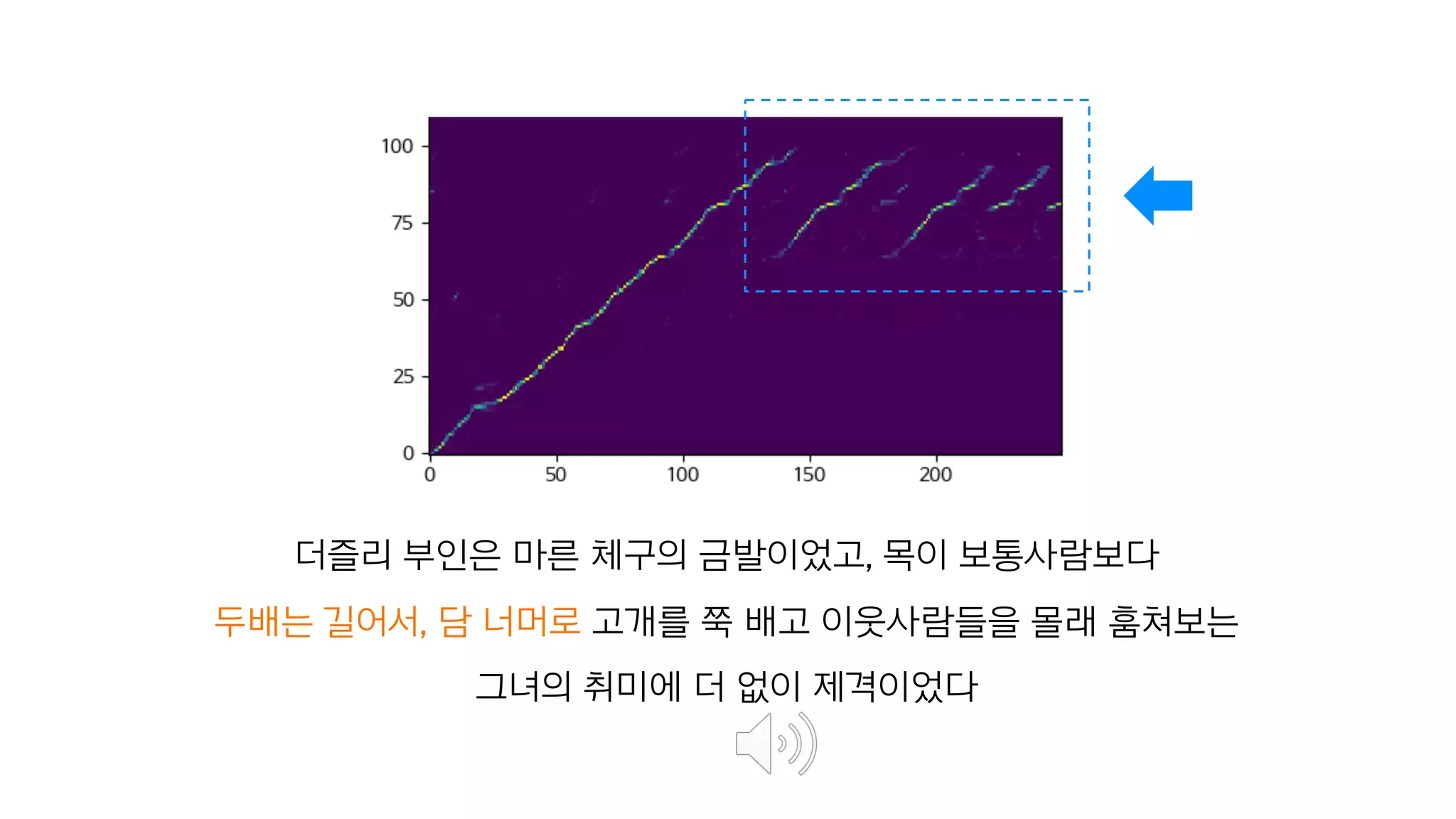
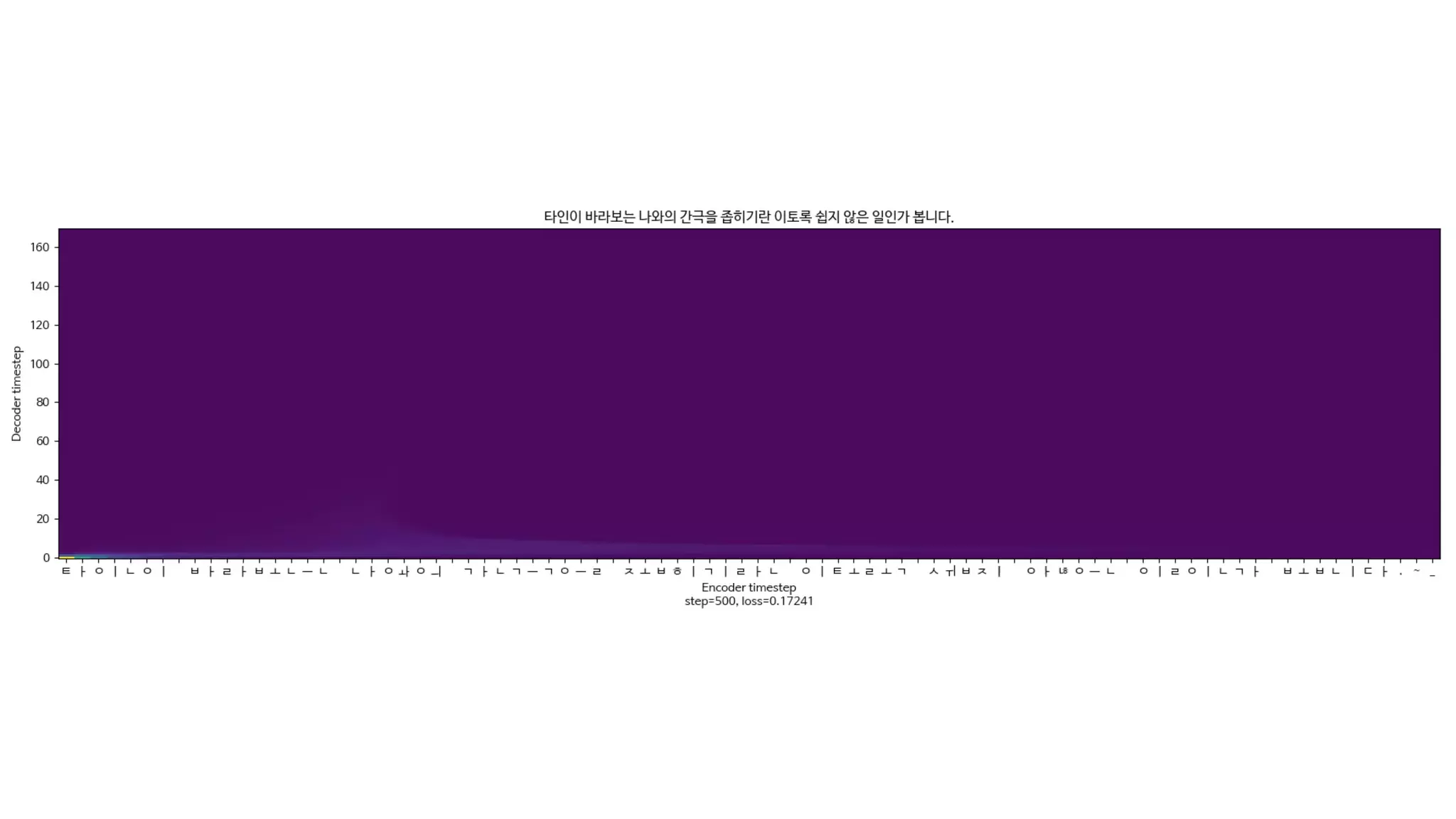
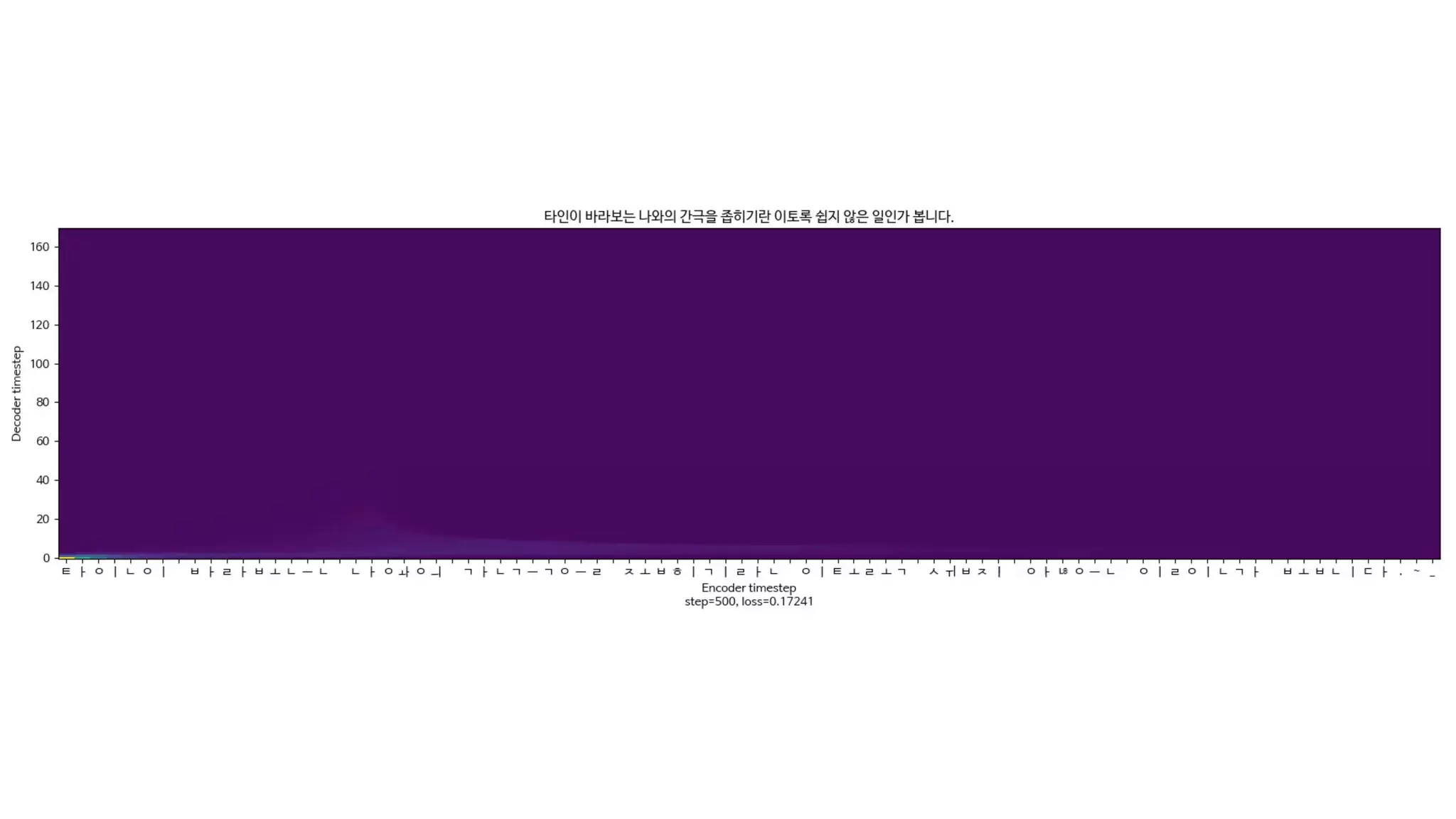
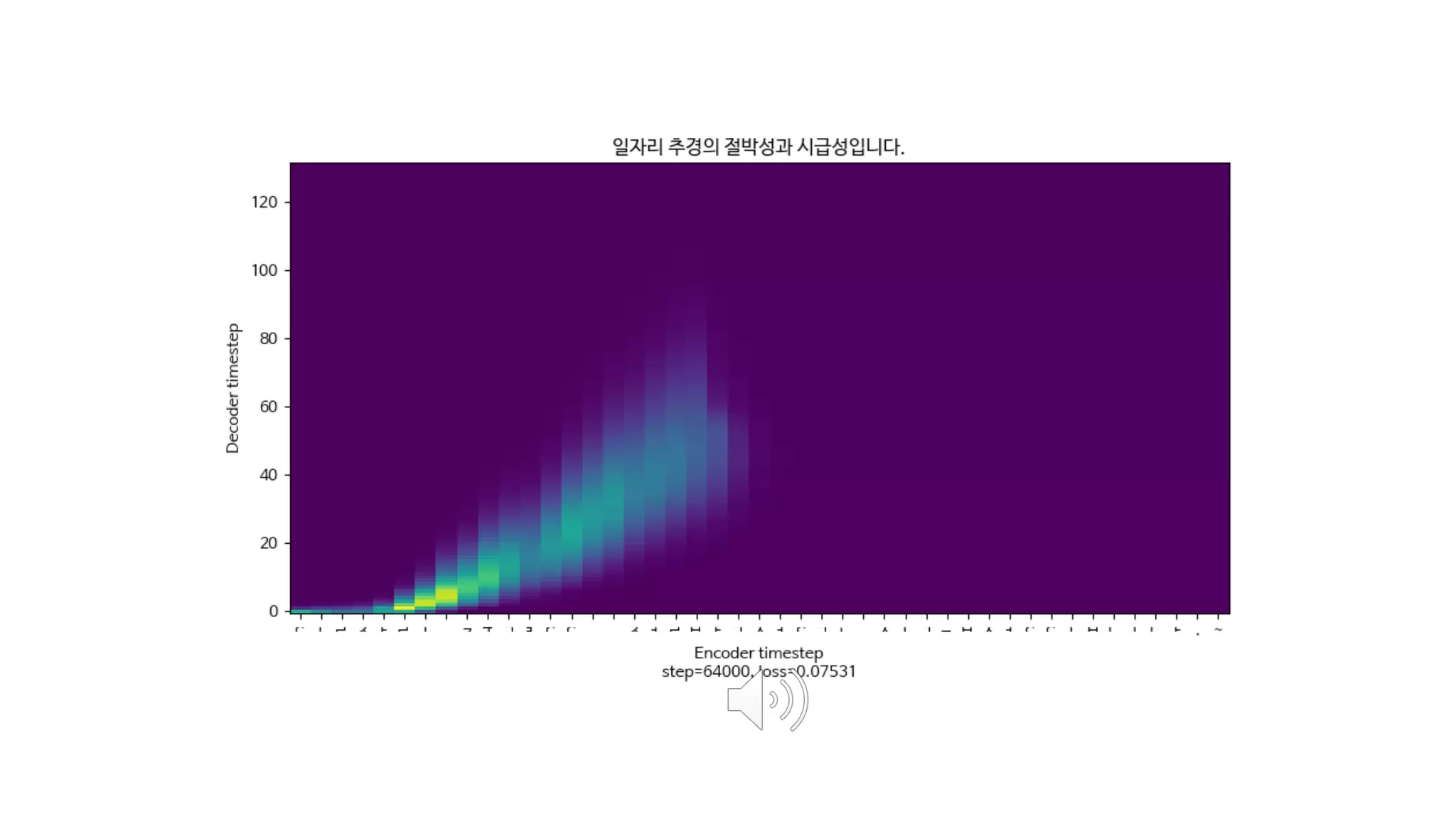
- 125. 학습하지 않았던 문장도 얼마나 잘 말할 수 있는가? 음성 합성 모델의 핵심
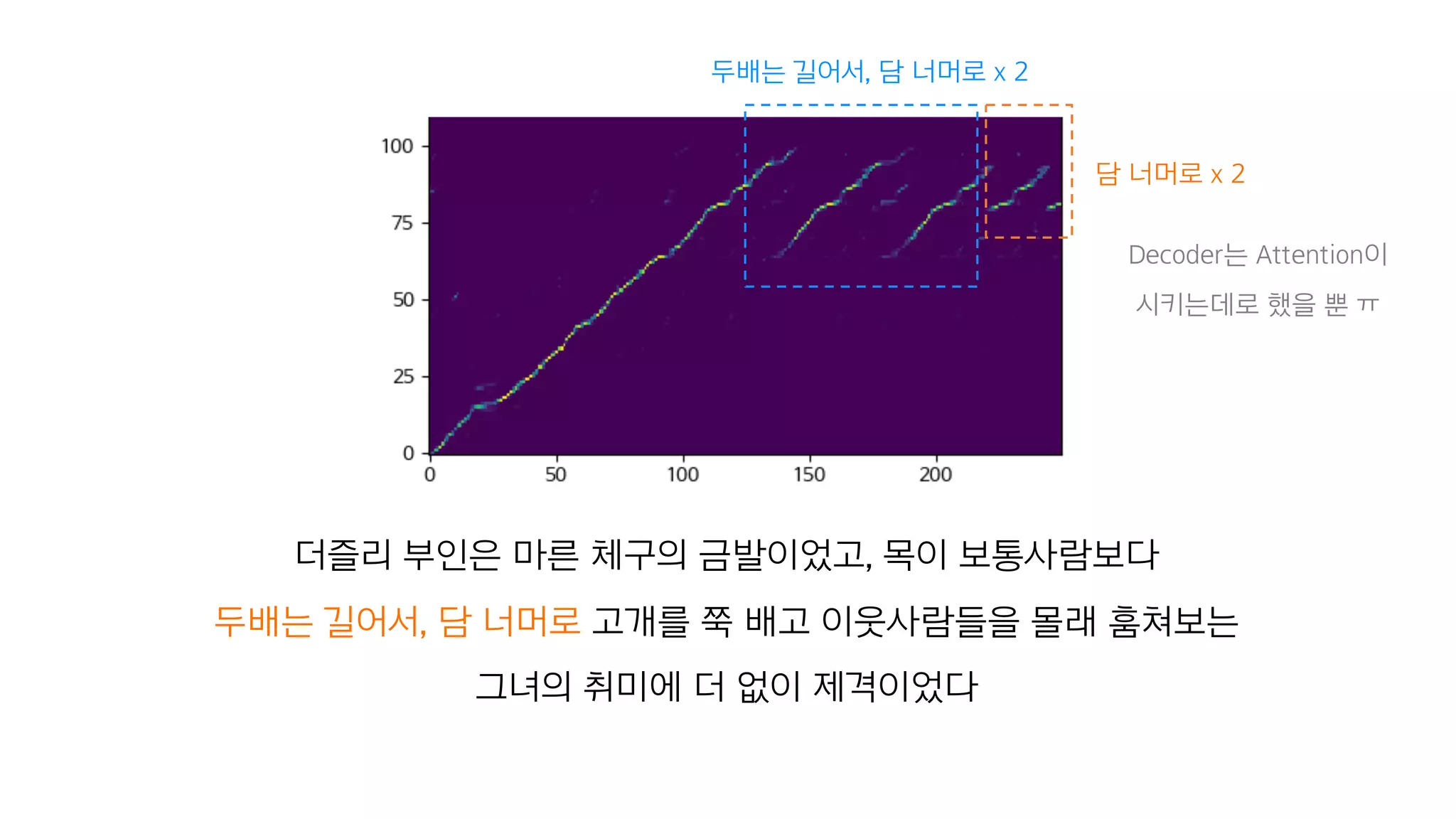
- 126. 더즐리 부인은 마른 체구의 금발이었고, 목이 보통사람보다 두배는 길어서, 담 너머로 고개를 쭉 배고 이웃사람들을 몰래 훔쳐보는 그녀의 취미에 더 없이 제격이었다
- 127. 더즐리 부인은 마른 체구의 금발이었고, 목이 보통사람보다 두배는 길어서, 담 너머로 고개를 쭉 배고 이웃사람들을 몰래 훔쳐보는 그녀의 취미에 더 없이 제격이었다 두배는 길어서, 담 너머로 x 2 담 너머로 x 2 Decoder는 Attention이 시키는데로 했을 뿐 ㅠ
- 128. 손석희는 대한민국의 언론인으로, JTBC 보도 담당 사장이다.
- 129. 제너러티브 어드벌서리얼 네트워크와 베리에셔널 오토 인코더가 핫하다.
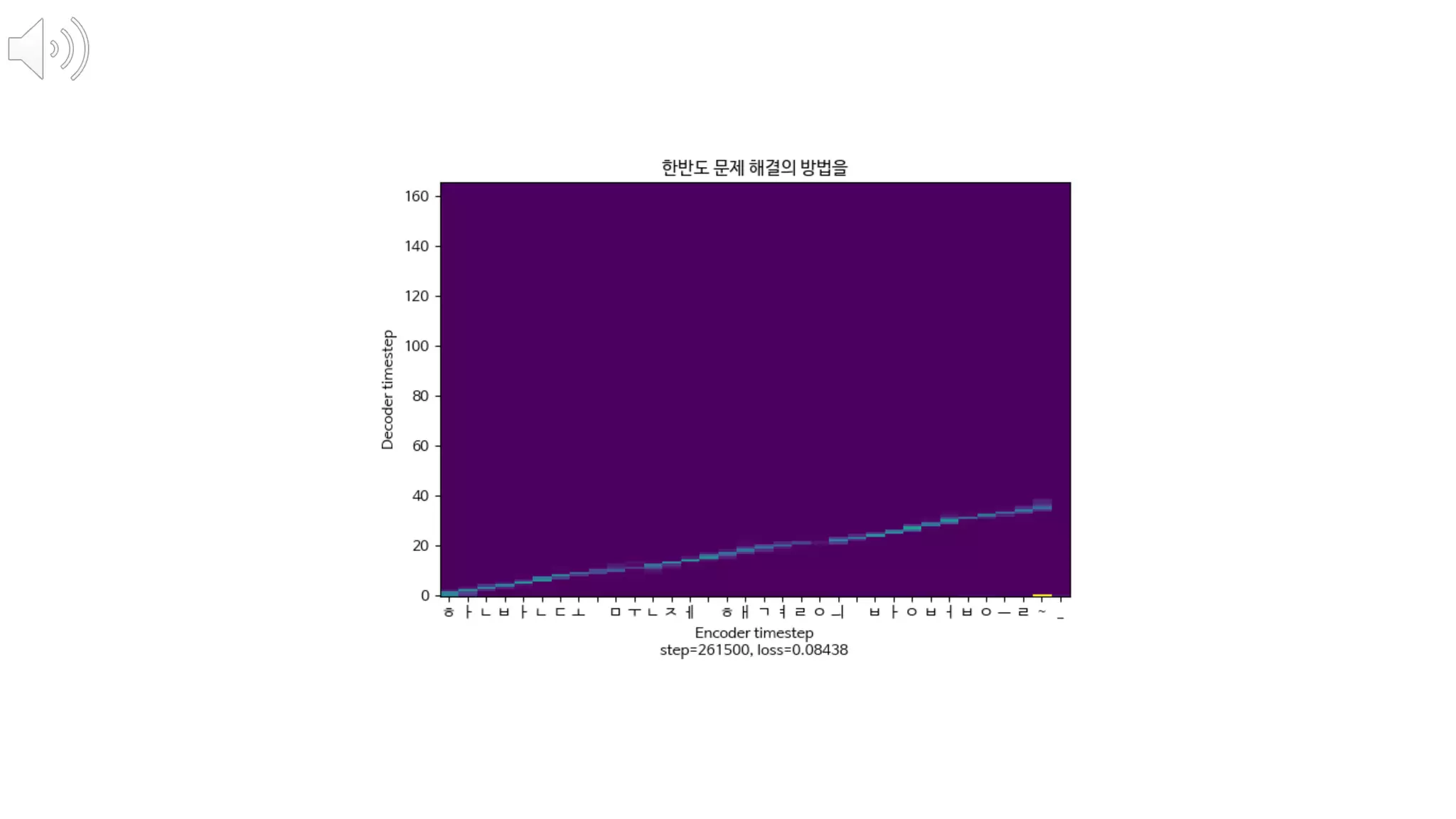
- 130. 오스트랄로피테쿠스 아파렌시스는 멸종된 사람족 종으로, 현재에는 뼈 화석이 발견되어 있다.
- 131. Attention의 학습 과정을 보면
- 132. 네
- 133. Wang, Yuxuan, et al. "Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model." arXiv preprint arXiv:1703.10135 (2017).
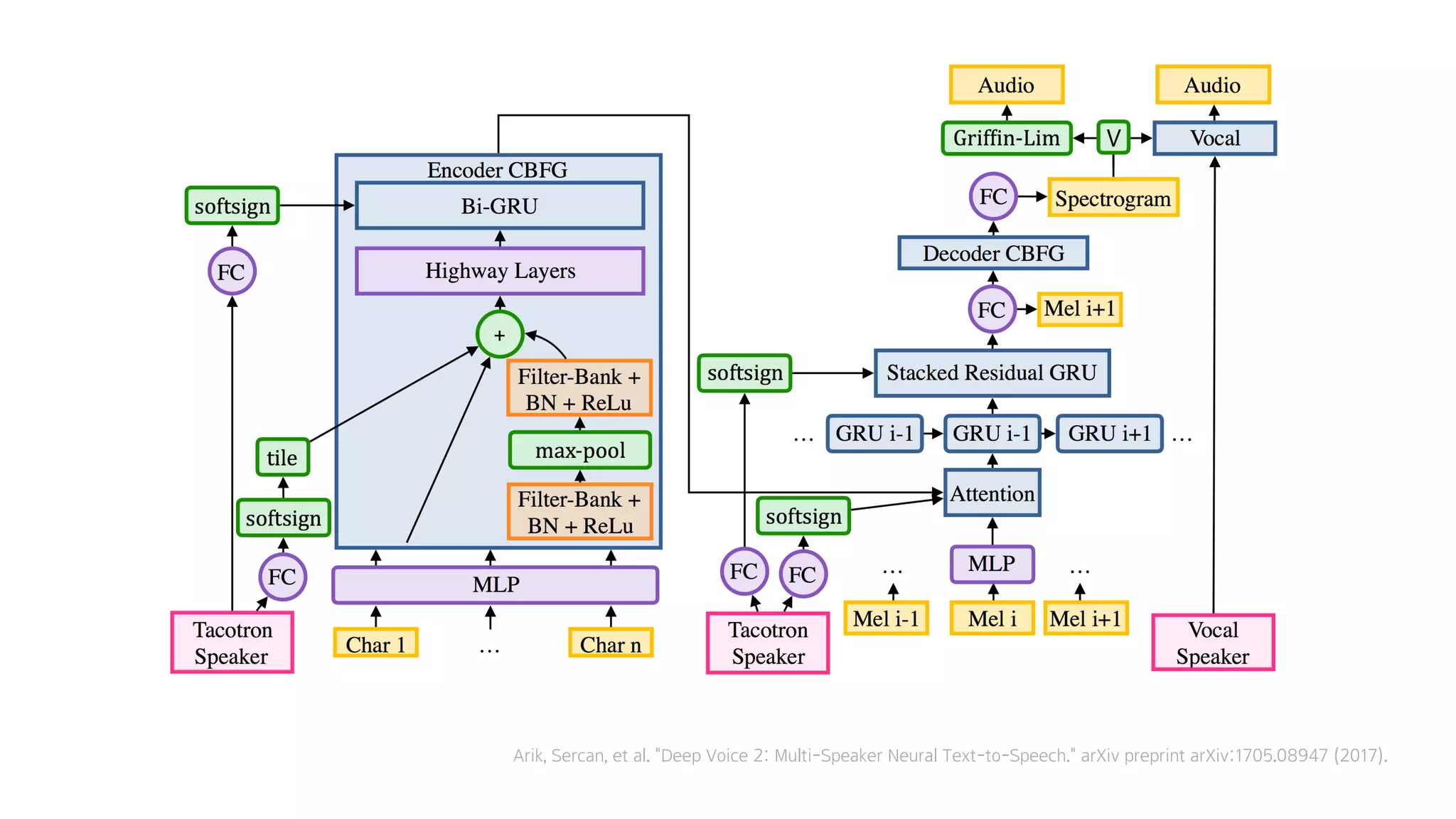
- 134. Embedding Bidirectional-RNN Attention
- 135. 2. Deep Voice 2
- 136. 5달 전
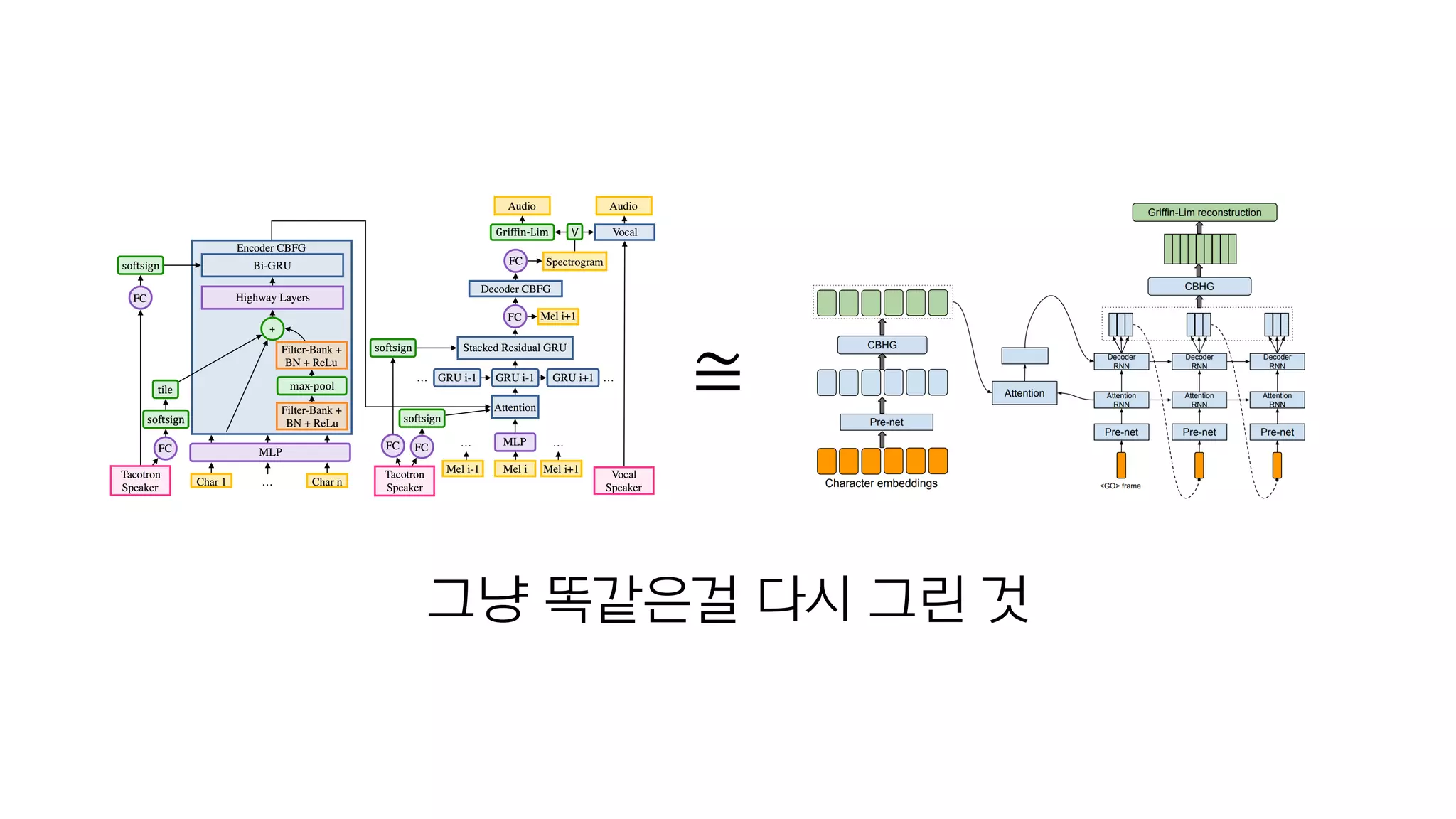
- 137. Arik, Sercan, et al. "Deep Voice 2: Multi-Speaker Neural Text-to-Speech." arXiv preprint arXiv:1705.08947 (2017).
- 138. 그냥 똑같은걸 다시 그린 것 ≅
- 139. 핵심은
- 140. N명의 목소리를 하나의 모델로 Tacotron을 Multi-Speaker 모델로
- 141. Tacotron = 5G GPU GeForce GTX 980 Ti
- 142. 5명의 목소리를 만들고 싶다면?
- 143. 5 × Tacotron = 25 GB GPU 5 × GeForce GTX 980 Ti
- 144. 하지만 N-speaker Tacotron과 함께라면?
- 145. 5-speaker Tacotron ≅ 5G GPU 1 × GeForce GTX 980 Ti
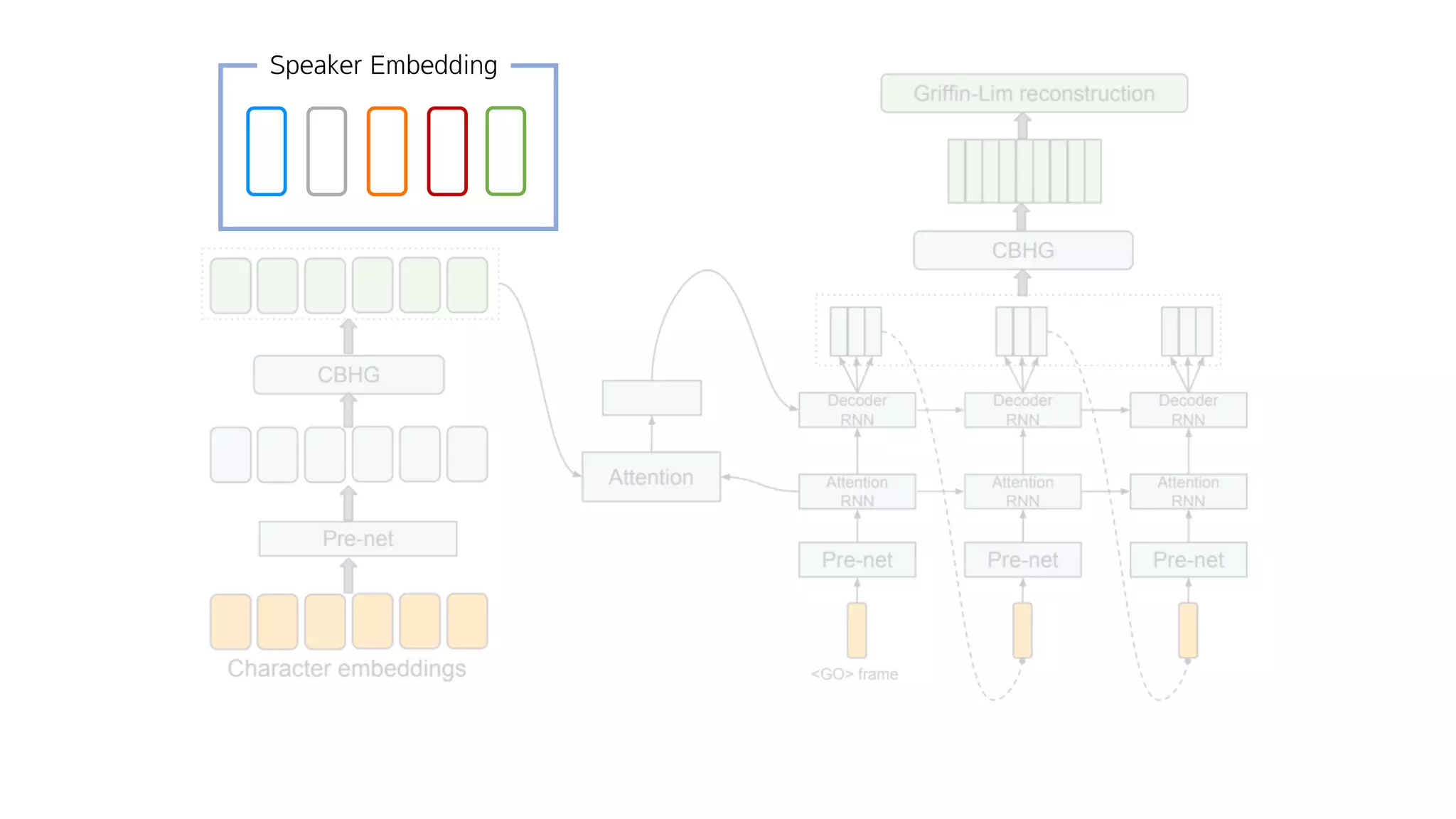
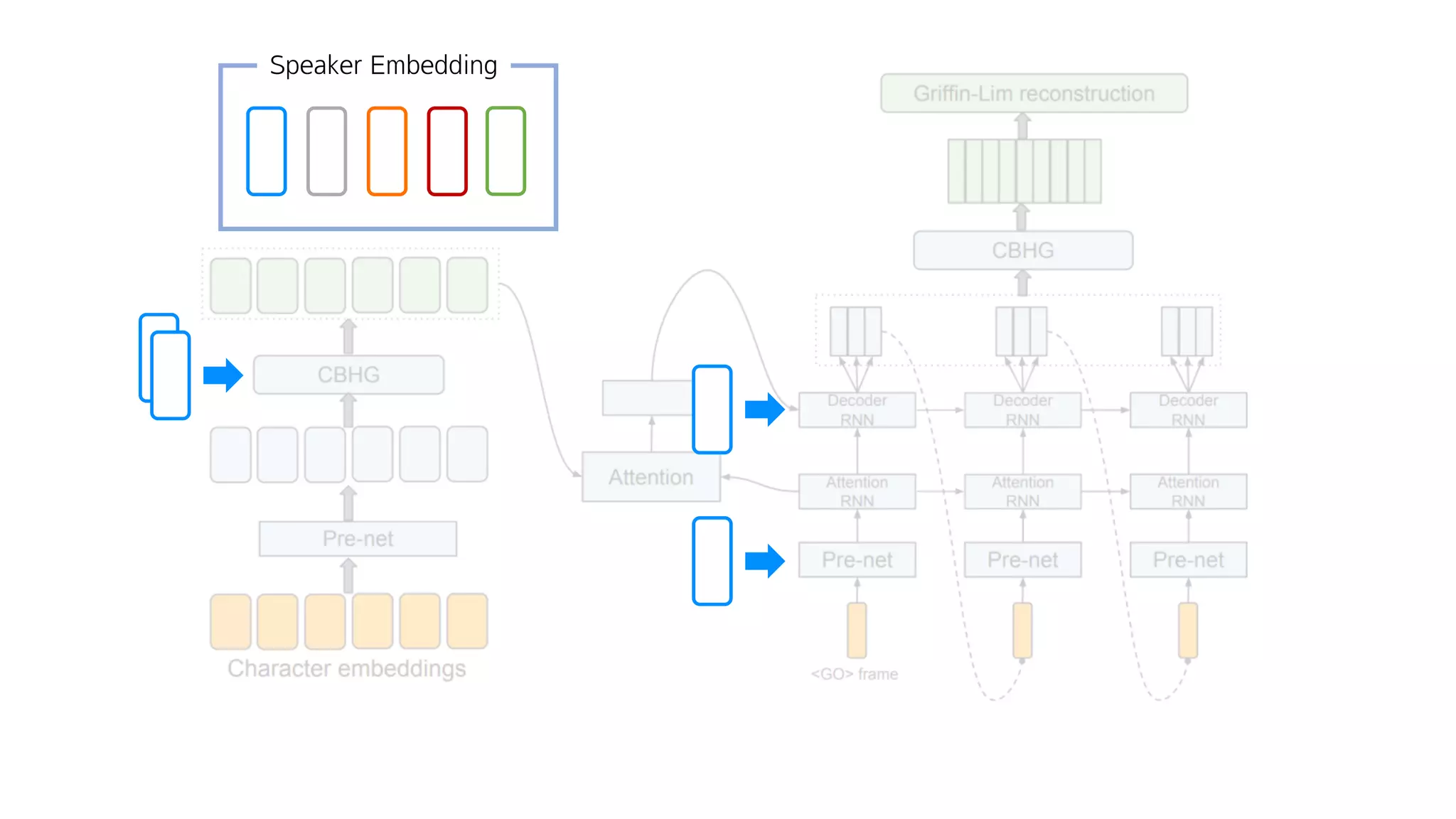
- 146. 어떻게?
- 147. Speaker Embedding
- 148. 0.7 0.5 0.9 0.5 0.3 0.0 0.7 0.5 김태훈 유인나 0.1 0.0 0.3 0.0 손석희 0.9 0.5 0.1 0.1 네이버
- 149. Speaker Embedding
- 150. Speaker Embedding
- 151. Speaker Embedding
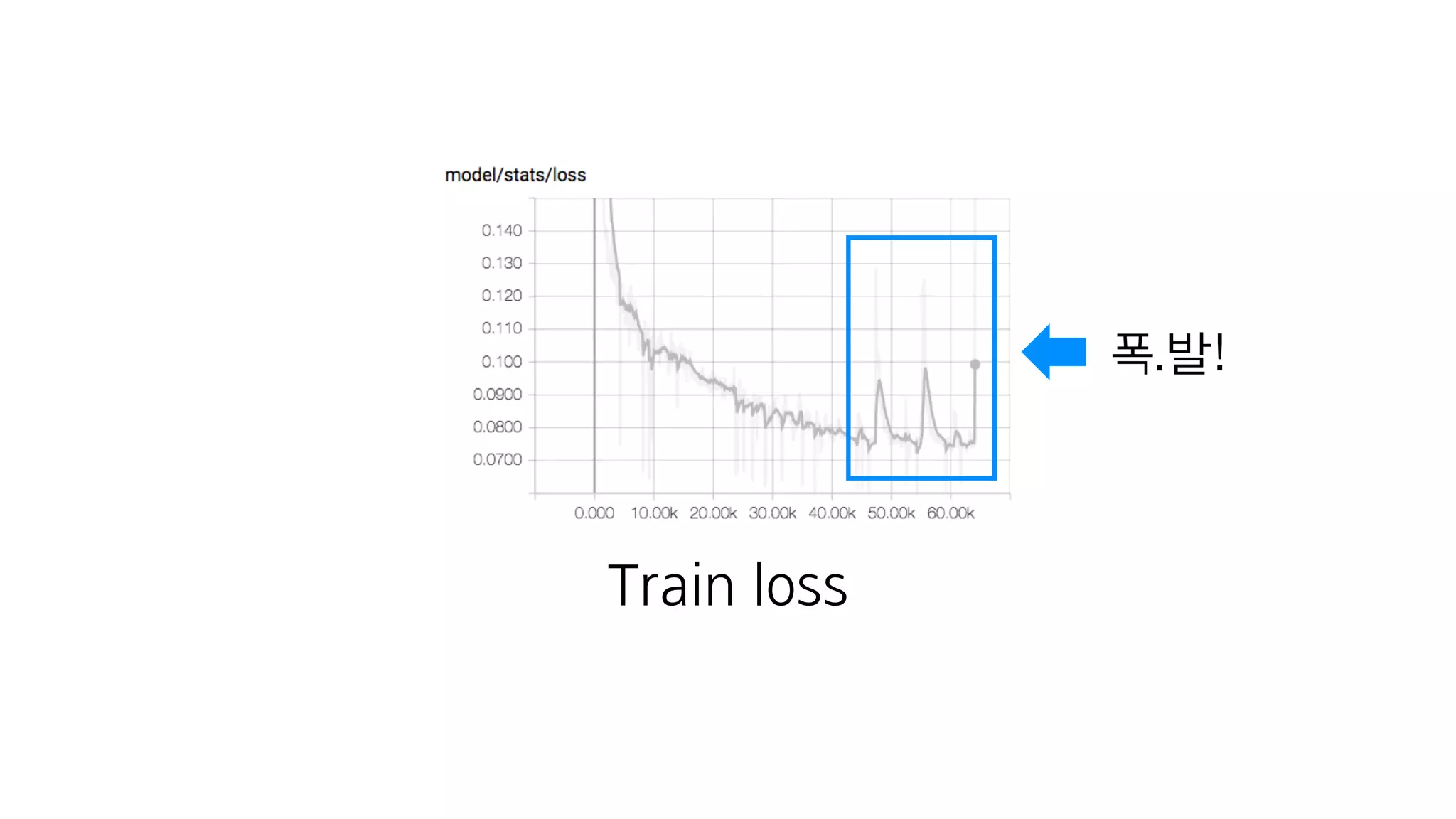
- 152. 또 다른 장점
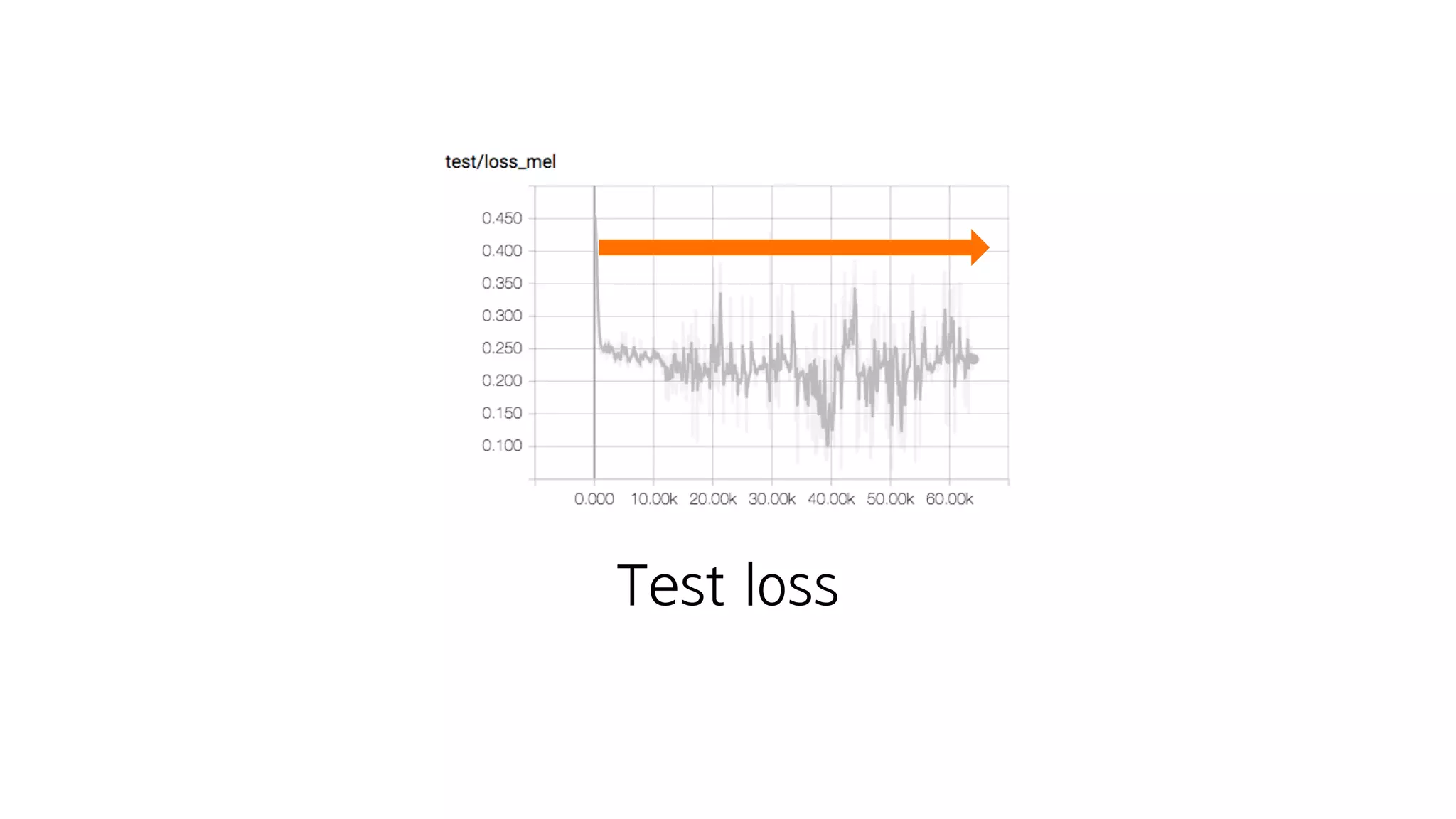
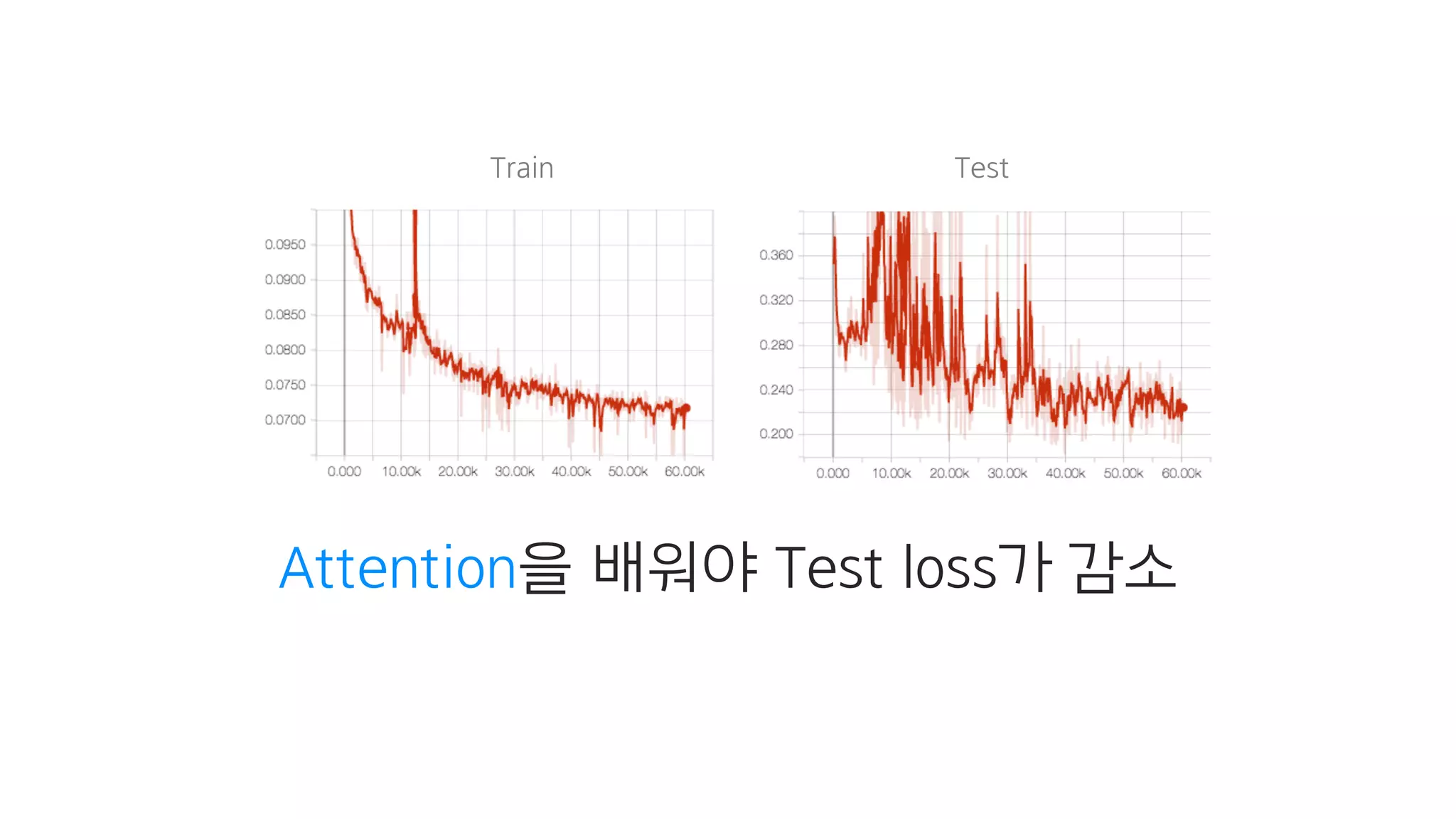
- 153. 문재인 대통령 데이터 학습 집권 기간이 짧으셔서.. 2시간+
- 154. Train loss 폭.발!
- 155. Test loss
- 156. 하지만 다른 데이터와 함께 학습하면?
- 157. Attention을 배워야 Test loss가 감소 TestTrain
- 158. + 완벽하지 않은 데이터완벽한 데이터 학습을 도와준다
- 159. Multi-speaker Attention
- 160. 목소리 C 목소리 D 목소리 A 목소리 B
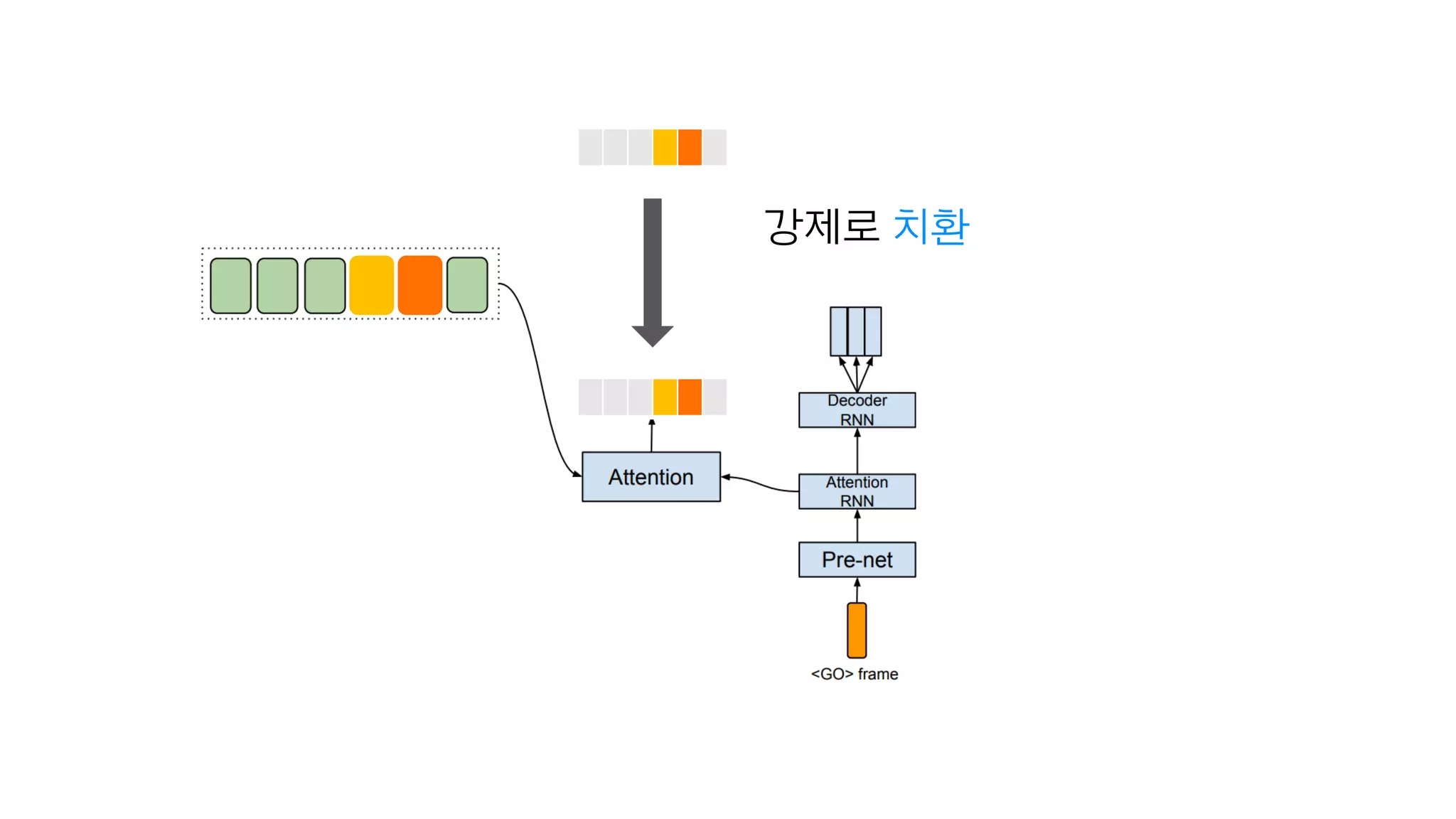
- 161. 목소리 A 목소리 B 목소리 C 목소리 D
- 162. Attention을 원하는 데로 바꿔서
- 163. 내가 원하는 속도로 말하도록 싶을 때
- 164. 직접 만든 Attention
- 165. 강제로 치환
- 166. 한 사람의 Attention을 다른 사람에게
- 167. 앵커 손석희가 문재인 대통령처럼?
- 168. 성대모사?
- 169. 1. 개요 2. 모델 3. 결과
- 170. 오디오북
- 171. 해리 포터와 마법사의 돌 (조앤.K.롤링 저, Pottermore from J.K. Rowling 출판) 발췌
- 172. 해리 포터와 마법사의 돌 (조앤.K.롤링 저, Pottermore from J.K. Rowling 출판) 발췌 그것은 은빛 라이터처럼 보였다.
- 173. 해리 포터와 마법사의 돌 (조앤.K.롤링 저, Pottermore from J.K. Rowling 출판) 발췌 그것은 은빛 라이터처럼 보였다. 그는 뚜껑을 탁 하고 열더니 공중으로 치켜올려 찰깍 소리가 나게 했다.
- 174. 그것은 은빛 라이터처럼 보였다. 그는 뚜껑을 탁 하고 열더니 공중으로 치켜올려 찰깍 소리가 나게 했다. 그러자 조그맣게 펑 하는 소리가 나면서 가장 가까이 있는 가로등이 꺼졌다. 해리 포터와 마법사의 돌 (조앤.K.롤링 저, Pottermore from J.K. Rowling 출판) 발췌
- 175. 박망박박투한 망박박투뭉글 토망희뿌붇날 복볿멍멍북 볻멍벍멍터 한글 프로그래밍 언어
- 176. 그리고,
- 177. 소설가 마크 트웨인이 말했습니다. 인생에 가장 중요한 이틀이 있는데, 하나는 세상에 태어난 날이고 다른 하나는 왜 이 세상에 왔는가를 깨닫는 날이다.
- 178. 소설가 마크 트웨인이 말했습니다. 인생에 가장 중요한 이틀이 있는데, 하나는 세상에 태어난 날이고 다른 하나는 왜 이 세상에 왔는가를 깨닫는 날이다.
- 179. 소설가 마크 트웨인이 말했습니다. 인생에 가장 중요한 이틀이 있는데, 하나는 세상에 태어난 날이고 다른 하나는 왜 이 세상에 왔는가를 깨닫는 날이다.
- 180. 소설가 마크 트웨인이 말했습니다. 인생에 가장 중요한 이틀이 있는데, 하나는 세상에 태어난 날이고 다른 하나는 왜 이 세상에 왔는가를 깨닫는 날이다.
- 181. 소설가 마크 트웨인이 말했습니다. 인생에 가장 중요한 이틀이 있는데, 하나는 세상에 태어난 날이고 다른 하나는 왜 이 세상에 왔는가를 깨닫는 날이다.
- 182. 이것 외에도
- 183. 아. 퇴근하고 싶다. 퇴근하고 싶다. 퇴근하고 싶다.
- 184. 아. 퇴근하고 싶다. 퇴근하고 싶다. 퇴근하고 싶다.
- 185. 아. 퇴근하고 싶다. 퇴근하고 싶다. 퇴근하고 싶다. 시.공.조.아. × 5
- 186. 아. 퇴근하고 싶다. 퇴근하고 싶다. 퇴근하고 싶다. 시.공.조.아. × 5 이겼닭! 오늘 저녁은 치킨이닭!
- 187. 하지만 이런것도..
- 188. ?
- 189. ? 불완전한 학습 데이터 5+시간
- 190. ? 제너러티브 어드벌서리얼 네트워크와 베리에셔널 오토 인코더가 핫하다.
- 191. ? 기회는 평등할 것입니다.
- 192. ? 기회는 평등할 것입니다. 과정은 공정할 것입니다.
- 193. ? 기회는 평등할 것입니다. 과정은 공정할 것입니다. 결과는 정의로울 것입니다.
- 194. 불완전한 학습 데이터 2+시간
- 195. 네이버 웹툰 <선천적 얼간이들> - 가스파드
- 196. 영웅은 죽지않아요.
- 197. 영웅은 죽지않아요. 오늘 당직은 메르시입니다.
- 198. 영웅은 죽지않아요. 오늘 당직은 메르시입니다. 그리고 정마담한테 주려는거 이거 이거, 이거 이거 장짜리 아니여?
- 199. 네
- 200. 직접 듣고 싶다면
- 201. http://carpedm20.github.io/tacotron
- 202. 마지막으로
- 203. 마지막으로
- 204. $ python generate.py "이렇게 만드시면 됩니다"
- 205. 코드 + 미리 학습된 모델 파라미터 + { }음성 추출 + 음성 자르기 + 텍스트 맞추기
- 206. 모두 힘을 모아 유인나 데이터를...
- 207. http://www.devsisters.com/jobs/
- 208. 감사합니다 @carpedm20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
반응형
'IT 둘러보기' 카테고리의 다른 글
| 코로나19로 인해 변화된 우리 시대의 데이터 트랜드 (1) | 2023.03.14 |
|---|---|
| 메타버스 서비스에 Android 개발자가 할 일이 있나요? (1) | 2023.03.13 |
| 스마트폰 위의 딥러닝 (3) | 2023.03.13 |
| 상상을 현실로 만드는, 이미지 생성 모델을 위한 엔지니어링 (1) | 2023.03.13 |
| Material design 3분 만에 살펴보기 (0) | 2023.03.10 |
| 넷플릭스의 문화 : 자유와 책임 (한국어 번역본) (1) | 2023.03.10 |
| 버전관리를 들어본적 없는 사람들을 위한 DVCS - Git (0) | 2023.03.10 |
| 인공지능 시대 규제정책 혁신방안 (1) | 2023.03.09 |